海狸 hvisor 技术手册
v0.5, 2026年4月27日
矽望泛在操作系统社区
https://www.syswonder.org
欢迎使用 hvisor!
hvisor是一款轻量级Type-1虚拟机监控器,使用Rust语言编写,其目标是在异构多核 SoC 平台上提供高效、安全、低开销的虚拟化能力。作为一个直接运行在裸机上的虚拟机监控器,Hvisor 具备快速启动、跨平台支持以及良好的内存安全特性,特别适合嵌入式、边缘计算、车载和工业控制等对性能与安全有严格要求的场景。Hvisor 的设计理念深受 Little.BIG 二元内核架构 启发,通过“轻量内核 + 完整内核”的方式,实现了硬件分区、虚拟化支持与多操作系统并行运行。
特点
- 跨平台支持:支持ARMv8,RISC-V,LoongArch, X86等多种架构。
- 轻量级:专注于核心虚拟化功能,避免了传统虚拟化解决方案中的不必要复杂性,适合资源受限的环境。
- 高效:直接运行在硬件上,无需通过操作系统层,提供接近原生的性能。
- 安全性:Rust语言以其内存安全性和并发编程模型著称,有助于减少内存泄漏、数据竞争等常见的系统级编程错误。
- 快速启动:设计简洁,启动时间短,适合需要快速部署虚拟化的场景。同时具备良好的可移植性,移植过程快捷、周期短。
主要功能
- 虚拟机管理:提供创建、启动、停止和删除虚拟机的基本管理功能。
- 资源分配与隔离:支持对CPU、内存和I/O设备的高效分配和管理,通过虚拟化技术确保不同虚拟机之间的隔离,提升系统安全性和稳定性。
使用场景
- 边缘计算:适合在边缘设备上运行,为IoT和边缘计算场景提供虚拟化支持。
- 开发和测试:开发者可以快速创建和销毁虚拟机环境,用于软件开发和测试。
- 安全研究:提供一个隔离环境,用于安全研究和恶意软件分析。
Little.BIG 架构理念
架构思想
Little.BIG 二元内核架构将系统分为两类核心组件:
- Little Kernel(轻量内核):极简的 Type-1 Hypervisor,运行在裸机上,负责硬件分区与隔离,提供 CPU、内存、I/O 等的最小化虚拟化支持。
- BIG Kernel(大内核):运行在不同 zone 内的完整操作系统内核,如 Linux、RTOS、Unikernel 等,用于承载应用程序和系统服务。
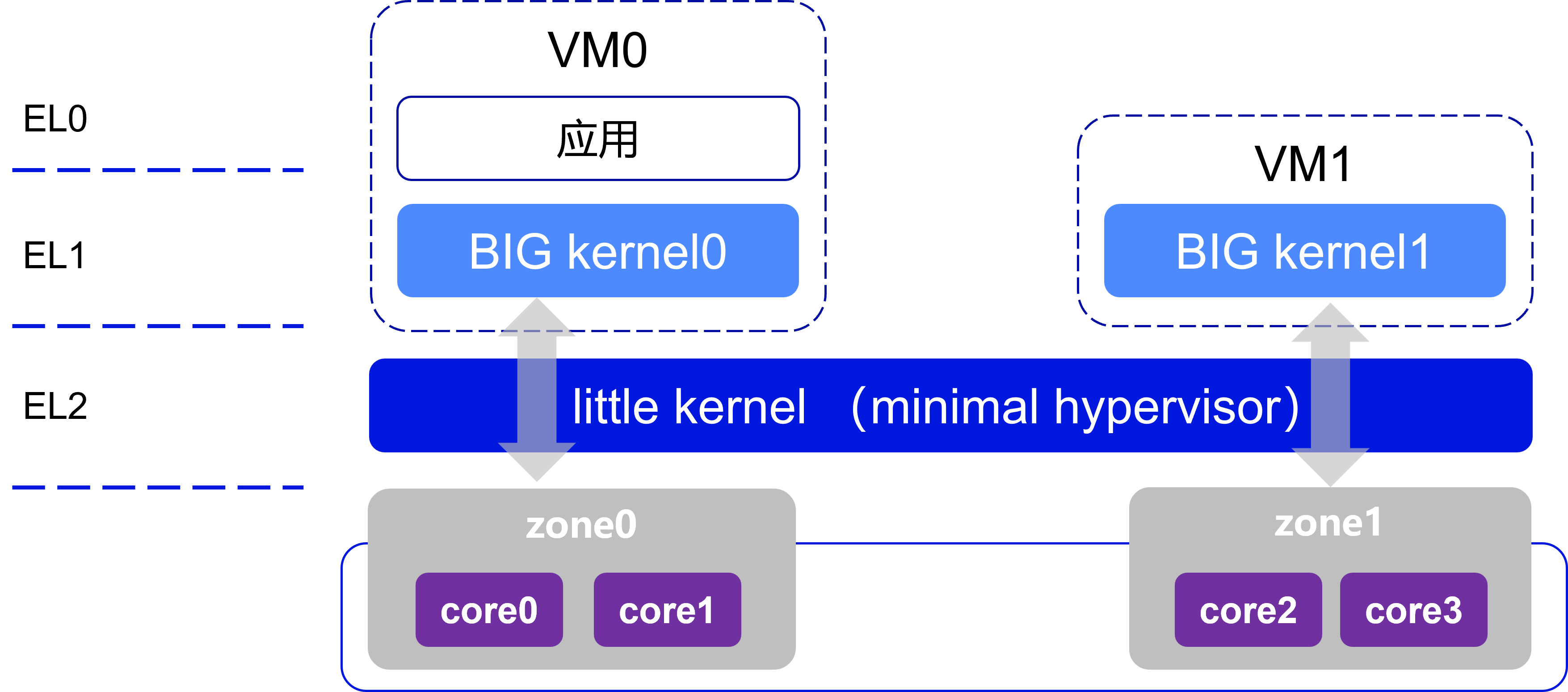
Hvisor 整体架构
Hvisor 作为 Little.BIG 理念的实现,其整体架构分为三层:
-
BIG Kernel 层(Zone 层):在 Little.BIG 架构下,硬件被划分为多个 zone,每个 zone 独立运行自己的 OS 与应用:
zone0:运行 Linux,提供虚拟机管理、设备驱动、VirtIO 后端等。
zoneR:运行 RTOS,通过 xiUOS 库和 VirtIO 驱动支持实时应用。
zoneU:运行 Linux/RuxOS,支持单一应用优化。
-
Little Kernel 层(Hvisor):提供 Hypercall 接口供 BIG kernel 调用。
CPU 虚拟化:Trap 处理、PerCPU 静态分配。
内存虚拟化:MMU 配置、Stage-2 页表映射。
I/O 虚拟化:IOMMU、VirtIO 跳板、PCI 支持。
中断虚拟化:中断控制器模拟与中断注入。
-
硬件层:支持 DMA 与设备直通,提高性能。
异构 SoC 硬件,包括 CPU、DRAM、GPU、FPGA、网卡及 I/O 设备。

hvisor 支持的指令集和处理器
hvisor 目前支持 4 种指令集架构的处理器: ARMv8 aarch64, RISC-V64, LoongArch64, X86_64
hvisor 支持的硬件平台
ARMv8
- QEMU virt aarch64
- NXP i.MX8MP
- Xilinx Ultrascale+ MPSoC ZCU102
- Rockchip RK3588
- Rockchip RK3568
- Forlinx OK6254-C
- 飞腾派(腾珑E2000 )
RISC_V64
- QEMU virt riscv64
- Milk-V Megrez
- Sifive Hifive Premier P550
- FPGA 香山(昆明湖)on S2C Prodigy S7-19PS-2
loongarch64
- Loongson 3A5000+7A2000
- Loongson 3A6000
x86_64
- QEMU q35
- ASUS NUC 14 Essential
hvisor 硬件适配
设计原则
- 代码与板子配置分离:hvisor 本身的
src内部不出现任何platform_xxx相关的cfg。 - 平台独立性:引入之前的 hvisor-deploy 架构,在
platform目录下有序存放各个体系结构和板子的相关信息。 - 板卡目录索引:
- 统一采用
platform/$ARCH/$BOARD作为板卡专用目录。 - 每个板卡的唯一 BID (Board ID) 采用
ARCH/BOARD格式,例如aarch64/qemu-gicv3。
- 统一采用
- 编译简化:支持使用
BID=xxx/xxx直接指定板卡,同时兼容ARCH=xxx BOARD=xxx风格。 - 结构化配置:每个板卡目录包含如下文件:
linker.ld- 链接脚本platform.mk- QEMU 启动 Makefile 及hvisor.bin处理board.rs- 板卡定义 Rust 代码configs/- hvisor-tool 启动 zone 的 JSON 配置cargo/features- 板卡对应的具体cargo features,包括驱动、功能等config.template.toml-.cargo/config的模板,由每个板子自己维护
test/- (可选) QEMU 相关测试代码,包括单元测试、系统测试等image/- 启动文件目录,包含多个子目录:bootloader/- (可选) 用于 QEMU 本地运行和 unittest/systemtest 测试dts/- (可选) zone 0, 1, 2, … 的设备树源文件its/- (可选) 用于 U-Boot FIT image 生成(hvisor aarch64 zcu102)iso/- (可选) 用于 GRUB image 生成(hvisor x86_64)kernel/- (可选) 适用于目标平台的 kernel Imagevirtdisk/- (可选) 虚拟磁盘文件,如 rootfs 等font/- (可选) 在显示器上打印调试日志信息使用的字体
代码实现细节
自动生成 .cargo/config.toml
- 通过
tools/gen_cargo_config.sh生成,确保linker.ld配置动态更新。 config.template.toml采用__ARCH__、__BOARD__等占位符,由gen_cargo_config.sh替换,生成.cargo/config.toml。
build.rs 自动软链接 board.rs
build.rs负责将platform/$ARCH/$BOARD/board.rs软链接到src/platform/__board.rs。- 避免 Makefile 处理,每次构建仅在
env变量变更时触发,减少不必要的全量编译。
通过 Cargo features 选择驱动
- 避免
platform_xxx直接出现在src/,改为基于features进行配置。 cargo/features统一存储板卡驱动、功能等配置。
各板卡对应 features 一览
| BOARD ID | FEATURES |
|---|---|
aarch64/qemu-gicv3 | gicv3 pl011 iommu pci pt_layout_qemu |
aarch64/qemu-gicv2 | gicv2 pl011 iommu pci pt_layout_qemu |
aarch64/imx8mp | gicv3 imx_uart |
aarch64/zcu102 | gicv2 xuartps |
riscv64/qemu-plic | plic |
riscv64/qemu-aia | aia |
loongarch64/ls3a5000 | loongson_chip_7a2000 loongson_uart loongson_cpu_3a5000 |
loongarch64/ls3a6000 | loongson_chip_7a2000 loongson_uart loongson_cpu_3a6000 |
aarch64/rk3588 | gicv3 uart_16550 uart_addr_rk3588 pt_layout_rk |
aarch64/rk3568 | gicv3 uart_16550 uart_addr_rk3568 pt_layout_rk |
x86_64/qemu | pci uart16550a |
x86_64/nuc14mnk | pci uart16550a |
开发与编译指南
编译不同板卡
make ARCH=aarch64 BOARD=qemu-gicv3
make BID=aarch64/qemu-gicv3 # 使用 BID 简写
make BID=aarch64/imx8mp
make BID=loongarch64/ls3a5000
make BID=x86_64/qemu
适配新板卡
- 确定
features:对照已有features归类,添加所需驱动和配置。 - 创建
platform/$ARCH/$BOARD目录:- 添加
linker.ld,board.rs,features等文件。
- 添加
- 编译测试:
make BID=xxx/new_board
features 设计原则
- 最小化层次:
- 例如
cpu-a72而不是board_xxx,以便多个板卡复用。
- 例如
- 明确驱动/功能分类:
irqchip(gicv3,plic, ...)uart(pl011,imx_uart, ...)iommu,pci,pt_layout_xxx, ...
在 QEMU 上运行 hvisor
一、安装交叉编译器 aarch64-none-linux-gnu-10.3
网址:https://developer.arm.com/downloads/-/gnu-a。
工具选择:AArch64 GNU/Linux target(aarch64-none-linux-gnu)。
# 下载交叉编译器并解压
wget https://armkeil.blob.core.windows.net/developer/Files/downloads/gnu-a/10.3-2021.07/binrel/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.xz
tar -xvf gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.xz
# 查看解压后的可执行文件
ls gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/
安装完成,记住路径,例如 /home/tools/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-,之后都会使用这个路径。
二、编译安装 QEMU 9.0.1
注意,QEMU 需要从 7.2.12 换成 9.0.1,以正常使用 PCI 虚拟化。
# 安装编译所需的依赖包
sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \
gawk build-essential bison flex texinfo gperf libtool patchutils bc \
zlib1g-dev libexpat-dev pkg-config libglib2.0-dev libpixman-1-dev libsdl2-dev \
git tmux python3 python3-pip ninja-build
# 下载源码并解压
wget https://download.qemu.org/qemu-9.0.1.tar.xz
tar -xvf qemu-9.0.1.tar.xz
cd qemu-9.0.1
# 生成配置并编译
./configure --enable-kvm --enable-slirp --enable-debug --target-list=aarch64-softmmu,x86_64-softmmu
make -j$(nproc)
之后编辑 ~/.bashrc 文件,在文件的末尾加入几行:
# 请注意,qemu-9.0.1 的父目录可以随着你的实际安装位置灵活调整。另外需要把其放在 $PATH 变量开头。
export PATH="/path/to/qemu-9.0.1/build:$PATH"
随后即可在当前终端 source ~/.bashrc 更新系统路径,或者直接重启一个新的终端。此时可以确认 qemu 版本,如果显示为 qemu-9.0.1,则表示安装成功:
qemu-system-aarch64 --version # 查看版本
注意,上述依赖包可能不全,例如:
- 出现
ERROR: pkg-config binary 'pkg-config' not found时,可以安装pkg-config包;- 出现
ERROR: glib-2.48 gthread-2.0 is required to compile QEMU时,可以安装libglib2.0-dev包;- 出现
ERROR: pixman >= 0.21.8 not present时,可以安装libpixman-1-dev包。
若生成设置文件时遇到报错
ERROR: Dependency "slirp" not found, tried pkgconfig:下载 https://gitlab.freedesktop.org/slirp/libslirp 包,并按 README 安装即可。
三、编译 Linux Kernel 5.4
注意,在最后编译 Linux Kernel 前,需修改默认生成的配置文件。需要启用 CONFIG_BLK_DEV_RAM,以启用 RAM 块设备支持;需要启用 CONFIG_IPV6 和 CONFIG_BRIDGE,以支持在 root linux 中创建网桥和 tap 设备。
交叉编译 Linux Kernel 5.4 生成 root linux 的镜像,用于在 hvisor 中启动 root linux。
# CROSS_COMPILE 路径需要根据第一步安装交叉编译器的路径进行更改
CROSS_COMPILE_PATH="<路径>/bin"
# 下载 linux 5.4 源码
git clone https://github.com/torvalds/linux -b v5.4 --depth=1
cd linux
git checkout v5.4
# 生成默认的编译配置
CROSS_COMPILE_PREFIX=${CROSS_COMPILE_PATH}/aarch64-none-linux-gnu-
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} defconfig
# 启用 CONFIG_BLK_DEV_RAM,以启用 RAM 块设备支持
./scripts/config --enable CONFIG_BLK_DEV_RAM
# 启用 CONFIG_IPV6 和 CONFIG_BRIDGE,以支持在 root linux 中创建网桥和 tap 设备
./scripts/config --enable CONFIG_IPV6
./scripts/config --enable CONFIG_BRIDGE
# 编译
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} Image -j$(nproc)
如果编译 linux 时报错:
/usr/bin/ld: scripts/dtc/dtc-parser.tab.o:(.bss+0x20): multiple definition of `yylloc'; scripts/dtc/dtc-lexer.lex.o:(.bss+0x0): first defined here则修改 linux 文件夹下
scripts/dtc/dtc-lexer.lex.c,在YYLTYPE yylloc;前增加extern。再次编译,发现会报错openssl/bio.h: No such file or directory,此时执行sudo apt install libssl-dev。
编译过程中会出现:
RAM block device support (BLK_DEV_RAM) [Y/n/m/?] y Default number of RAM disks (BLK_DEV_RAM_COUNT) [16] (NEW) Default RAM disk size (kbytes) (BLK_DEV_RAM_SIZE) [4096] (NEW)即配置具体参数,直接回车采用默认值即可。
编译完毕,内核文件位于 arch/arm64/boot/Image。记住整个 linux 文件夹所在的路径,例如 /home/korwylee/lgw/hypervisor/linux,在第七步我们还会用到这个路径。
四、基于 Ubuntu 22.04 arm64 base 构建文件系统
本部分的内容可以省略,直接下载该现成的磁盘镜像使用即可。https://blog.syswonder.org/#/2024/20240415_Virtio_devices_tutorial。
我们使用 Ubuntu 22.04 来构建根文件系统。
Ubuntu 20.04 也可以,但是运行时会报 glibc 版本低的错误,可参考 ARM64-qemu-jailhouse 评论区中的解决办法。
# QEMU 路径,需要根据第二步安装时的路径进行更改
QEMU_PATH="<路径>/build/qemu-system-aarch64"
# 下载 ubuntu base
wget http://cdimage.ubuntu.com/ubuntu-base/releases/22.04/release/ubuntu-base-22.04.5-base-arm64.tar.gz
# 创建 rootfs,用于挂载后续的 rootfs1.img
mkdir -p rootfs
# 创建一个 1 GiB 大小的 rootfs1.img,可以通过修改 count 修改 img 大小
dd if=/dev/zero of=rootfs1.img bs=1M count=1024 oflag=direct
# 格式化为 ext4 文件系统
mkfs.ext4 rootfs1.img
# 挂载 rootfs1.img
sudo mount -t ext4 rootfs1.img rootfs/
# 将 ubuntu.tar.gz 的内容解压到 rootfs
sudo tar -xzf ubuntu-base-22.04.5-base-arm64.tar.gz -C rootfs/
# 让 rootfs 绑定和获取物理机的一些信息和硬件
sudo cp "${QEMU_PATH}" rootfs/usr/bin/
sudo cp /etc/resolv.conf rootfs/etc/resolv.conf
sudo mount -t proc /proc rootfs/proc
sudo mount -t sysfs /sys rootfs/sys
sudo mount -o bind /dev rootfs/dev
sudo mount -o bind /dev/pts rootfs/dev/pts
# 将文件系统切换到 rootfs
sudo chroot rootfs # 执行该指令可能会报错,请参考下面的解决办法
# 在 rootfs 中安装必要的软件包
apt-get update
apt-get install git sudo vim bash-completion \
kmod net-tools iputils-ping resolvconf ntpdate screen
apt-get clean
# 以下由 # 圈住的内容可做可不做
###################
adduser arm64
adduser arm64 sudo
echo "kernel-5_4" > /etc/hostname
echo "127.0.0.1 localhost" > /etc/hosts
echo "127.0.0.1 kernel-5_4" >> /etc/hosts
dpkg-reconfigure resolvconf
dpkg-reconfigure tzdata
###################
# 退出 rootfs
exit
# 卸载 rootfs
sudo umount rootfs/proc
sudo umount rootfs/sys
sudo umount rootfs/dev/pts
sudo umount rootfs/dev
sudo umount rootfs
此时可以顺便创建后续要用到的
rootfs2.img,其大小应适当减少,以便放入rootfs1.img中。# QEMU 路径,需要根据第二步安装时的路径进行更改 QEMU_PATH="<路径>/build/qemu-system-aarch64" # 创建 rootfs2.img,其大小适当减少到 256 MiB dd if=/dev/zero of=rootfs2.img bs=1M count=256 oflag=direct mkfs.ext4 rootfs2.img sudo mount -t ext4 rootfs2.img rootfs/ sudo tar -xzf ubuntu-base-22.04.5-base-arm64.tar.gz -C rootfs/ sudo cp "${QEMU_PATH}" rootfs/usr/bin/ sudo cp /etc/resolv.conf rootfs/etc/resolv.conf sudo mount -t proc /proc rootfs/proc sudo mount -t sysfs /sys rootfs/sys sudo mount -o bind /dev rootfs/dev sudo mount -o bind /dev/pts rootfs/dev/pts sudo umount rootfs/proc sudo umount rootfs/sys sudo umount rootfs/dev/pts sudo umount rootfs/dev sudo umount rootfs
最后卸载挂载,完成根文件系统的制作。
执行
sudo chroot rootfs时,如果报错chroot: failed to run command '/bin/bash': Exec format error,可以执行指令:sudo apt-get install qemu-user-static sudo update-binfmts --enable qemu-aarch64
五、Rust 环境配置
请参考 Rust 语言圣经。
六、编译和运行 hvisor
首先将 hvisor 代码仓库 拉到本地,并切换到 dev 分支。
运行前需要准备好 hvisor 的平台配置文件,具体准备工作包括根文件系统、Linux 内核镜像以及编译对应的设备树文件,现 hvisor 各平台配置文件在仓库的 platform/<架构>/<平台名>/ 路径下,例如本教程将采用的配置文件位于 platform/aarch64/qemu-gicv3/ 路径下。
# 复制根文件系统 rootfs1.ext4
ROOTFS1_PATH="<路径>/rootfs1.img"
mkdir -p platform/aarch64/qemu-gicv3/image/virtdisk
cp "${ROOTFS1_PATH}" platform/aarch64/qemu-gicv3/image/virtdisk/rootfs1.ext4
# 复制 Linux 内核镜像
KERNEL_PATH="<路径>/Image"
mkdir -p platform/aarch64/qemu-gicv3/image/kernel
cp "${KERNEL_PATH}" platform/aarch64/qemu-gicv3/image/kernel/Image
# 编译设备树
make BID=aarch64/qemu-gicv3 dtb
其实建议采用硬链接的方式,以便减轻磁盘空间的占用和方便根文件系统修改时同步。
之后在 hvisor 目录下,执行相应命令即可启动 hvisor。
make BID=aarch64/qemu-gicv3 LOG=info run
执行后会进入 uboot 启动界面,该界面下执行:
bootm 0x40400000 - 0x40000000
该启动命令会从物理地址 0x40400000 启动 hvisor,0x40000000 本质上已无用,但因历史原因仍然保留。hvisor 启动时,会自动启动 root linux(用于管理的 Linux),并进入 root linux 的 shell 界面,root linux 即为 zone0,承担管理工作。
提示缺少
dtc时,可以执行指令:sudo apt install device-tree-compiler
七、使用 hvisor-tool 启动 zone1-linux
首先完成最新版本的 hvisor-tool 的编译。具体请参考 hvisor-tool 的 README。
# Linux 源代码路径,需要根据第三步安装时的路径进行更改
LINUX_PATH="<路径>/linux"
git clone https://github.com/syswonder/hvisor-tool.git
cd hvisor-tool
make all ARCH=arm64 LOG=LOG_INFO KDIR="${LINUX_PATH}"
请务必保证 hvisor 中的 root linux 镜像是由编译 hvisor-tool 时参数选项中的 Linux 源代码目录编译产生。
请务必保证 hvisor-tool 编译时采用的 linux header 版本与 root linux 的 linux header 版本一致,否则 hvisor-tool 的 driver 可能会无法加载。 可以通过使用与第三步中的 root linux 相同的交叉编译工具链进行编译,即使用第一步的交叉编译器路径进行配置。
编译完成后,需要将 hvisor-tool 的可执行文件 tools/hvisor 和内核模块 driver/hvisor.ko 复制到 root linux 的根文件系统中启动 zone1 linux 的目录,例如 /root,再同时将 zone1 的根文件系统、内核镜像、以及编译后的设备树放在同一目录。
具体的文件名需要与 hvisor-tool 配置文件(来自 hvisor 的 platform/aarch64/qemu-gicv3/configs/zone1-linux-virtio.json 和 platform/aarch64/qemu-gicv3/configs/zone1-linux.json)的内容保持一致。
按照 hvisor 提供的配置文件,可执行命令如下。
# 回到创建的 root linux 根文件系统时的目录
LINUX_PATH="<路径>/linux"
HVISOR_PATH="<路径>/hvisor"
HVISOR_TOOL_PATH="<路径>/hvisor-tool"
# 挂载
sudo mount -t ext4 rootfs1.img rootfs/
# 复制 hvisor-tool 的 driver/hvisor.ko 和 tools/hvisor
sudo cp "${HVISOR_TOOL_PATH}/driver/hvisor.ko" rootfs/root/
sudo cp "${HVISOR_TOOL_PATH}/tools/hvisor" rootfs/root/
# 复制 hvisor-tool 的配置文件到 root 路径下
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/configs/zone1-linux-virtio.json" \
rootfs/root/zone1-linux-virtio.json
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/configs/zone1-linux.json" \
rootfs/root/zone1-linux.json
# 复制 zone1 linux 的根文件系统、内核镜像、以及编译后的设备树
sudo cp rootfs2.img \
rootfs/root/rootfs2.ext4
sudo cp "${LINUX_PATH}/arch/arm64/boot/Image" \
rootfs/root/Image
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/image/dts/zone1-linux.dtb" \
rootfs/root/zone1-linux.dtb
# 卸载
sudo umount rootfs
# 如果之前是复制的 rootfs1.img,则还需重新复制一份,命令如下
# 切换到 hvisor 目录
# ROOTFS1_PATH="<路径>/rootfs1.img"
# mkdir -p platform/aarch64/qemu-gicv3/image/virtdisk
# cp "${ROOTFS1_PATH}" platform/aarch64/qemu-gicv3/image/virtdisk/rootfs1.ext4
如果遇到
rootfs1.ext4容量不够,则可以参考 img 扩容 为rootfs1.ext4扩容。
之后在 QEMU 上即可通过 root linux 启动 zone1-linux。具体命令如下。
# 启动 QEMU
make BID=aarch64/qemu-gicv3 LOG=info run
# 启动 root linux
bootm 0x40400000 - 0x40000000
cd root
insmod hvisor.ko
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
rm nohup.out
# 启动 zone1-linux 的 virtio
nohup ./hvisor virtio start zone1-linux-virtio.json &
# 启动 zone1-linux
./hvisor zone start zone1-linux.json && \
cat nohup.out | grep "char device" && \
script /dev/null
启动 zone1-linux 的详细步骤参看 hvisor-tool 的 README 以及 启动示例。
如果显示 virtio 出现 WARNING 或者 ERROR,可以查看
nohup.out查看详细信息,或者使用dmesg命令查看内核日志。
在 Qemu 上运行 hvisor
我们建议在 Ubuntu 上进行实践,以下示例均基于 Ubuntu 发行版。
若你的操作系统为 Windows,你可以使用 WSL 或者 VMware/VirtualBox 虚拟机。
一、安装 Qemu
若你已经拥有合适的 Qemu 可以使用,你可以跳过这一步。
我们建议使用源码编译的 Qemu,这样可以更加灵活地进行版本控制以及修改 Qemu 源码等等。
这里以 Qemu v9.0.2 为例,你也可以选择最新的版本:
# 安装依赖
sudo apt-get install git libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev ninja-build
# 获取 Qemu 源码
wget https://download.qemu.org/qemu-9.0.2.tar.xz
# 解压
tar xvJf qemu-9.0.2.tar.xz
# 进入源码目录
cd qemu-9.0.2
# 配置 riscv target
./configure --target-list=riscv64-softmmu,riscv64-linux-user
# 编译 qemu
make -j$(nproc)
# 测试是否安装成功
./build/qemu-system-riscv64 --version
你可以选择将它安装到环境变量,这样你可以使用 qemu-system-riscv64,而无需显式标明路径。
一种常见的方式是将其安装到 /opt/riscv, 并配置环境变量指向它。
二、安装 riscv 交叉编译器
我们需要用 riscv 交叉编译器来将 Linux 与 OpenSBI 编译成二进制文件,这里选择 https://github.com/riscv-collab/riscv-gnu-toolchain 。
建议从 Github Release 处下载编译好的交叉编译器,这里推荐下载 riscv64-glibc-ubuntu-xxxx-gcc、riscv64-elf-ubuntu-xxxx-gcc 两个压缩包。
一种常见的方式是将其安装到 /opt/riscv, 并配置环境变量指向它。
注意:这里不推荐使用源码编译,因为你可能会遇到各种各样的问题。
三、编译 Linux
如果你要运行 qemu-aia platform,请选择 linux v6.10 及以上版本,低版本的 linux 中不含 aia 的驱动,会导致 linux 无法正常工作。
这里以 linux v6.10 为例:
git clone https://github.com/torvalds/linux -b v6.10 --depth=1
cd linux
git checkout v6.10
make ARCH=riscv CROSS_COMPILE=riscv64-unknown-linux-gnu- defconfig
make ARCH=riscv CROSS_COMPILE=riscv64-unknown-linux-gnu- -j$(nproc)
四、制作 ubuntu 根文件系统
ubuntu 根文件系统包含 apt,可以在后续按需下载需要的软件包,相较于 busybox、buildroot 而言,功能会更加丰富。
这里给出两种方式:
1. 使用自动构建 Ubuntu 根文件系统脚本
参考 https://github.com/LubanCat/ubuntu 。
2. 自制 ubuntu-base 根文件系统
wget http://cdimage.ubuntu.com/ubuntu-base/releases/20.04/release/ubuntu-base-20.04.2-base-riscv64.tar.gz
mkdir rootfs
dd if=/dev/zero of=riscv_rootfs.img bs=1M count=1024 oflag=direct
mkfs.ext4 riscv_rootfs.img
sudo mount -t ext4 riscv_rootfs.img rootfs/
sudo tar -xzf ubuntu-base-20.04.2-base-riscv64.tar.gz -C rootfs/
sudo cp /path-to-qemu/build/qemu-system-riscv64 rootfs/usr/bin/
sudo cp /etc/resolv.conf rootfs/etc/resolv.conf
sudo mount -t proc /proc rootfs/proc
sudo mount -t sysfs /sys rootfs/sys
sudo mount -o bind /dev rootfs/dev
sudo mount -o bind /dev/pts rootfs/dev/pts
sudo chroot rootfs
# chroot 进入 rootfs 后,安装必要的软件包:
apt-get update
apt-get install git sudo vim bash-completion kmod net-tools iputils-ping resolvconf ntpdate
exit
sudo umount rootfs/proc
sudo umount rootfs/sys
sudo umount rootfs/dev/pts
sudo umount rootfs/dev
sudo umount rootfs
五、Rust 环境配置
请参考 Rust 语言圣经。
六、编译运行 hvisor
1. 准备 hvisor 源码和必要文件
将 hvisor 代码仓库 克隆到本地。
git clone https://github.com/syswonder/hvisor.git
在 hvisor/platform/riscv64/{BOARD}/image 文件夹下添加 Linux Image、根文件系统等等。
BOARD 为 qemu-plic, 如果要在 qemu-aia 平台上执行,则将 BOARD 为 qemu-aia。
将之前编译好的根文件系统、Linux 内核镜像分别放在 virtdisk、kernel 目录下,并分别重命名为 rootfs1.ext4、Image,它们在 Makefile 中指定了,你也可以修改 Makefile 中的内容。
2. 编译设备树
# 编译设备树
make BID=riscv64/{BOARD} dtb
3. 编译并运行 hvisor
在 hvisor 目录下,根据需要执行下列命令:
# 对于 qemu-plic board 执行
make run ARCH=riscv64 BOARD=qemu-plic
# 对于 qemu-aia board 执行
make run ARCH=riscv64 BOARD=qemu-aia
注意: Makefile 中的启动命令中包含了 -S 参数,可以看做 Qemu 虚拟机启动时的一个断点,需要 Qemu 收到 continue 才可以继续执行,这时可以方便地查看 /dev/pts/xxx, 可以把它看做是 Qemu 提供的 virtio-console 暴露给 Host 使用的虚拟串口设备。
你可以看到类似以下内容:
char device redirected to /dev/pts/4 (label serial3)
然后,同时按下 ctrl+a, 随后输入 c,回车,即可继续执行,随后会打印 OpenSBI + Hvisor + Linux 的输出信息。
为了使用上述的虚拟串口,你需要新建一个终端,然后可以通过如下命令连接它:
screen /dev/pts/xxx
注意:Qemu 只提供一个物理串口,当启动两个 zone 并且两个 zone 各自占用一个串口时,就需要使用到该虚拟串口设备。
4. 启动 non-root linux
注意:Non-root 使用设备有两种方式,设备直通和 virtio,其中 virtio 设备的后端在 root zone(linux)。
对于 hvisor,我们提供了管理程序 hvisor-tool,具体请参考 hvisor-tool 的 README。
对于 riscv 架构来说,编译 hvisor-tool 时,建议除了上述下载的交叉工具链外,另外使用 ubuntu apt 安装 riscv64-linux-gnu-gcc。
例如,若要编译面向 riscv 架构的命令行工具,且 Hvisor 环境中的 Linux 镜像编译来源的源码位于 ~/linux,则可执行:
make all ARCH=riscv LOG=LOG_INFO KDIR=~/linux
请务必保证 Hvisor 中的 Root Linux 镜像是由编译 hvisor-tool 时参数选项中的 Linux 源码目录编译产生。
编译完成后,将 output/hvisor.ko、output/hvisor 复制到 hvisor/platform/riscv64/{BOARD}/image/virtdisk/rootfs1.ext4 根文件系统中,你可以先将 rootfs1.ext4 挂载后进行拷贝。
再将 zone1 的内核镜像(如果是与 zone0 相同的 Linux 内核,则复制一份 {BOARD}/image/kernel/Image 即可)、设备树({BOARD}/image/dts/linux2.dtb)、配置文件({BOARD}/configs/zone1-linux.json等)拷贝到 rootfs1.ext4 根文件系统中,你可以将它们重命名为 Image、linux2.dtb、linux2.json 等(与 .json 里面的文件名匹配即可)。
除此之外,还需要为 Zone1 linux 制作一个根文件系统。可以将 {BOARD}/image/virtdisk 中的 rootfs1.ext4 复制一份,也可以重新制作根文件系统(最好改小镜像大小),并改名为 riscv_rootfs2.img(和 .json 里面的文件名匹配即可)。之后将 riscv_rootfs2.img 放入 rootfs1.ext4 根文件系统中。
对于 BOARD=qemu-plic,启动 root linux 后,你可以按照如下方式启动 non-root linux:
insmod hvisor.ko
rm nohup.out
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
nohup ./hvisor zone start zone1-linux.json && cat nohup.out | grep "char device" && script /dev/null
对于 BOARD=qemu-aia,启动 root linux 后,你可以按照如下方式启动 non-root linux:
insmod hvisor.ko
mount -t proc proc /proc
mount -t sysfs sysfs /sys
rm nohup.out
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
nohup ./hvisor virtio start zone1-linux-virtio.json &
./hvisor zone start zone1-linux.json && \
cat nohup.out | grep "char device" && \
script /dev/null
注意:它们的区别在于配置不同,你可以修改配置,以自定义使用设备直通还是 virtio,以当前 hvisor 中的默认配置为例:
-
qemu-plic 采用的是直通的设备(尽管启动命令中为 virtio 设备,这里可以看做是直通,因为它由 Qemu 提供设备后端)
-
qemu-aia 采用了 virtio,由 root linux 提供 virtio 设备后端(non-root 的 virtio 驱动会被拦截转发到 root linux 的 virtio 后端)
在 QEMU x86_64 上运行 Hvisor
一、环境准备
硬件
- 具有 Intel CPU 的计算机
- 支持 VT-x,并已在 BIOS 启用
软件
- 使用 Ubuntu 等 Linux 操作系统,以下示例基于 WSL2 Ubuntu 24.04 LTS
二、安装 gcc 编译器
sudo apt update
sudo apt install gcc
三、安装 QEMU
推荐自行编译 QEMU,便于日后修改 QEMU 源码进行调试。此处以 QEMU v9.2.3 为例,也可以安装更新的版本。
# 安装依赖
sudo apt install git libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev \
ninja-build python3-venv bzip2 make
# 获取 QEMU 源码
wget https://download.qemu.org/qemu-9.2.3.tar.xz
# 解压
tar xvJf qemu-9.2.3.tar.xz
# 进入源码目录
cd qemu-9.2.3/
# 生成配置并编译
./configure --enable-kvm --enable-slirp --target-list=x86_64-softmmu
# 编译 qemu
make -j$(nproc)
编辑 ~/.bashrc 文件,在末尾加入:
export PATH="/path/to/qemu-9.2.3/build:$PATH"
随后在终端执行 source ~/.bashrc 更新环境变量,或者重启一个新终端。使用 qemu-system-x86_64 --version 确认当前 QEMU 版本,若为 9.2.3 则安装成功。
四、编译 Linux Kernel
以 Linux v5.19 为例。
# 安装依赖
sudo apt install flex bison libelf-dev libssl-dev
# 下载 linux 5.19 源码
git clone https://github.com/torvalds/linux -b v5.19 --depth=1
cd linux
git checkout v5.19
# 生成默认的编译配置
make ARCH=x86_64 defconfig
# 启用 X2APIC 及其依赖项
./scripts/config --enable CONFIG_X86_X2APIC
./scripts/config --enable CONFIG_ACRN_GUEST
# 启用 RAM 块设备支持
./scripts/config --enable CONFIG_BLK_DEV_RAM
# 启用 IPV6、BRIDGE 和 TUN,以支持在 root linux 中创建网桥和 tap 设备
./scripts/config --enable CONFIG_IPV6
./scripts/config --enable CONFIG_BRIDGE
./scripts/config --enable CONFIG_TUN
# 启用 VIRTIO MMIO,以支持 non-root linux 使用 virtio 驱动
./scripts/config --enable CONFIG_VIRTIO_MMIO
./scripts/config --enable CONFIG_VIRTIO_MMIO_CMDLINE_DEVICES
# 关闭编译期间将警告视为报错
./scripts/config --disable CONFIG_WERROR
# 编译,遇到选项一直 Enter 即可
make ARCH=x86_64 -j$(nproc)
五、基于 Ubuntu 22.04 构建根文件系统
# 下载 Ubuntu 镜像
wget http://cdimage.ubuntu.com/ubuntu-base/releases/22.04/release/ubuntu-base-22.04.5-base-amd64.tar.gz
# 创建 rootfs,用于挂载 rootfs1.img
mkdir -p rootfs
# 创建一个 2G 大小的 ubuntu.img,可以修改 count 修改 img 大小
dd if=/dev/zero of=rootfs1.img bs=1M count=2048 oflag=direct
# 格式化为 ext4 文件系统
mkfs.ext4 rootfs1.img
# 挂载 rootfs1.img
sudo mount -t ext4 rootfs1.img rootfs/
# 将 ubuntu.tar.gz 的内容解压到 rootfs
sudo tar -xzf ubuntu-base-22.04.5-base-amd64.tar.gz -C rootfs/
# 让 rootfs 绑定和获取物理机的一些信息和硬件
sudo cp /etc/resolv.conf rootfs/etc/resolv.conf
sudo mount -t proc /proc rootfs/proc
sudo mount -t sysfs /sys rootfs/sys
sudo mount -o bind /dev rootfs/dev
sudo mount -o bind /dev/pts rootfs/dev/pts
# 将文件系统切换到 rootfs
sudo chroot rootfs
# 在 rootfs 中安装必要的软件包
apt update
apt install git sudo vim bash-completion \
kmod net-tools iputils-ping resolvconf ntpdate screen \
pciutils iproute2 isc-dhcp-client systemd bridge-utils
# 创建进入根文件系统时执行的 init 脚本,赋予执行权限
touch init
chmod 777 init
# 修改 init 脚本,具体内容如下:
# ======================= init =======================
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mkdir -p /dev/pts
mount -t devpts none /dev/pts
echo
echo "Hello Zone 0!"
echo "This boot took $(cut -d' ' -f1 /proc/uptime) seconds"
echo
script /dev/null -c "hostname zone0 && su"
# ====================================================
# 退出 rootfs
exit
# 卸载 rootfs
sudo umount rootfs/proc
sudo umount rootfs/sys
sudo umount rootfs/dev/pts
sudo umount rootfs/dev
sudo umount rootfs
六、Rust 环境配置
请参考 Rust 语言圣经。
七、编译并运行 Hvisor,进入 zone0 Linux
# 下载到本地
git clone https://github.com/syswonder/hvisor.git
cd ./hvisor
# 安装依赖
sudo apt install grub-common xorriso grub-efi-amd64 mtools ovmf
# 新建 kernel 文件夹,用于放置 Linux kernel
mkdir -p ./platform/x86_64/qemu/image/kernel
# 将第四步编译的 Linux kernel 复制到 kernel 文件夹
LINUX_PATH="<路径>/linux"
cp "${LINUX_PATH}/arch/x86/boot/setup.bin" ./platform/x86_64/qemu/image/kernel/
cp "${LINUX_PATH}/arch/x86/boot/vmlinux.bin" ./platform/x86_64/qemu/image/kernel/
# 新建 virtdisk 文件夹,用于放置根文件系统
mkdir -p ./platform/x86_64/qemu/image/virtdisk
# 将第五步制作的根文件系统 rootfs1.img 复制到 virtdisk 文件夹
ROOTFS1_PATH="<路径>/rootfs1.img"
cp "${ROOTFS1_PATH}" ./platform/x86_64/qemu/image/virtdisk/
# 运行 Hvisor
make ARCH=x86_64 BOARD=qemu run
请注意
若执行 make BOARD=qemu run 遇到如下报错:
Could not access KVM kernel module: Permission denied
qemu-system-x86_64: -accel kvm: failed to initialize kvm: Permission denied
<p>执行 <code>sudo usermod -a -G kvm 你的用户名</code> 加入 kvm 的用户组,重启终端后再次尝试。</p>
八、使用 hvisor-tool 运行 zone1 Linux
完成最新版本的 hvisor-tool 的编译,具体请参考 hvisor-tool 的 README。
git clone https://github.com/syswonder/hvisor-tool.git
cd hvisor-tool
# KDIR 必须设为第四步编译的 Linux kernel 根目录
make all ARCH=x86_64 LOG=LOG_INFO KDIR=linux根目录
编译完成后,需要将 hvisor-tool 的可执行文件 tools/hvisor 和内核模块 driver/hvisor.ko 复制到 zone0 的根文件系统中的指定位置,例如 /,将 zone1 的根文件系统、内核镜像以及配置文件放在同一目录。具体的文件名需要与 hvisor-tool 配置文件(来自 hvisor-tool 的 examples/qemu-x86_64/virtio_cfg.json 和 examples/qemu-x86_64/zone1_linux.json)的内容保持一致。
LINUX_PATH="<路径>/linux"
HVISOR_PATH="<路径>/hvisor"
HVISOR_TOOL_PATH="<路径>/hvisor-tool"
ROOTFS2_PATH="<路径>/rootfs2.img"
# 回到创建根文件系统时的目录,挂载
sudo mount -t ext4 rootfs1.img rootfs/
# 复制 hvisor-tool 的 driver/hvisor.ko 和 tools/hvisor
sudo cp "${HVISOR_TOOL_PATH}/driver/hvisor.ko" rootfs/hvisor.ko
sudo cp "${HVISOR_TOOL_PATH}/tools/hvisor" rootfs/hvisor
# 复制 zone1 的配置文件到 root 路径下
sudo cp "${HVISOR_TOOL_PATH}/examples/qemu-x86_64/virtio_cfg.json" \
rootfs/virtio_cfg.json
sudo cp "${HVISOR_TOOL_PATH}/examples/qemu-x86_64/zone1_linux.json" \
rootfs/zone1_linux.json
# 复制 zone1 的根文件系统和内核镜像,文件系统的制作见下文,
# 内核镜像可以直接沿用第四步所得
sudo cp "${ROOTFS2_PATH}" \
rootfs/rootfs2.img
sudo cp "${LINUX_PATH}/arch/x86/boot/setup.bin" \
rootfs/setup.bin
sudo cp "${LINUX_PATH}/arch/x86/boot/vmlinux.bin" \
rootfs/vmlinux.bin
# 复制内核跳板,需要 Hvisor 已经编译过一次
sudo cp "${HVISOR_PATH}/platform/x86_64/qemu/image/bootloader/out/boot.bin" \
rootfs/boot.bin
# 修改 init,新增内容如下:
# ======================= init =======================
echo "This boot took $(cut -d' ' -f1 /proc/uptime) seconds"
echo
...
ifconfig eth0 up
dhclient eth0
brctl addbr br0
brctl addif br0 eth0
ifconfig eth0 0
dhclient br0
ip tuntap add dev tap0 mode tap
brctl addif br0 tap0
ip link set dev tap0 up
insmod hvisor.ko
...
script /dev/null -c "hostname zone0 && su"
# ====================================================
# 卸载
sudo umount rootfs
# 需要将新的 rootfs1.img 移动至 Hvisor 中
ROOTFS1_PATH="<路径>/rootfs1.img"
cp "${ROOTFS1_PATH}" ./platform/x86_64/qemu/image/virtdisk/
zone1 根文件系统的制作可以参考第五步,不用安装额外的依赖包。但需要适当缩减容量(例如 1G),使之能够放入 zone0 的根文件系统中。zone1 的 init 脚本内容如下:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mkdir -p /dev/pts
mount -t devpts none /dev/pts
echo
echo "Hello Zone 1!"
echo "This boot took $(cut -d' ' -f1 /proc/uptime) seconds"
echo
ip link set eth0 up
dhclient eth0
script /dev/null -c "hostname zone1 && su"
回到 Hvisor 的根目录,执行下述指令,即可进入 zone1 Linux
# 运行 Hvisor,进行 zone0
make ARCH=x86_64 BOARD=qemu run
# 启动 hvisor-tool virtio 设备
nohup ./hvisor virtio start virtio_cfg.json &
# 启动 zone1
./hvisor zone start ./zone1_linux.json
# 切换到 zone1 的终端,xxx 一般为 1
screen /dev/pts/xxx
在龙芯 3A5000主板(7A2000)上启动 hvisor
第一步:获取 hvisor 源码并进行编译
首先需要安装龙芯新世界 ABI 的 loongarch64-unknown-linux-gnu- 工具链,请从 https://github.com/sunhaiyong1978/CLFS-for-LoongArch/releases/download/8.0/loongarch64-clfs-8.0-cross-tools-gcc-full.tar.xz 下载并解压到本地,然后请将 cross-tools/bin 目录添加到你的 PATH 环境变量中,保证 loongarch64-unknown-linux-gnu-gcc 等工具可以被 shell 直接调用。
然后克隆代码到本地:
git clone https://github.com/enkerewpo/hvisor
make BID=loongarch64/ls3a5000
编译完成后在 target 目录下可以找到 strip 之后的 hvisor.bin 文件。
第二步(不自己编译 buildroot/linux 等):获取 rootfs/内核镜像
请从 https://github.com/enkerewpo/linux-hvisor-loongarch64/releases 下载最新发布的 hvisor 默认龙芯 linux 镜像(包括 root linux kernel+root linux dtb+root linux rootfs,其中 root linux rootfs 中包括 non root linux+nonroot linux dtb+nonroot linux rootfs)。rootfs 中已打包好 nonroot 的启动 json 以及 hvisor-tool、内核模块等。
第二步(自己编译 buildroot/linux 等):完整编译 rootfs/内核镜像
如果你需要自己编译,这个流程将会较为复杂,接下来将介绍相关细节:
1. 准备好环境
创建一个工作目录(可选):
mkdir workspace && cd workspace
git clone https://github.com/enkerewpo/hvisor
git clone https://github.com/enkerewpo/buildroot-loongarch64
git clone https://github.com/enkerewpo/linux-hvisor-loongarch64 hvisor-la64-linux
git clone https://github.com/enkerewpo/hvisor-tool
git clone https://github.com/enkerewpo/hvisor_uefi_packer
2. 准备 buildroot 环境
因为 buildroot 在找不到需要编译的 package 时会从各个地方下载源码压缩包,这里我准备好了一个预下载的镜像:
https://pan.baidu.com/s/1sVPRt0JiExUxFm2QiCL_nA?pwd=la64
下载后将 dl 目录放在 buildroot-loongarch64 根目录即可,或者你也可以不下载,让 buildroot 自动下载(可能会非常慢)。如果你在解压了 dl 目录后发现编译时仍然有软件包需要下载,也是正常现象。
3. 编译 buildroot
cd buildroot-loongarch64
make loongson3a5000_hvisor_defconfig
make menuconfig # 请将 Toolchain/Toolchain path prefix 设置为你本地的 loongarch64 工具链路径和前缀
# 然后选择右下角 save 保存到 .config 文件
make -j$(nproc)
请注意
这个过程可能持续数小时,取决于你的机器性能和网络环境。
编译完成后,在 output/images 中可以找到 rootfs.cpio.gz 文件,请牢记这个文件的路径,这是一个基本的 rootfs。
下一步请手动将这个路径(设为 ROOTFS_CPIO_GZ_PATH)软连接到 hvisor-la64-linux/rootfs/buildroot/rootfs.cpio.gz,该位置存放的 rootfs 文件将通过 ./build nonroot_setup 命令生成一个精简版的 nonroot rootfs。
如果你希望自己制作 root 和 nonroot 的 rootfs,可以不进行这一步,请注意这会导致 make world 流程中无法自动生成 nonroot rootfs。
4. 第一次编译 linux(为后续 make world 做准备)
一些前置知识:
- linux 源码目录内
arch/loongarch/configs为 defconfig 目录,你可以在仓库中找到 root 和 nonroot 分别的 defconfig。 - linux 源码目录内
arch/loongarch/boot/dts为 dts 目录,你可以在仓库中找到 root 和 nonroot 分别的 dts 文件,其中带linux1.dts等字样的文件为通过下面./build zone ...命令使用的以 zone name 为索引来进行 dts 内嵌,linux1,linux2,linux3为默认的三个 nonroot zone name。
cd hvisor-la64-linux
echo "6.11.6" > chosen_root # 选择 linux-6.11.6 目录作为 root linux 的编译源码
echo "6.13.7" > chosen_nonroot # 选择 linux-6.13.7 目录作为 nonroot linux 的编译源码,
# 你也可以选择其他版本例如 6.11.6 git,请保证对应的 linux-{suffix} 目录存在
./build def root/nonroot # 生成默认 root linux 的 defconfig
./build menu root/nonroot # 进入 menuconfig 配置 root linux 的配置
./build kernel root # 编译 root linux
./build zone {type} {name} {entry}
# type=root/nonroot name=zone_name(此name也用于选择对应加载的{zone_name}.dts 文件)
# entry=vmlinux 的 entry 地址,用于 DMA 支持
对于 build 脚本支持的更多命令(例如后文 make world 流程中涉及到的动态修改 linkerscript load addr 以及配置 target output 的 zone name 等功能,请运行 ./build --help 查看)。
请注意,目前仓库的默认 defconfig 均关闭了 initramfs 的 rootfs 内嵌选项,你可能需要检查一下 configs 目录中的 root 和 nonroot defconfig 并按你的需求进行修改(通过 ./build def root/nonroot 命令生成后再运行 ./build menu root/nonroot 进行修改,请注意如果你之后要使用 make world,这里必须保存一次 defconfig ./build save root/nonroot 将 .config 文件保存到 configs 目录下,供后续 make world 使用,因为make world会直接从configs目录下读取 defconfig,如果不运行 save 的话将会导致你的临时 .config 被覆盖)。
请注意,目前仓库的默认 dts 可能不适合你本地的环境,其中对于 UART 节点请根据需要进行修改(例如 3A6000 支持主板背板的 COM1,则你可以 enable COM1 节点并让 zone 使用,或者使用 3A5000 和 3A6000 均支持的主板 DEBUG pin 底座接 UART0 输出)。
请注意
编译内核过程可能持续几十分钟,取决于你的机器性能。
附:如何通过 menuconfig 配置 initramfs 并添加 rootfs:
- 在 hvisor-la64-linux 目录下运行
./build def root/nonroot生成 defconfig,然后运行./build menu root/nonroot进入 menuconfig 配置。 - 在 menuconfig 中找到 General setup 中的
Initial RAM filesystem and RAM disk (initramfs/initrd) support选项,启用。 - 此时会多出一个
Initramfs source file(s)选项,在这里输入你想要添加的 rootfs 路径,例如PATH_TO_ROOTFS/rootfs.cpio.gz。 - 保存退出,然后运行
./build kernel root/nonroot编译内核,运行./build save root/nonroot保存 defconfig 到仓库。
附:如何控制 console 是使用 virtio-console 还是走默认的 UART(UART0、COM1): 请检查或修改你的 root 或 nonroot 的 rootfs,进入 /etc 目录,其中需要有两个关键文件:
inittab文件,对于 root 和 nonroot 的一些示例见 https://github.com/enkerewpo/buildroot-loongarch64/tree/master/board/loongson/ls3a5000/rootfs_ramdisk_overlay/etcprofile文件,你可以在这里控制 shell login 时运行哪些初始化脚本,一个参考:https://github.com/enkerewpo/buildroot-loongarch64/blob/master/board/loongson/ls3a5000/rootfs_ramdisk_overlay/etc/profile- 对于
./build nonroot_setup命令,请参考./build脚本里相关流程,以及HVISOR_LA64_LINUX_DIR/rootfs/nonroot_inittab和HVISOR_LA64_LINUX_DIR/rootfs/nonroot_profile文件,这两个文件将会在构造 trimmed rootfs for nonroot 时,被./build nonroot_setup命令自动替换默认的inittab和profile文件,请注意,仓库中的默认 inittab 配置为挂载到hvc0上,即 nonroot 的 shell 自动 getty 到 virtio-console,在启动 nonroot 时,你将会在串口看到启动 console 的日志,在进入 shell 后串口不再有输出,为正常现象,此时在 root 中 screen 到 nonroot 的 pts 后,你将会看到 nonroot 的 shell 输出并进行交互。
5. 通过 hvisor uefi packer 执行 make world 流程
cd hvisor_uefi_packer
make menuconfig # 生成 .config,你可以参考 configs 目录下的一些示例配置的格式
vim zones.json # 由于 hvisor 暂未支持 iommu,对于 PCIe 设备的 DMA,
# 必须要求 GPA=HPA,所以每一个虚拟机的 vmlinux 编译时会自动修改 load addr 以避免 GPA/HPA 冲突
./make_world # 这个过程将会很慢,请耐心等待
如果你只需要一个 nonroot,请修改 zones.json,添加或删除对应的配置。下面简述标准流程中 make world 会做哪些事情:
- 从你配置好的
.config中读取相关信息:- hvisor 源码路径
HVISOR_SRC_DIR - hvisor-tool 源码路径
HVISOR_TOOL_DIR - buildroot 源码路径
BUILDROOT_DIR - hvisor la64 linux 仓库源码路径
HVISOR_LA64_LINUX_DIR
- hvisor 源码路径
- 读取
HVISOR_LA64_LINUX_DIR/chosen_root和HVISOR_LA64_LINUX_DIR/chosen_nonroot中的内容,分析选取对应源码版本。 - 读取当前目录下的
zones.json文件,获取需要编译的 zone 配置。 - 编译 hvisor-tool(由于内核模块需要对应的源码,这里编译 hvisor-tool 会固定使用前面解析到的 chosen_root 源码作为
KDIR编译内核模块),并把生成的hvisor命令行工具和hvisor.ko内核模块拷贝到BUILDROOT_DIR/rootfs_ramdisk_overlay/tool目录下,此目录将会被 buildroot 下次编译时打包进 rootfs。 - 在
HVISOR_LA64_LINUX_DIR下运行./build nonroot_setup命令,生成 nonroot rootfs(即不包含/toolhvisor 资源目录等文件的一个较为纯净的 nonroot rootfs),请参考前面章节的部分对 buildroot 生成的 rootfs 进行软连接。该命令生成的精简 rootfs 位于HVISOR_LA64_LINUX_DIR/rootfs/nonroot_rootfs.cpio.gz,可供使用。 - 在
HVISOR_LA64_LINUX_DIR下运行./build def nonroot,生成 nonroot linux 的 defconfig。 - 根据
zones.json中的配置,依次编译各个 nonroot zone,并复制到BUILDROOT_DIR/rootfs_ramdisk_overlay/tool/nonroot目录下,此目录将会被 buildroot 下次编译时打包进 rootfs。 - 然后进行一次 buildroot 的编译,前面提到的相关文件均会被打包进
rootfs.cpio.gz文件中。 - 进入
HVISOR_LA64_LINUX_DIR目录,运行./build def root与./build kernel root生成 root linux 的 vmlinux 文件,请在编译后检查HVISOR_LA64_LINUX_DIR/target目录。
至此 make world 流程结束。一些注意事项:
- zones.txt 写好的 zone name 将会最终对应 dts 目录内对应的 {zone name}.dts 文件作为内嵌到 vmlinux 的设备树文件。
- 你可能需要调整相关的 defconfig 和 dts,仓库中的最新文件由于目前仍在开发中不停更新,其可能不适合你的实际需求。
- 如果你希望修改 zone 启动时的 cmdline,请修改对应的设备树中的 bootargs 字段。
如果可以的话,请打开或 unpack 生成的 rootfs.cpio.gz 文件,检查其中是否包含如下结构,如果缺少任何文件,请检查你的编译流程是否正确。
/ # 根目录
├── daemon.sh # 启动 virtio 后端的脚本
├── start.sh # 启动 nonroot 虚拟机的脚本
└── tool/ # hvisor 资源文件夹
├── hvisor # hvisor 命令行工具
├── hvisor.ko # hvisor 内核模块
├── linux*-json # 虚拟机 linux* 启动配置文件
├── linux*-disk.ext4 # 虚拟机 linux* virtio-blk 文件系统镜像
├── virtio_cfg.json # 虚拟机 virtio 配置文件
└── nonroot/ # nonroot 虚拟机 vmlinux.bin 目录
└── vmlinux-*.bin # 虚拟机内核映像文件,以 zone name 为后缀的 bin 是通过 ./build zone 命令得到的
第三步:编译 UEFI 镜像
由于 3A5000 以及之后的 3 系 CPU 的主板均采用 UEFI 启动,所以只能通过 efi 镜像的方法启动 hvisor。
./make_loongarch64 # 读取 .config 中配置的相关路径和信息,生成 BOOTLOONGARCH64.EFI
此时会在 hvisor_uefi_packer 目录下生成 BOOTLOONGARCH64.EFI,将其放在 U 盘的第一个 FAT32 分区的 /EFI/BOOT/BOOTLOONGARCH64.EFI 位置。
请注意
当你自己编译 root 和 nonroot linux 时,请手动 readelf 得到两个 vmlinux 的 entry 地址,并在 board.rs 以及 linux1/2/3.json 中对应写好,否则一定会启动失败,前文中提到的 make_loongarch64 脚本会帮你自动进行这一检查。
第四步:上板启动
3A5000 主板 CPU UART0 连接
请参考下图中的连线将 3A5000 主板的 UART0 连接到你的串口转接器上(CPU UART0 引脚位于 VGA connector 旁边):

其中从左到右(图中三角形标识的一端为 1 号引脚 RX)分别为 RX(1)、TX(2)、GND(3) 三个引脚,分别对应连接到你的 USB 转接器的 TX、RX、GND 引脚上,如图所示:

请注意
请将串口转接器配置为 RS232 电压模式,以及 USB 串口转接器的 TX 接主板 RX、RX 接主板 TX、GND 接主板 GND(可不接地)。
主板开机
主板上电开机,按 F12 进入UEFI Boot Menu,在目录选择 U 盘启动,即可进入 hvisor,然后自动进入 root linux。 如果您接入了 VGA 屏幕,也可以看到启动最开始的一部分 UEFI loader 的日志输出,之后将转为通过 UART0 输出(hvisor 以及 root/nonroot linux 均使用串口进行输入和输出)。
启动 nonroot
启动后在串口端可以看到 hvisor 的 log 以及 root linux 的 bash,输入:
./daemon.sh
./start.sh 1/2/3 # 启动 nonroot,之后请手动运行 screen /dev/pts/0 or 1, 2
# (linux1-pts0, linux2-pts1, linux3-pts2 by default)
之后会自动启动 nonroot(一些相关配置文件位于 root linux 的 /tool 目录内,包括提供给 hvisor-tool 的 nonroot zone 配置 json 以及 virtio 配置 json 文件),启动 nonroot 后在 root linux 终端输入 screen /dev/pts/0 或 screen /dev/pts/1 或 screen /dev/pts/2 (分别对应 linux1-pts0, linux2-pts1, linux3-pts2 三个 pts),你会看到一个打印了 nonroot 字样的 bash 出现,你可以在使用 screen 时按 CTRL+A D 快捷键 detach(请记住显示的 screen session 名称 / ID),此时会返回 root linux,如果希望返回 nonroot linux,则运行
screen -r {刚才的 session 全名或者只输入最前面的 PID}
之后会返回 nonroot linux 的 bash。
在 NUC 14 Essential x86_64 上运行 Hvisor
一、BIOS 设置
NUC14 初始自带一个 BIOS,需要进行相应设置。
完成必要的连线工作后(电源、显示器、路由器),开机,按 F8(可能有所不同)进入 BIOS,打开 Boot 页面,关闭 Secure Boot。此后即可加载自制的镜像。
二、编译 Linux 内核
在 Qemu X86_64 编译内核的基础上,增加下述配置项,然后重新编译:
# nvme 磁盘驱动
./scripts/config --enable CONFIG_NVME_CORE
./scripts/config --enable CONFIG_BLK_DEV_NVME
# vesafb 图形显示器驱动
./scripts/config --enable CONFIG_FB
./scripts/config --enable CONFIG_FB_CMDLINE
./scripts/config --enable CONFIG_FB_VESA
三、制作启动盘
为了测试方便,本文选择一块 U 盘作为 Hvisor 的启动盘,并且在上面安装 GRUB 作为 bootloader。
首先需要对 U 盘进行分区,推荐使用带有图形界面的 Linux 操作系统以及分区工具 GParted。U 盘插入后,会对应到一个设备节点,例如 /dev/sda。在正式开始分区前,确保 U 盘内无重要数据或者已经备份。
打开 GParted,选择 U 盘作为当前盘,然后点击 Device → Create Partition Table... 建立一个 GPT 分区表。如果提示无法建立分区表,需要使用 umount 卸载所有活动分区,然后重新启动 GParted。
建完 GPT 分区表后,新建一个 EFI 分区,该分区必须为 FAT32 格式。然后再新建一个文件系统分区作为 zone0 的根文件系统,分区格式为 EXT4。建立好分区后,点击绿色的 √,正式完成划分。在下图的示例中,FAT32 分区被命名为 /dev/sda1,EXT4 分区被命名为 /dev/sda2。不同环境下的命名可能有所不同,需要留意。
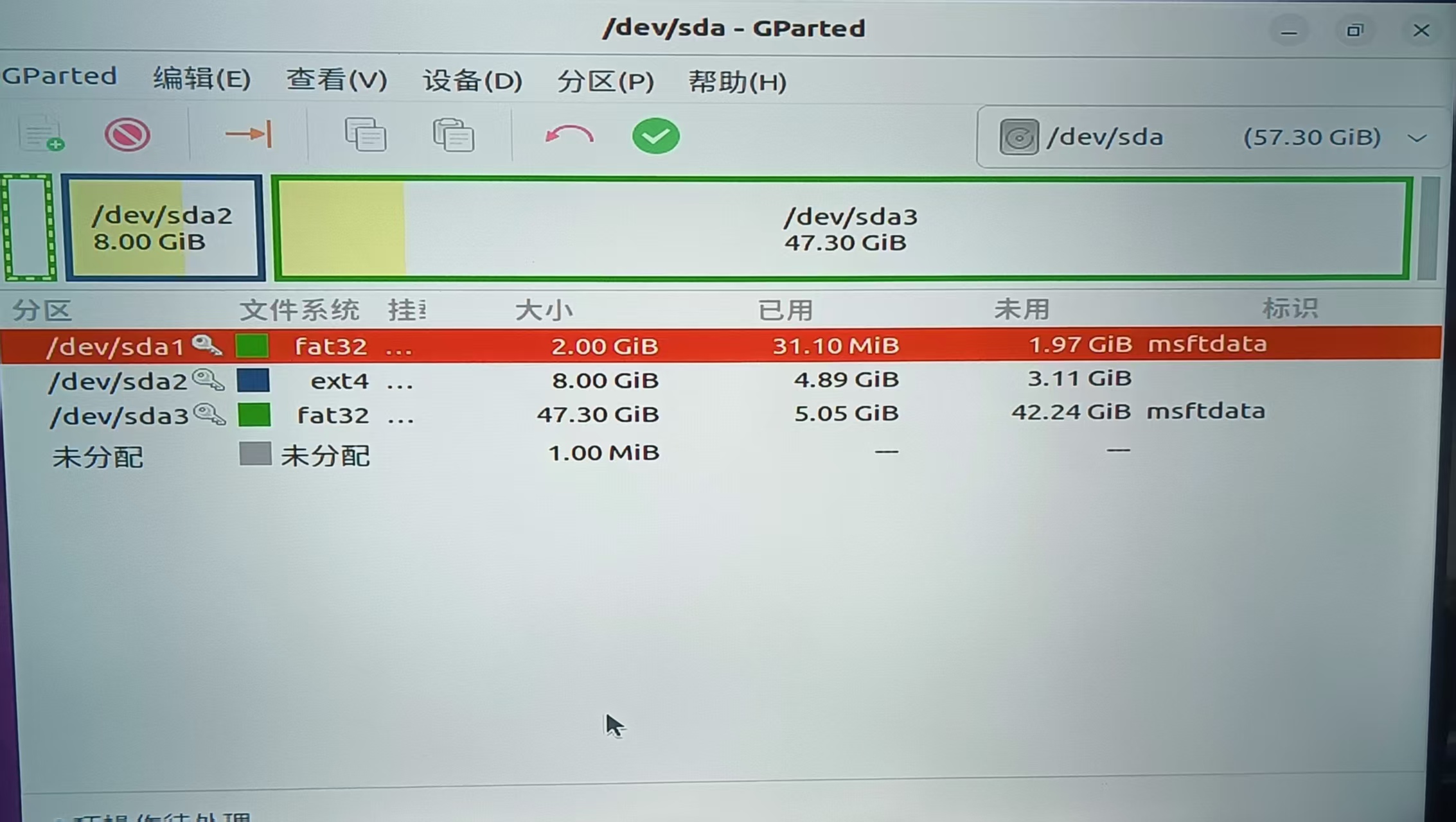
接下来进行 GRUB 的编译。
# 下载 GRUB
wget https://ftp.gnu.org/gnu/grub/grub-2.06.tar.xz
# 解压并打开
tar -xf grub-2.06.tar.xz
cd grub-2.06/
# 配置并编译
mkdir EFI64
cd EFI64
../configure CFLAGS="-Wno-error" --target=x86_64 --with-platform=efi && make -j$(nproc)
然后将 GRUB 安装到 U 盘的 EFI 分区中。
# 将 EFI 分区 mount 到 mnt 文件夹
sudo mount /dev/sda1 /mnt
# 安装到 /mnt
cd ../EFI64/grub-core
sudo ../grub-install -d $PWD --force --removable --no-floppy --target=x86_64-efi --boot-directory=/mnt/boot --efi-directory=/mnt
四、编译 Hvisor
进入 Hvisor 所在路径,打开 platform/x86_64/nuc14mnk/board.rs,将 ROOT_ZONE_CMDLINE 中 root=/dev/sda2 参数修改为 EXT4 分区的名字。
由于 NUC14 未提供串口接口,若要打印调试日志,需要在 platform/x86_64/nuc14mnk/cargo/features 添加 graphics 这一特性,使得日志可以直接绘制在显示器上,这一特性仅供早期调试。
参考 QEMU 的步骤,将构建好的内核文件和根文件系统移动到指定位置。执行编译指令 make ARCH=x86_64 BOARD=nuc14mnk。
可以看到 /platform/x86_64/nuc14mnk/image/iso/boot 路径下有文件生成,将 boot 文件夹整个复制到第三步的 /mnt 中。此时 EFI 分区的大致布局如下:
.
├── boot
│ ├── grub
│ │ ├── fonts
│ │ ├── grub.cfg # 用于配置 GRUB 菜单的各个选项
│ │ ├── grubenv
│ │ ├── locale
│ │ └── x86_64-efi
│ │ ├── acpi.mod
│ │ ├── ...
│ │ └── zstd.mod
│ ├── hvisor
│ └── kernel
│ ├── boot.bin
│ ├── setup.bin
│ └── vmlinux.bin
└── EFI
└── BOOT
└── BOOTX64.EFI
grub.cfg 可以配置 Hvisor 加载时的相关操作,其 menuentry 具体如下。multiboot2 会将 Hvisor 以 Multiboot2 协议加载入内存,module2 会将 Linux 内核镜像加载到内存中,Hvisor 再将其移动到末尾的十六进制数字所指定的内存位置。
menuentry "Hvisor" {
multiboot2 /boot/hvisor # use multiboot spec to boot
module2 /boot/kernel/boot.bin 0
module2 /boot/kernel/boot.bin 5008000
module2 /boot/kernel/setup.bin 500a000
module2 /boot/kernel/vmlinux.bin 5100000
boot
}
最后,将 zone0 的根文件系统通过 sudo dd if=rootfs1.img的路径 of=/dev/sda2 bs=4M status=progress 指令写入 EXT4 分区。
NUC14 开机后,按 F10 进入 U 盘启动模式,选择 U 盘的 EFI 分区。(或者修改 BIOS 将 U 盘作为第一启动项)进入 GRUB 后,选择 Hvisor 即可。
五、有线网卡驱动问题
首先在 Linux 源码文件夹下执行 make modules 以生成 Module.symvers 文件。
Linux 镜像自带的 r8169 驱动可能无法在 NUC14 上运行,导致无法正常联网。因此需要下载 Realtek 官方提供的 r8125 驱动:Realtek PCIe FE / GbE / 2.5GbE / 5G / 10G Family Controller Software,下载 2.5G Ethernet LINUX driver r8125 for kernel up to x.xx 这一项。
下载完成后,进入 src 文件夹,执行 make -C linux所在路径 M=src所在路径 modules,将生成的 r8125.ko 内核模块放入 zone0 的根文件系统的特定位置,例如 /mnt/lib/modules/$(uname -r)/kernel/drivers/net/ethernet/realtek/,然后执行 depmod -a -b /mnt $(uname -r) 更新模块依赖索引。这样在进入 Hvisor 时,就可以执行 sudo modprobe r8125 加载网卡驱动了。
六、无线网卡驱动问题
如果要让 zone0 或 zone1 使用无线网卡,需要给内核添加如下配置项,重新编译:
# iwlwifi 无线网卡驱动
./scripts/config --module CONFIG_IWLWIFI
然后把内核模块安装到 /lib/modules/$(uname -r)。
make -j$(nproc)
make modules
make modules_install INSTALL_MOD_PATH=/path/to/rootfs
这里编译成内核模块,是因为无线网卡驱动在加载时可能需要从 Linux 文件系统中读取固件(firmware)文件。因此要等到文件系统准备完毕,才能进行驱动的初始化。编译成内核模块可以更好地控制驱动初始化的时机。
如果未在 Linux 文件系统中放置合适的固件文件,执行 sudo modprobe iwlwifi 后,可能会显示如下类型的报错。
Direct firmware load for iwlwifi-so-a0-gf-a0-73.ucode failed with error -2
Direct firmware load for iwlwifi-so-a0-gf-a0-72.ucode failed with error -2
Direct firmware load for iwlwifi-so-a0-gf-a0-71.ucode failed with error -2
...
从网上下载 iwlwifi 所需的固件文件,将其移动到 Linux 文件系统的 /lib/firmware 路径下。本示例所需的固件包括 iwlwifi-so-a0-gf-a0.pnvm 以及 iwlwifi-so-a0-gf-a0-72.ucode。
为 Linux 安装依赖:
sudo apt install wpasupplicant udhcpc
修改 init,添加如下内容:
modprobe iwlwifi
# wlan0 是无线网卡对应的接口
ip link set wlan0 up
# 连接 Wifi
wpa_passphrase "你的 Wifi 名称" "你的 Wifi 密码" > /etc/wpa_supplicant.conf
wpa_supplicant -B -i wlan0 -c /etc/wpa_supplicant.conf
# 获取 IP 地址
udhcpc -i wlan0
# 添加 DNS 解析服务器
echo "nameserver 114.114.114.114" > /etc/resolv.conf
echo "nameserver 8.8.8.8" >> /etc/resolv.conf
在NXP-IMX8MP上启动hvisor
1. 下载厂商提供的linux源码
https://pan.baidu.com/s/1XimrhPBQIG5edY4tPN9_pw?pwd=kdtk
提取码:kdtk
进入Linux/源码/目录下,下载OK8MP-linux-sdk.tar.bz2.0*3个压缩包,下载完成后,执行:
cd Linux/sources
# 合并分卷压缩包
cat OK8MP-linux-sdk.tar.bz2.0* > OK8MP-linux-sdk.tar.bz2
# 解压合并的压缩包
tar -xvjf OK8MP-linux-sdk.tar.bz2
解压后,OK8MP-linux-kernel目录就是linux源码目录。
2. linux源码编译
安装交叉编译工具
-
下载交叉编译工具链:
wget https://armkeil.blob.core.windows.net/developer/Files/downloads/gnu-a/10.3-2021.07/binrel/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.xz -
解压工具链:
tar xvf gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.xz -
添加路径,使
aarch64-none-linux-gnu-*可以直接使用,修改~/.bashrc文件:echo 'export PATH=$PWD/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin:$PATH' >> ~/.bashrc source ~/.bashrc
编译linux
-
切换到 Linux 内核源码目录:
cd Linux/sources/OK8MP-linux-sdk -
执行编译命令:
# 设置 Linux 内核配置 make OK8MP-C_defconfig ARCH=arm64 CROSS_COMPILE=aarch64-none-linux-gnu- # 编译 Linux 内核 make ARCH=arm64 CROSS_COMPILE=aarch64-none-linux-gnu- Image -j$(nproc) # 复制编译后的镜像到 tftp 目录 cp arch/arm64/boot/Image ~/tftp/
这里建立一个tftp目录,方便之后对镜像整理,也方便附录中使用tftp传输镜像。
3. 制作sd卡
-
将SD卡插入读卡器,并连接至主机。
-
切换至Linux/Images目录。
-
执行以下命令,进行分区:
fdisk <$DRIVE> d # 删除所有分区 n # 创建新分区 p # 选择主分区 1 # 分区编号为1 16384 # 起始扇区 t # 更改分区类型 83 # 选择Linux文件系统(ext4) w # 保存并退出 -
将启动文件写入SD卡启动盘:
dd if=imx-boot_4G.bin of=<$DRIVE> bs=1K seek=32 conv=fsync -
格式化SD卡启动盘的第一个分区为ext4格式:
mkfs.ext4 <$DRIVE>1 -
将SD卡读卡器拔出,重新连接。将根文件系统rootfs.tar解压到SD卡1号分区,rootfs.tar可以自行参考qemu-aarch64制作,也可以使用下面的镜像。
tar -xvf rootfs.tar -C <path/to/mounted/SD/card/partition>
rootfs.tar下载地址:
https://disk.pku.edu.cn/link/AADFFFE8F568DE4E73BE24F5AED54B00EB
文件名:rootfs.tar
- 完成后,弹出SD卡。
4. 编译hvisor
- 整理配置文件
将配置文件放到该放的地方,配置文件样例可以参考这里。
- 编译hvisor
进入hvisor目录,切换到main分支或dev分支,执行编译命令:
make ARCH=aarch64 FEATURES=platform_imx8mp,gicv3 LOG=info all
# 将编译后的hvisor镜像放入tftp
make cp
5. 启动hvisor和root linux
启动NXP板子之前,需要将tftp目录下的文件放到sd卡,比如放到sd卡的/home/arm64目录下,tftp目录下的文件包括:
- Image:root linux镜像,也可以用作non root linux镜像
- linux1.dtb, linux2.dtb:root linux和non root linux的设备树
- hvisor.bin:hvisor镜像
- OK8MP-C.dtb:这个用于uboot启动时做一些检查,本质没什么用,可以从这里获取OK8MP-C.dts
启动NXP板子:
- 调整拨码开关以启用SD卡启动模式:(1,2,3,4) = (ON,ON,OFF,OFF)。
- 将SD卡插入SD插槽。
- 使用串口线将开发板与主机相连。
- 通过终端软件打开串口
启动NXP板子后,串口应该有输出,重启开发板,立刻按下空格保持不懂,使uboot进入命令行终端,执行如下命令:
setenv loadaddr 0x40400000; setenv fdt_addr 0x40000000; setenv zone0_kernel_addr 0xa0400000; setenv zone0_fdt_addr 0xa0000000; ext4load mmc 1:1 ${loadaddr} /home/arm64/hvisor.bin; ext4load mmc 1:1 ${fdt_addr} /home/arm64/OK8MP-C.dtb; ext4load mmc 1:1 ${zone0_kernel_addr} /home/arm64/Image; ext4load mmc 1:1 ${zone0_fdt_addr} /home/arm64/linux1.dtb; bootm ${loadaddr} - ${fdt_addr};
执行后,hvisor应该就启动并自动进入root linux了。
6. 启动non root linux
启动non root linux需要用到hvisor-tool。具体请参考hvisor-tool的 README。
附. 使用tftp便捷传输镜像
tftp方便开发板与主机间的数据传输,不需要每次插拔sd卡。具体步骤如下:
对于ubuntu系统
如果你使用的是ubuntu系统,则依次执行:
-
安装 TFTP 服务器软件包
sudo apt-get update sudo apt-get install tftpd-hpa tftp-hpa -
配置 TFTP 服务器
创建 TFTP 根目录并设置权限:
mkdir -p ~/tftp sudo chown -R $USER:$USER ~/tftp sudo chmod -R 755 ~/tftp编辑 tftpd-hpa 配置文件:
sudo nano /etc/default/tftpd-hpa修改如下:
# /etc/default/tftpd-hpa TFTP_USERNAME="tftp" TFTP_DIRECTORY="/home/<your-username>/tftp" TFTP_ADDRESS=":69" TFTP_OPTIONS="-l -c -s"将
<your-username>替换为实际用户名。 -
启动/重启 TFTP 服务
sudo systemctl restart tftpd-hpa -
验证 TFTP 服务器
echo "TFTP Server Test" > ~/tftp/testfile.txttftp localhost tftp> get testfile.txt tftp> quit cat testfile.txt若显示 "TFTP Server Test",则 TFTP 服务器工作正常。
-
配置开机启动:
sudo systemctl enable tftpd-hpa -
使用网线将开发板的网口(共有两个,请选择下方的一个)与主机连接。并配置主机有线网卡,ip:192.169.137.2, netmask: 255.255.255.0。
之后启动开发板,进入uboot命令行后,执行命令变为:
setenv serverip 192.169.137.2; setenv ipaddr 192.169.137.3; setenv loadaddr 0x40400000; setenv fdt_addr 0x40000000; setenv zone0_kernel_addr 0xa0400000; setenv zone0_fdt_addr 0xa0000000; tftp ${loadaddr} ${serverip}:hvisor.bin; tftp ${fdt_addr} ${serverip}:OK8MP-C.dtb; tftp ${zone0_kernel_addr} ${serverip}:Image; tftp ${zone0_fdt_addr} ${serverip}:linux1.dtb; bootm ${loadaddr} - ${fdt_addr};
解释:
setenv serverip 192.169.137.2:设置tftp服务器的IP地址。setenv ipaddr 192.169.137.3:设置开发板的IP地址。setenv loadaddr 0x40400000:设置hvisor镜像的加载地址。setenv fdt_addr 0x40000000:设置设备树文件的加载地址。setenv zone0_kernel_addr 0xa0400000:设置guest Linux镜像的加载地址。setenv zone0_fdt_addr 0xa0000000:设置root Linux的设备树文件的加载地址。tftp ${loadaddr} ${serverip}:hvisor.bin:从tftp服务器下载hvisor镜像到hvisor的加载地址。tftp ${fdt_addr} ${serverip}:OK8MP-C.dtb:从tftp服务器下载设备树文件到设备树文件的加载地址。tftp ${zone0_kernel_addr} ${serverip}:Image:从tftp服务器下载guest Linux镜像到guest Linux镜像的加载地址。tftp ${zone0_fdt_addr} ${serverip}:linux1.dtb:从tftp服务器下载root Linux的设备树文件到root Linux的设备树文件的加载地址。bootm ${loadaddr} - ${fdt_addr}:启动hvisor,加载hvisor镜像和设备树文件。
对于windows系统
可以参考这篇文章: https://blog.csdn.net/qq_52192220/article/details/142693036
此目录主要与 ZCU102 相关,介绍如下:
- 如何使用 Qemu 仿真 Xilinx ZynqMP ZCU102
- 如何在 Qemu ZCU102 和 ZCU102 实体开发板上启动 hvisor root linux 和 nonroot linux。
Qemu ZCU102 hvisor 启动
安装 Petalinux
- 安装 Petalinux 2024.1 请注意,本文以 2024.1 为例进行介绍,并不意味着其他版本不可以,只是其他版本未经验证,且测试中发现 Petalinux 对于操作系统有较强的依赖,请安装适合于自己操作系统的对应版本的 Petalinux.
- 将下载好的
petalinux.run文件放置到想要安装到的目录下,为其添加执行权限,之后直接./petalinux.run运行安装程序。 - 安装程序会自动检测所需要的环境,如果不符合则会将缺失的环境提示出来,只需要对其一个个
apt insntall即可。 - 安装完成后每次使用 Petalinux 前需要进入安装目录,手动
source settings.sh来添加环境变量,嫌麻烦将可以将该命令加入到~/.bashrc中
安装 ZCU102 BSP
- 下载对应于 Petalinux 版本的 BSP,例子中是 ZCU102 BSP 2024.1
- 激活 Petalinux 环境,即在 Petalinux 安装目录中
source settings.sh。 - 基于 BSP 创建 Petalinux Project:
petalinux-create -t project -s xilinx-zcu102-v2024.1-05230256.bsp - 此时会创建一个
xilinx-zcu102-2024.1文件夹,其中就有了 QEMU 模拟 ZCU102 所需的参数(设备树),以及预先编译好可以直接上板的 Linux 镜像、设备树、Uboot等。
编译 Hvisor
参照《在 Qemu 上运行 Hvisor》对编译 Hvisor 所需的环境进行配置,之后在 hvisor 目录下,执行:
make ARCH=aarch64 LOG=info BOARD=zcu102 cp
进行编译工作,目录下/target/aarch64-unknown-none(可能不同)/debug/hvisor,即为所需求的 hvisor 镜像。
准备设备树
使用现有设备树
在 Hvisor 的 image/devicetree 目录下,有 zcu102-root-aarch64.dts,其为已经经过测试用来启动RootLinux的设备树文件,对其进行编译即可。
dtc -I dts -O dtb -o zcu102-root-aarch64.dtb zcu102-root-aarch64.dts
如果 dtc 命令无效,则安装 device-tree-compiler。
sudo apt-get install device-tree-compiler
自行准备设备树
如果对设备有定制需求,则建议自行准备设备树,可以反编译 ZCU102 BSP 中的 pre-built/linux/images/system.dtb 获取完整设备树,基于 zcu102-root-aarch64.dts 进行增减。
准备镜像
使用现有镜像
建议直接使用 ZCU102 BSP 中的 pre-built/linux/images/Image 作为 Linux 内核在 ZCU102 上启动,其驱动配置完整。
自行编译
经过测试,linux 源码中 5.15 之前对于 ZYNQMP 的支持不全面,不建议自行编译时使用这之前的版本进行编译,在之后的版本进行编译时可以直接按照一般编译流程进行编译,因为源码对于 ZYNQMP 的基本支持默认开启。具体编译操作如下:
- 访问 linux-xlnx 官网下载 Linux 源码,下载时最好下载
zynqmp-soc-for-v6.3。 tar -xvf zynqmp-soc-for-v6.3解压源码- 进入解压好的目录,执行下述命令使用默认配置,
make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- defconfig - 进行编译:
make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- Image -j$(nproc) - 编译完成后,目录中
arch/arm64/boot/Image即为所需镜像。
启用 QEMU 仿真
- 激活 Petalinux 环境,即在Petalinux 安装目录中
source settings.sh。 - 进入
xilinx-zcu102-2024.1文件夹,使用下述命令即可在 QEMU仿真的 ZCU102上启动 hvisor,其中的文件路径需要按照自己的实际情况进行修改。
# QEMU 参数传递
petalinux-boot --qemu --prebuilt 2 --qemu-args '-device loader,file=hvisor,addr=0x40400000,force-raw=on -device loader,
file=zcu102-root-aarch64.dtb,addr=0x40000000,force-raw=on -device loader,file=zcu102-root-aarch64.dtb,addr=0x04000000,
force-raw=on -device loader,file=/home/hangqi-ren/Image,addr=0x00200000,force-raw=on -drive if=sd,format=raw,index=1,
file=rootfs.ext4'
# 启动 hvisor
bootm 0x40400000 - 0x40000000
Board ZCU102 hvisor 多模式启动
在 ZCU102 开发板 SD mode 下启动 Hvisor
准备 SD 卡
- 准备一块标准 SD 卡,对其进行分区,一块为 Boot 分区(FAT32),其余为文件系统分区(EXT4),windows 分区可以使用 DiskGenius,Linux 分区可以使用 fdisk、mkfs
- 准备一个文件系统,将其内容拷贝到任一文件系统分区中,可以参考 《NXPIMX8》 制作 Ubuntu 文件系统、也可以直接使用 ZCU102 BSP 中的文件系统。
- 将
zcu102-root-aarch64.dtb、Image、hvisor拷贝到 Boot 分区中。 - 在 SD mode 下,需要提供从 SD卡中提供 ATF、Uboot,因此将 ZCU102 BSP 中
pre-built/linux/images/boot.scr 和 BOOT.BIN拷贝到 BOOT 分区中。
启动 ZCU102
- 将 ZCU102 设置为 SD mode,插入 SD 卡,连接串口,上电
- 输入任意按键打断 Uboot 自动脚本执行,运行下述命令启动 hvisor 及 root linux:
fatload mmc 0:1 0x40400000 hvisor;fatload mmc 0:1 0x40000000 zcu102-root-aarch64.dtb
fatload mmc 0:1 0x04000000 zcu102-root-aarch64.dtb;fatload mmc 0:1 0x00200000 Image;bootm 0x40400000 - 0x40000000
- 如果成功启动,将可以在串口看到 hvisor 信息以及 linux 信息,最终进入文件系统。
在 ZCU102 开发板 Jtag mode 下启动 Hvisor
首先将板子附带的两个线缆连接到板子的 JTAG 和 UART 接口上,另一端通过 USB 连接到 PC。
然后在命令行打开一个 petalinux 工程,确保工程已经编译过并生成了对应的启动文件(vmlinux、BOOT.BIN等),之后进入工程根目录运行 [1]:
petalinux-boot --jtag --prebuilt 2
其中 prebuilt 代表启动的层次:
- Level 1: 只下载 FPGA bitstream,启动 FSBL 和 PMUFW
- Level 2: 下载 FPGA bitstream 并启动 UBOOT,并启动 FSBL、PMUFW 和 TF-A(Trusted Firmware-A [2])
- Level 3: 下载并启动 linux,并加载或启动 FPGA bitstream、FSBL、PMUFW、TF-A、UBOOT
之后 JTAG 会通过 JTAG 线把对应的文件下载到板子上(保存到指的内存地址),并启动对应的 bootloader,具体官方的 UBOOT 默认脚本参见工程镜像目录的 boot.scr 文件。
由于 hvisor 需要单独的 UBOOT 命令和自制的 fitImage 启动,请参考 UBOOT FIT 镜像制作、加载与启动。
制作好 fitImage 后,请替换 petalinux images生成目录内的文件(Image.ub),使得 JTAG 加载我们自己制作的 fitImage 到 petalinux 工程配置好的默认 FIT 镜像加载地址,这样 JTAG 启动时会将我们的 fitImage 通过 JTAG 线加载到板子内存对应的地址中,之后再通过 uboot 命令行 extract 和 bootm。
另一个 UART 线可用于以观察 ZCU102 板子的输出(包括 FSBL、UBOOT、linux 等输出),可以通过 screen / gtkterm / termius / minicom 等串口工具查看。
请注意
由于 petalinux 规定了一些固定内存地址,如 linux kernel、fitImage、DTB 的默认加载地址(可在 petalinux 编译工程时配置),由于我们需要加载启动自制的 fitImage,目前发现的问题是如果 root linux dtb 在 its 中所写的加载地址和 petalinux 编译时的加载地址一致,会导致该 dtb 被覆盖为默认的 petalinux dtb,从而导致root linux接受到错误的 dtb 而无法启动。因此需要在编译时指定和 petalinux 默认 dtb/fitImage 加载地址不同的地址,以防止出现其他问题。
参考文献
[1] PetaLinux Tools Documentation: Reference Guide (UG1144).https://docs.amd.com/r/2023.1-English/ug1144-petalinux-tools-reference-guide/Booting-a-PetaLinux-Image-on-Hardware-with-JTAG [2] Trusted Firmware-A Documentation.https://trustedfirmware-a.readthedocs.io/en/latest/
ZCU102 NonRoot 启动
- 使用启动 Root 时所用的 Linux 内核源码编译 hvisor-tool,详细编译流程可以参考 Readme.
- 准备启动 NonRoot 所需要的
virtio_cfg.json和zone1_linux.json,这里可以直接使用 hvisor-tool 目录下的example/zcu102-aarch64,里面的内容已经经过验证,确保可以启动。 - 准备 NonRoot 所需要的 linux 内核 Image,文件系统 rootfs,以及设备树 linux1.dtb。其中的内核和文件系统可以和 Root 一样,Linux1.dtb 则是按需配置,也可以使用 hvisor 目录下的
images/aarch64/devicetree/zcu102-nonroot-aarch64.dts. - 将
hvisor.ko, hvisor, virtio_cfg, zone1_linux.json, linux1.dtb, Image, rootfs.ext4拷贝到 Root Linux 所用的文件系统中。 - 在 RootLinux 输入下述命令启动 NonRoot:
# 加载内核模块
insmod hvisor.ko
# 创建 virtio 设备
nohup ./hvisor virtio start virtio_cfg.json &
# 根据 json 配置文件启动 NonRoot
./hvisor zone start zone1_linux.json
# 查看 NonRoot 的输出,并交互。
screen /dev/pts/0
更多操作细节参考 hvisor-tool Readme
UBOOT FIT 镜像制作、加载与启动
本文介绍 FIT 镜像相关的基本知识,以及如何制作、加载和启动 FIT 镜像。
ITS 源文件
ITS 是 uboot 生成 FIT 镜像(FIT Image)的源码,即 Image Tree Source,其采用 Device Tree Source(DTS)语法格式,可以通过 uboot 提供的工具 mkimage 生成 FIT 镜像。
在 hvisor 的 ZCU102 移植中,使用 FIT 镜像打包 hvisor、root linux、root dtb 等文件到一个 fitImage 中,便于在 QEMU 和实际硬件上启动。
用于 ZCU102 平台的 ITS 文件位于 scripts/zcu102-aarch64-fit.its:
/dts-v1/;
/ {
description = "FIT image for HVISOR with Linux kernel, root filesystem, and DTB";
images {
root_linux {
description = "Linux kernel";
data = /incbin/("__ROOT_LINUX_IMAGE__");
type = "kernel";
arch = "arm64";
os = "linux";
...
};
...
root_dtb {
description = "Device Tree Blob";
data = /incbin/("__ROOT_LINUX_DTB__");
type = "flat_dt";
...
};
hvisor {
description = "Hypervisor";
data = /incbin/("__HVISOR_TMP_PATH__");
type = "kernel";
arch = "arm64";
...
};
};
configurations {
default = "config@1";
config@1 {
description = "default";
kernel = "hvisor";
fdt = "root_dtb";
};
};
};
其中,__ROOT_LINUX_IMAGE__、__ROOT_LINUX_DTB__、__HVISOR_TMP_PATH__将通过 Makefile 内的 sed 命令替换为实际的路径。在 its 源码中,主要分为 images 和 configurations 两个部分,images 部分定义了要打包的文件,configurations 部分定义了如何组合这些文件,在 UBOOT 启动时,会根据 configurations 中的 default 配置自动加载对应的文件到指定的地址,并且可以通过设置多个 configurations 来支持启动时选择加载不同配置的镜像。
Makefile 中 mkimage 对应的命令:
.PHONY: gen-fit
gen-fit: $(hvisor_bin) dtb
@if [ ! -f scripts/zcu102-aarch64-fit.its ]; then \
echo "Error: ITS file scripts/zcu102-aarch64-fit.its not found."; \
exit 1; \
fi
$(OBJCOPY) $(hvisor_elf) --strip-all -O binary $(HVISOR_TMP_PATH)
# now we need to create the vmlinux.bin
$(GCC_OBJCOPY) $(ROOT_LINUX_IMAGE) --strip-all -O binary $(ROOT_LINUX_IMAGE_BIN)
@sed \
-e "s|__ROOT_LINUX_IMAGE__|$(ROOT_LINUX_IMAGE_BIN)|g" \
-e "s|__ROOT_LINUX_ROOTFS__|$(ROOT_LINUX_ROOTFS)|g" \
-e "s|__ROOT_LINUX_DTB__|$(ROOT_LINUX_DTB)|g" \
-e "s|__HVISOR_TMP_PATH__|$(HVISOR_TMP_PATH)|g" \
scripts/zcu102-aarch64-fit.its > temp-fit.its
@mkimage -f temp-fit.its $(TARGET_FIT_IMAGE)
@echo "Generated FIT image: $(TARGET_FIT_IMAGE)"
请注意
不要将已经由 UBOOT 打包的 Image 传入 its 源文件,否则会导致 二次打包!因为 its 中指向的文件应为原始文件(vmlinux 等),mkimage 在导入 its 时对逐个文件进行打包处理(vmlinux->"Image",然后内嵌到 fitImage)。
在 petalinux qemu 中通过 FIT 镜像启动 hvisor 和 root linux
由于 fitImage 一个文件就包括了所有需要的文件,因此对于 qemu 来说只需要通过 loader 把这个文件加载到内存中一个合适的位置即可。
之后 qemu 启动并进入 UBOOT,可以使用下面的命令启动(具体的地址请根据实际情况修改,实际使用时可以把所有行写到一行内 copy 到 UBOOT 进行启动,也可以保存到环境变量 bootcmd 中,需要UBOOT挂载一个可持久化的 flash 用于环境变量保存):
setenv fit_addr 0x10000000; setenv root_linux_load 0x200000;
imxtract ${fit_addr} root_linux ${root_linux_load}; bootm ${fit_addr};
参考文献
[1] Flat Image Tree (FIT). https://docs.u-boot.org/en/stable/usage/fit/
新板子需要的操作
如果板子为新到手的 RK3588,则可能板子内部未被烧写任何内容,包括引导,因此需要首先对板子进行初步烧写,为其烧写 Uboot、Linux、Rootfs 等内容。烧写推荐在 Windows 通过RKDevTool完成。
可以直接下载此链接中的 update.img。此镜像打包了上述所有内容。直接烧写此镜像即可一步到位,具体操作如下:
- 用 USB 连接电脑和板子上的 Type-C 口。
- 首先让板子处于 MaskRoom 或者 Loader 模式(可以在 RKDevTool 识别到)
- Loader 模式:在通电状态下同时按住 RST 和 BOOT 按键,或者在 Uboot、Linux 下输入
reboot loader - MaskRoom 模式:新板子默认处于此模式。
- Loader 模式:在通电状态下同时按住 RST 和 BOOT 按键,或者在 Uboot、Linux 下输入
- 在 RKDevTool 中按照下图进行操作
获取 RK3588 内核镜像
RK3588 有着专用的内核镜像,源码可以通过此链接获取。
为了方便快速上手,这里的内核已经是经过编译的内核,因此文件较大。可以通过kernel/arch/arm64/boot/Image直接获取镜像,也可利用现成的.config 重新定制所需镜像。
当然,如果不关心内核源码,可以通过此链接直接获取 Image。
串口连接
RK3588 的串口比较特殊,需要自行购买 USB转TTL 转换器进行连接

连接时 RT-TX、TX-RD、GND-GND,连接到电脑后串口波特率为1500000。
重新烧写 Uboot
要想启动 hvisor,原有的 Uboot 没有等待时间,会直接启动 Linux。需要对 Uboot 进行重新烧写,这里也已经准备好了一份 Uboot 及其烧写工具,通过Uboot、Upgrade-tool即可获取。
在 Linux 系统下,同样用 Usb 连接板子和电脑,并使其处于 Loader 模式:
chmod +777 /path/to/upgrade_tool
sudo upgrade_tool di -u /path/to/uboot.img
编译 Hvisor 和设备树
- 和其他开发板类似,拉取 hvisor 最新代码,仓库地址:https://github.com/syswonder/hvisor。进入目录后编译 hvisor:
make BID=aarch64/rk3588 - 进入
/images/aarch64/devicetree/,rk3588-root-aarch64-sdmmc.dts是 RK3588 RootLinux 所使用的设备树,rk3588-nonroot-aarch64.dts是 RK3588 NonRootLinux 所使用的设备树。 可以使用下面的命令对其编译:dtc -I dts -O dtb rk3588-nonroot-aarch64.dts -o ./linux1.dtb dtc -I dts -O dtb rk3588-root-aarch64-sdmmc.dts -o ./zone0.dtb
制作文件系统
准备一个 SD 卡,分区两块,第一块 FAT32 格式,大小 1g;第二块 EXT4 格式。
下载文件系统,将此文件系统解压到 EXT4 格式分区下即可。
当然,也可以自行制作,参考基于ubuntu_base构建文件系统。
启动 RootLinux
TFTP
如果已经搭建了 TFTP 服务器,那么可以以方便的方式快速启动 RootLinux,具体而言:
- 将 Image、zone0.dtb、hvisor.bin 复制到 ~/tftp 文件夹下
- 用网线连接主机与开发板,配置主机ip为
192.168.137.2,子网掩码255.255.255.0。 - 直接开机并连接串口即可,uboot 将自动下载 tftp 文件夹下的内容并启动。
如果有搭建需求,可以参考嵌入式平台快速开发-Tftp 服务器搭建与配置。
无 TFTP
此时 SD 卡中第一块 FAT32 分区即派上了用场,将 Image、zone0.dtb、hvisor.bin 复制到此分区中
- 启动开发板,连接串口。
- 打断 Uboot 自动启动。
- 输入下述指令启动 RootLinux
fatload mmc 0:1 0x00480000 hvisor.bin;fatload mmc 0:1 0x10000000 zone0.dtb;fatload mmc 0:1 0x09400000 Image;bootm 0x00480000 - 0x10000000
启动 NonRootLinux
下载现成的配置文件
通过此链接可下载可用的 NonRoot 配置,包括 Image、配置文件、rootfs等,将其解压到 RootLinux 的文件系统中,其可以帮助快速启动Nonroot,主要启动的设备有virtio-blk和virtio-console,也可根据自己的需求直通设备。
Tips:
请不要随意修改 Image 为 Rootlinux 使用的 Image,此会导致 Nonroot 启动失败!
编译 hvisor-tool
拉取 Hvisor-tool 的最新代码:https://github.com/syswonder/hvisor-tool/tree/main,进行编译:
make all ARCH=aarch64 LOG=LOG_INFO KDIR=RK3588内核源码 VIRTIO_GPU=n
更多细节请参考 hvisor-tool 的 Readme.md。
注意,内核源码必须已经经过编译,否则hvisor-tool将会因为找不到编译产物而报错。
Tips:
编译 hvisor-tool 时所使用的 glibc 版本需要保证 Rootlinux 文件系统也支持,否则会导致 hvisor-tool 不能正常工作!
例如,本文给出的 Rootlinux Rootfs 为 Ubuntu 24.04。编译机的 Glibc 版本要不高于 Ubuntu24.04 的 Glibc 版本,这里由于 Ubuntu24.04 较新,一般是满足的。
当然,上述操作是通过对齐两个文件系统所用的 glibc 版本来完成的,也可以直接在 Rootlinux 文件系统中编译 hvisor-tool,或者在编译机指定 Rootlinux 的文件系统目录,使得编译链接时直接链接 Rootlinux 文件系统的 glibc,具体如下:
make all ARCH=aarch64 LOG=LOG_INFO KDIR=RK3588内核源码 VIRTIO_GPU=n \
ROOT=/path/to/target_rootfs
启动
在 Rootlinux 下执行下述命令
insmod hvisor.ko
nohup ./hvisor virtio start virtio_cfg.json &
./hvisor zone start zone1_linux.json
screen /dev/pts/0
即可看到第二个虚拟机(Nonroot)的输出。
Tips:
如果不按照上述流程配置 Rootlinux 的文件系统,或者随着版本迭代,可能会出现现成配置文件不可用的情况,此时需要自行更新配置,我们也会尽早跟进。
具体最新配置格式可以参考 hvisor-tool 下的 example 进行。
基于 RK3588 的 矽慧通 X3300 快速上手
本文档旨在为开发者详细介绍在 矽慧通 X3300 开发板上部署并启动 hvisor 的完整流程。
操作环境基于 Ubuntu 22.04 主机。我们假定已获取好 Rockchip Linux SDK 及 矽慧通 X3300 相应的配置文档 / 配置文件。文中所述的开发板特指基于 RK3588 的 矽慧通 X3300。
需要准备的器材
| 类别 | 器材名称 | 规格要求 | 数量 | 用途说明 |
|---|---|---|---|---|
| 核心设备 | 矽慧通 X3300 | 1 块 | 主要开发平台 | |
| 电源设备 | 电源适配器 | DC 9-36V | 1 个 | 供电 |
| 调试工具 | USB 转串口模块 | 支持 1.5 Mbps 波特率 | 1 个 | 串口调试和日志输出 |
| 连接线缆 | Type-C USB 线 | 数据线 | 1 条 | 连接 OTG 口用于烧录 |
| 网络设备 | 以太网线 | 标准网线 | 1 条 | 网络通信 |
| 显示设备 | HDMI 线 | 标准 HDMI 接口 | 1 条 | 连接显示器 |
| 主机环境 | Ubuntu 主机 | Ubuntu 22.04 系统 | 1 台 | 编译和烧录环境 |
开发板介绍
在开始之前,请确保开发板已备妥,并熟悉其基本接口布局。
本文档操作所涉及的接口均位于开发板的前后两端。

上图所示为开发板前侧接口,需要用到的有:
- OTG 口:Type-C USB 接口,用于烧录。
- BOOT 和 RST 按钮:下层标识 BOOT 和 RST 的按钮,用于进入 MaskROM 模式和复位开发板。

上图所示为开发板后侧接口,需要用到的有:
- 电源:位于右侧,DC 9-36 V 接入,中间为正,两侧为负,可接入任意两个 V+ / V- 接线柱;
- 调试串口:下层右侧标识有 DEBUG 的 RXD、TXD;
- 以太网口:ETH1,设备树配置中为
ethernet@fe1c0000; - 图像输出 HDMI:设备树配置中为
hdmi@fde80000;
电源
请使用规格匹配的电源适配器连接至开发板的 DC 电源接口,以确保供电稳定。该开发板支持 9-36V 宽压输入。正确连接电源后,开发板后侧上下两层的电源指示灯 PWR 均应亮起,如下图所示。

串口连接
为进行设备调试与查看启动日志,需要通过 USB 转串口模块连接到开发板的调试串口。
默认串口参数如下:
| 参数项 | 参数值 |
|---|---|
| 波特率 (Baud Rate) | 1500000 |
| 数据位 (Data Bits) | 8 |
| 停止位 (Stop Bits) | 1 |
| 校验位 (Parity) | None |
硬件连接正确后,可使用 minicom 等串口工具进行通信。
# 如果未安装 minicom,先执行下面的命令安装
# sudo apt update && sudo apt install minicom
# 定义串口参数
BAUD_RATE=1500000
SERIAL_DEVICE="/dev/ttyUSB0"
# 启动 minicom
sudo minicom -b "${BAUD_RATE}" -D "${SERIAL_DEVICE}"
接线提示
- 标准接法(交叉连接):将模块的
RXD连接到开发板的TXD,TXD连接到RXD,GND连接GND。- 特殊情况(直连):部分厂商(如 Firefly)的模块可能已在内部做了交叉处理,此时需要
RXD接RXD,TXD接TXD。请务必参考模块说明书或咨询厂商以确认正确的接线方式。
进入 Loader / MaskROM 模式
开发者可通过以下方法,使开发板进入指定的烧录模式。
进入 MaskROM 模式
MaskROM 模式是芯片内置的底层启动模式,主要用于设备首次烧录或系统固件损坏时进行修复。
- 保持开发板处于通电状态。
- 同时按住
BOOT键与RST键。 - 先松开
RST键。 - 稍等片刻后,再松开
BOOT键,此时开发板即进入 MaskROM 模式。
进入 Loader 模式
Loader 模式通过软件命令进入,是常规固件升级时使用的标准模式。
- 在开发板已启动的系统 Linux / Android 或者 U-Boot 的终端中,执行以下命令:
reboot loader - 命令执行后,开发板将自动重启并进入 Loader 模式。
烧录基础系统
新出厂的开发板可能未预装任何固件。在这种情况下,需要首次烧录基础系统,包括 U-Boot、Linux 内核和根文件系统 (Rootfs),以便检验开发板是否正常工作。
编译固件
下面编译 Rockchip Linux SDK 以生成 update.img。
首先切换到 SDK 的目录,查看目录结构如下:
ROCKCHIP_LINUX_SDK_DIR="~/rockchip_linux_sdk"
cd "${ROCKCHIP_LINUX_SDK_DIR}"
tree -L 1
user@host:~/rockchip_linux_sdk$ tree -L 1
.
├── app
├── buildroot
├── build.sh -> device/rockchip/common/scripts/build.sh
├── debian
├── device
├── docs
├── external
├── kernel
├── Makefile -> device/rockchip/common/Makefile
├── output
├── prebuilts
├── README.md -> device/rockchip/common/README.md
├── rk3588_linux_release.xml
├── rkbin
├── rkflash.sh -> device/rockchip/common/scripts/rkflash.sh
├── rockdev -> output/firmware
├── tools
├── u-boot
├── uefi
└── yocto
在编译开始之前,需要修改 U-Boot 的配置,以将自动启动延迟从 0 调整为 10 秒,方便 U-Boot 启动 Debian 之前按下 Ctrl + C 停止启动。
sed -i 's/CONFIG_BOOTDELAY=0/CONFIG_BOOTDELAY=10/g' u-boot/configs/rk3588_defconfig
下面开始编译。通过环境变量 RK_ROOTFS_SYSTEM 指定编译的根文件系统类型为 Debian,然后调用 build.sh 即可即可开始编译。
export RK_ROOTFS_SYSTEM="debian"
./build.sh sysoul_x3300_defconfig && ./build.sh
编译结果为 output/update/Image/update.img。
配置烧录工具
Rockchip 在 Linux 平台下使用 upgrade_tool 进行烧录,编译完成之后,upgrade_tool 将位于 tools/linux/Linux_Upgrade_Tool/ 目录下。
当然,也可以直接从 GitHub 仓库中下载。
# 安装依赖
sudo apt update && sudo apt install libudev-dev libusb-1.0-0-dev
# 克隆包含烧录工具的仓库
git clone https://github.com/vicharak-in/Linux_Upgrade_Tool.git
# 将工具路径添加到 PATH 环境变量,并使其立即生效
echo 'export PATH="$PATH:'$(pwd)/Linux_Upgrade_Tool'"' >> ~/.bashrc
source ~/.bashrc
连接设备并进入 MaskROM 模式
对于一块全新的开发板,我们需要手动使其进入 MaskROM 模式。
- 请按照前述步骤,使开发板进入 MaskROM 模式。
- 使用 USB 线缆将开发板的 USB-OTG 口连接到主机。
- 执行以下命令,检查设备是否被正确识别:
sudo upgrade_tool ld # ListDevice,查看设备
如果看到类似如下的输出,说明设备已准备就绪。
List of rockusb connected(1)
DevNo=1 Vid=0x2207,Pid=0x350b,LocationID=322 Mode=Maskrom SerialNo=
注意:
Vid=0x2207是 Rockchip 公司的 USB 厂商 ID。如果未检测到设备,请检查 USB 线缆连接或更换主机的 USB 端口。
烧录固件
接下来,使用 upgrade_tool 工具将 update.img 固件包烧录至开发板的闪存。
sudo upgrade_tool uf update.img -noreset # UpgradeFirmware,更新固件,使用 -noreset 参数防止烧录后自动重启,便于我们手动控制
烧录过程将持续数分钟,终端会显示详细的进度日志。
Loading firmware...
Support Type:3588 FW Ver:<FW-Ver> FW Time:<YYYY-MM-DD hh:mm:ss>
Loader ver:<Loader-ver> Loader Time:<YYYY-MM-DD hh:mm:ss>
Start to upgrade firmware...
Download Boot Start
Download Boot Success
Wait For Maskrom Start
Wait For Maskrom Success
Test Device Start
Test Device Success
Check Chip Start
Check Chip Success
Get FlashInfo Start
Get FlashInfo Success
Prepare IDB Start
Prepare IDB Success
Download IDB Start
Download IDB Success
Download Firmware Start
Download Image... (100%)
Download Firmware Success
Upgrade firmware ok.
当看到 Upgrade firmware ok. 消息时,表示烧录成功。
重启并验证
烧录完成后,手动重启开发板以加载新系统。
sudo upgrade_tool rd # ResetDevice,复位设备
终端应返回:
Reset Device OK.
此时,开发板将启动预装的 Debian 系统。可以将 HDMI 连接到显示器,稍等片刻即可看到图形化界面。

同时,在串口终端中也能观察到完整的启动日志以及控制台。
root@linaro-alip:/#
启动 hvisor
后续主机和开发板之间的文件传输均通过 IPv4 网络和 TFTP 协议进行。
配置主机网络并搭建 TFTP 服务器
首先配置主机的 IPv4 网络。我们将主机与开发板配置在一个点对点的 /30 网络中,该网络仅包含两个可用的主机地址,适用于这种直连场景。
HOST_NET_DEVICE="enp49s0" # 请根据实际情况修改为主机的网卡名称
HOST_IPV4="192.168.255.1"
NETMASK="255.255.255.252" # /30 子网掩码
sudo ifconfig "${HOST_NET_DEVICE}" "${HOST_IPV4}" netmask "${NETMASK}"
在主机上同时安装 TFTP 服务器软件和 TFTP 客户端软件(用于测试服务器是否正常工作)。
sudo apt update && sudo apt install tftpd-hpa tftp-hpa
创建 TFTP 根目录并设置权限。
TFTP_DIR="/srv/tftp"
sudo mkdir -p "${TFTP_DIR}"
sudo chown tftp:tftp "${TFTP_DIR}"
sudo chmod -R ugo+rw,a+X "${TFTP_DIR}"
编辑 tftpd-hpa 配置文件。
sudo tee /etc/default/tftpd-hpa > /dev/null <<EOF
# /etc/default/tftpd-hpa
TFTP_USERNAME="tftp"
TFTP_DIRECTORY="/srv/tftp"
TFTP_ADDRESS=":69"
TFTP_OPTIONS="-l -c -s"
EOF
启动 TFTP 服务器。
sudo systemctl start tftpd-hpa.service
测试 TFTP 服务器是否正常工作。
TFTP_DIR="/srv/tftp"
TEST_SRC_FILE_NAME="testfile.txt"
TEST_DST_FILE_NAME="downloaded_testfile.txt"
echo "TFTP Automation Test" > "${TFTP_DIR}/${TEST_SRC_FILE_NAME}" && \
tftp localhost -c get "${TEST_SRC_FILE_NAME}" "${TEST_DST_FILE_NAME}" && \
diff -q "${TFTP_DIR}/${TEST_SRC_FILE_NAME}" "${TEST_DST_FILE_NAME}" && \
echo "TFTP Test PASSED" || echo "TFTP Test FAILED" ; \
rm -f "${TFTP_DIR}/${TEST_SRC_FILE_NAME}" "${TEST_DST_FILE_NAME}"
准备 root-linux
提取 kernel
可以直接将原有 Rockchip Linux SDK 的编译结果中的 kernel(位于 kernel/arch/arm64/boot/ 路径下)提取出来,复制到 TFTP 目录。
TFTP_DIR="/srv/tftp"
ROCKCHIP_LINUX_SDK_DIR="$HOME/rockchip_linux_sdk"
cp "${ROCKCHIP_LINUX_SDK_DIR}/kernel/arch/arm64/boot/Image" "${TFTP_DIR}"
编译 device-tree
将开发板的 dts (例如 sysoul_x3300.dts) 复制一份,命名为 zone0.dts,并进行以下修改以划分资源给 GuestOS:
-
为 GuestOS 预留 CPU 核心: hvisor 的设计中,root-linux 和 GuestOS 各使用一部分 CPU 核心。此处我们仅为 root-linux 保留
cpu0和cpu1。在设备树中找到其余的cpu节点,将其删去。 -
为 hvisor 和 GuestOS 预留内存空间: 在
memory节点的reserved-memory区域下,添加两块保留内存。一块用于 hvisor 本身,另一块用于 GuestOS 的物理内存。no-map属性确保 root-linux 内核不会映射和使用这些区域。
--- a/sysoul_x3300.dts
+++ b/zone0.dts
...
reserved-memory {
...
+
+ hvisor@480000 {
+ no-map;
+ reg = <0x00 0x480000 0x00 0x400000>;
+ };
+
+ nonroot@50000000 {
+ no-map;
+ reg = <0x00 0x50000000 0x00 0x25000000>;
+ };
};
...
- 添加 hvisor virtio 设备节点:
在根节点下添加一个设备节点,用于 hvisor 的 virtio 后端驱动与 root-linux 内核进行通信。中断号需要根据具体的硬件平台进行配置,此处配置为
0x20。
--- a/sysoul_x3300.dts
+++ b/zone0.dts
...
};
+ hvisor_virtio_device {
+ compatible = "hvisor";
+ interrupt-parent = <0x01>;
+ interrupts = <0x00 0x20 0x01>;
+ };
完成上述修改后,编译设备树文件,并将编译结果复制到 TFTP 目录。
ROOT_LINUX_DTS="zone0.dts"
TFTP_DIR="/srv/tftp"
dtc -I dts -O dtb -o zone0.dtb "${ROOT_LINUX_DTS}"
cp zone0.dtb "${TFTP_DIR}"
配置 rootfs
rootfs 直接采用烧录好的即可,不需要修改。
编译 hvisor
配置好 Rust 编译环境之后,拉取 syswonder/hvisor 仓库的 main 分支,完成编译,将编译结果复制到 TFTP 目录。
TFTP_DIR="/srv/tftp"
git clone git@github.com:syswonder/hvisor.git
cd hvisor
cargo install cargo-binutils
make BID=aarch64/sysoul-x3300
cp target/aarch64-unknown-none/debug/hvisor.bin "${TFTP_DIR}"
编译 hvisor 之前,还需要根据开发板的具体情况按需修改对应 BID 的
board.rs文件中的配置信息。可以通过 Linux 的
/proc/iomem获取内存信息,根据设备信息填写 root zone 的 memory region 信息。注意:中断控制器的地址不要与 root zone 的 memory region 重叠。
board.rs中所需的中断号可以通过设备树文件和下面的命令快速获得。DTS_FILE="zone0.dts" cat "${DTS_FILE}" \ | tr -d '\n' \ | sed 's/;/\n/g' \ | grep "interrupts =" \ | tr -d '=<>' \ | awk '{for(i=3; i<=NF; i+=3) print $(i)}' \ | while read hex; do printf "%d\n" "$((hex + 0x20))"; done \ | sort -n \ | while read dec; do printf "0x%x\n" "$dec"; done \ | tr '\n' ','
启动 hvisor + root-linux
连接串口和电源,按下 RST 重启开发板。在串口终端中观察 U-Boot 启动信息,当看到倒计时提示时,立即按下 Ctrl + C 以中断自动启动流程,进入 U-Boot 命令行。
在 U-Boot 命令行中执行命令。首先配置 IPv4 网络,以访问主机 TFTP 服务器。在确认网络配置无误之后,使用 tftp 命令依次下载 hvisor kernel device-tree,并加载到对应地址,最后通过 bootm 指令启动。
# 配置网络
setenv ipaddr 192.168.255.2
setenv netmask 255.255.255.252
setenv serverip 192.168.255.1
# 为每个文件设置正确的内存地址变量
setenv board_dtb_addr 0x00400000
setenv hvisor_addr 0x00500000
setenv kernel_addr 0x09400000
setenv root_linux_dtb_addr 0x10000000
# 从 TFTP 服务器加载每个文件到对应的内存地址
tftp ${board_dtb_addr} sysoul_x3300.dtb
tftp ${hvisor_addr} hvisor.bin
tftp ${kernel_addr} Image
tftp ${root_linux_dtb_addr} zone0.dtb
# 从 hvisor_addr 启动
bootm ${hvisor_addr} - ${board_dtb_addr}
配置好网络之后,可以通过 ping 命令测试通断。
ping ${serverip}显示结果
=> ping ${serverip} ethernet@fe1c0000 Waiting for PHY auto negotiation to complete. done Using ethernet@fe1c0000 device host 192.168.255.1 is alive
看到 root-linux 正常启动,几乎与正常基础系统无差别。
启动 GuestOS
下面以 Ubuntu-22.04 搭配 Linux 5.10 内核 为例,在 zone1 上启动 Linux。配置好 zone1 所需文件后通过 TFTP 传输到开发板上再用 hvisor-tool 启动。
root-linux 访问 TFTP 服务器需要安装 TFTP 客户端,此时通过主机 Linux 作为跳板,使得 root-linux 可以访问互联网,然后在其上通过包管理器 apt 安装 TFTP 客户端软件。
具体命令为:
开发板 root-linux 的 Debian 系统默认使用 NetworkManager 管理网络,因此我们使用
nmcli工具进行配置:# 定义网络参数 HOST_IPV4="192.168.255.1" BOARD_IPV4="192.168.255.2" NETMASK="30" DNS_SERVER="8.8.8.8" BOARD_NET_DEVICE="eth0" # 配置开发板的静态 IP 地址、子网掩码、网关和 DNS 服务器 nmcli connection modify "${BOARD_NET_DEVICE}" 802-3-ethernet.mac-address "" nmcli connection modify "${BOARD_NET_DEVICE}" connection.interface-name "${BOARD_NET_DEVICE}" nmcli connection modify "${BOARD_NET_DEVICE}" ipv4.method manual nmcli connection modify "${BOARD_NET_DEVICE}" ipv4.addresses "${BOARD_IPV4}/${NETMASK}" nmcli connection modify "${BOARD_NET_DEVICE}" ipv4.gateway "${HOST_IPV4}" nmcli connection modify "${BOARD_NET_DEVICE}" ipv4.dns "${DNS_SERVER}" nmcli connection modify "${BOARD_NET_DEVICE}" connection.autoconnect yes在主机上执行:
BOARD_IPV4="192.168.255.2" NETMASK="30" # 开启内核的 IPv4 转发功能 sudo sysctl -w net.ipv4.ip_forward=1 # 配置防火墙,允许来自开发板的流量进行转发 sudo iptables -A FORWARD -s "${BOARD_IPV4}" -j ACCEPT sudo iptables -A FORWARD -d "${BOARD_IPV4}" -j ACCEPT # 配置 NAT 规则 sudo iptables -t nat -A POSTROUTING -s "${BOARD_IPV4}/${NETMASK}" -j MASQUERADE此时开发板 root-linux 即可通过主机访问 Internet,即可执行命令安装 TFTP 客户端软件。
sudo apt update && sudo apt install tftp-hpa最后需要指出,上述所有在主机上执行的命令均为临时配置,在系统重启后会失效。若要实现永久生效,建议将这些配置写入系统的网络管理服务配置文件中或通过启动脚本固化。
编译 hvisor-tool
首先,安装交叉编译工具链。
sudo apt update && sudo apt install gcc-aarch64-linux-gnu
接下来,克隆并编译 hvisor-tool。
ROCKCHIP_LINUX_SDK_DIR="$HOME/rockchip_linux_sdk"
git clone git@github.com:syswonder/hvisor-tool.git
cd hvisor-tool
export PATH="$PATH:${ROCKCHIP_LINUX_SDK_DIR}/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin"
make all ARCH=arm64 LOG=LOG_INFO KDIR="${ROCKCHIP_LINUX_SDK_DIR}/kernel"
编译完成后,将结果放到 TFTP 目录里面。
HVISOR_TOOL_DIR="$HOME/hvisor-tool"
TFTP_DIR="/srv/tftp"
# 复制 hvisor-tool 的 driver/hvisor.ko 和 tools/hvisor
cp "${HVISOR_TOOL_DIR}/output/hvisor.ko" "${TFTP_DIR}"
cp "${HVISOR_TOOL_DIR}/output/hvisor" "${TFTP_DIR}"
准备 zone1-linux
为简化,zone1-linux 仅提供 virtio-console(提供控制台)和 virtio-vlk(提供根文件系统)。
编译 kernel
编译完成后,将结果复制到 TFTP 目录。
ROCKCHIP_LINUX_SDK_DIR="$HOME/rockchip_linux_sdk"
TFTP_DIR="/srv/tftp"
# 下载 linux 5.10 源码
git clone https://github.com/torvalds/linux -b v5.10 --depth=1
cd linux
git checkout v5.10
# 生成默认的编译配置
CROSS_COMPILE_PATH="${ROCKCHIP_LINUX_SDK_DIR}/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin"
CROSS_COMPILE_PREFIX="${CROSS_COMPILE_PATH}/aarch64-none-linux-gnu-"
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} defconfig
# 启用 CONFIG_BLK_DEV_RAM,以启用 RAM 块设备支持
./scripts/config --enable CONFIG_BLK_DEV_RAM
# 编译
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} Image -j$(nproc)
# 编译结果复制
cp arch/arm64/boot/Image "${TFTP_DIR}/zone1-linux.kernel"
编译 device-tree
zone1-linux 需要一个独立的设备树来描述 hvisor 为其提供的虚拟硬件环境,例如虚拟 CPU、内存布局以及 virtio 设备等。
HVISOR_DIR="$HOME/hvisor"
TFTP_DIR="/srv/tftp"
cd "${HVISOR_DIR}"
make BID=aarch64/sysoul-x3300 dtb
cp "${HVISOR_DIR}/platform/aarch64/sysoul-x3300/image/dts/zone1-linux.dtb" "${TFTP_DIR}/zone1-linux.dtb"
下载 rootfs
使用 wget 命令下载预先定义的 Ubuntu 22.04.5 的根文件系统压缩包。这是一个最小化的 Ubuntu 环境,包含了运行一个基本系统所需的核心文件。
wget https://cdimage.ubuntu.com/ubuntu-base/releases/22.04/release/ubuntu-base-22.04.5-base-arm64.tar.gz
创建一个大小为 128 MiB 的空白的磁盘镜像文件,将其格式化为 ext4 文件系统,然后将下载的根文件系统解压进去。
ZONE1_ROOTFS_IMAGE="zone1-linux-rootfs.ext4"
dd if=/dev/zero of="${ZONE1_ROOTFS_IMAGE}" bs=1M count=128 oflag=direct
mkfs.ext4 "${ZONE1_ROOTFS_IMAGE}"
mkdir -p rootfs/
sudo mount -t ext4 "${ZONE1_ROOTFS_IMAGE}" rootfs/
sudo tar -xzf ubuntu-base-22.04.5-base-arm64.tar.gz -C rootfs/
sudo umount rootfs
rm -r rootfs
完成后,将该文件链接(节省空间)到 TFTP 目录。
TFTP_DIR="/srv/tftp"
ZONE1_ROOTFS_IMAGE="zone1-linux-rootfs.img"
ABSOLUTE_IMAGE_PATH=$(realpath "${ZONE1_ROOTFS_IMAGE}")
ln "${ABSOLUTE_IMAGE_PATH}" "${TFTP_DIR}"
准备 JSON 配置文件
hvisor-tool 通过 JSON 文件来管理 zone 和 virtio 设备的配置。我们需要创建两个核心的配置文件:
zone1-linux.json:用于定义 zone 本身的资源;zone1-linux-virtio.json:用于定义其所需的 virtio 设备。
hvisor 仓库中存放了本文对应的配置文件,位于 platform/aarch64/sysoul-x3300/configs/ 目录下,使用下面的命令将其复制到 TFTP 目录下。
HVISOR_DIR="$HOME/hvisor"
TFTP_DIR="/srv/tftp"
cp "${HVISOR_DIR}/platform/aarch64/sysoul-x3300/configs/*.json" "${TFTP_DIR}"
启动 zone1-linux
在 root-linux 的 root 用户下,执行命令:
HOST_IPV4="192.168.255.1"
# 切换到 /root 目录
cd ~
# 从 TFTP 服务器上,下载 hvisor-tool 和 zone1-linux 所需内容
tftp "${HOST_IPV4}" <<EOF
get hvisor.ko
get hvisor
get zone1-linux.kernel
get zone1-linux.dtb
get zone1-linux-rootfs.ext4
get zone1-linux.json
get zone1-linux-virtio.json
quit
EOF
# 加载 hvisor.ko
insmod hvisor.ko
# 给 hvisor 添加可执行权限
chmod +x hvisor
# 启动 zone1-linux 所需的 virtio-console 和 virtio-blk
rm nohup.out
nohup ./hvisor virtio start zone1-linux-virtio.json &
# 启动 zone1-linux
./hvisor zone start zone1-linux.json
此时,执行命令
./hvisor zone list
输出为
| zone_id | cpus | name | status |
| 0 | 0, 1 | root-linux | running |
| 1 | 2, 3 | zone1-linux | running |
说明 zone1-linux 已经启动成功。
此时输入命令 cat nohup.out | grep "char device" 即可查看 zone1-linux virtio-console 对应的 pts(一般是 /dev/pts/0),此时执行命令
screen /dev/pts/0
即可连接到 zone1-linux 的 console。
提示:如何在 minicom 中分离 (detach) screen 会话
minicom和screen的默认转义键都是Ctrl+A。因此,当在minicom窗口中与screen会话交互时,需要先发送一个转义字符给minicom,再将下一个Ctrl+A传递给screen。
- 分离
screen会话的步骤:依次按下Ctrl+A,Ctrl+A,D。
基于 RK3588 的 矽慧通 X3300 快速上手 (Android 虚拟机)
本文档旨在为开发者详细介绍在 矽慧通 X3300 开发板(亚克力版,带有 dsi 屏幕)上部署并启动 Android 虚拟机的完整流程。

操作环境基于 Ubuntu 22.04 主机。我们假定你已经参考了 基于 RK3588 的 矽慧通 X3300 快速上手 成功启动了 hvisor 以及 Root-Linux,并已经配置好主机网络与 TFTP 服务器。
由于 Android 系统包含大量图形界面相关的组件,且对硬件资源(如 GPU、NPU、多媒体、存储等)的性能要求极高,我们将采用硬件直通(Passthrough)和恒等映射(Identity Mapping)技术来满足 Android 的运行需求。
准备 Android 镜像
快捷获取预编译镜像:编译完整的 Android 和 Linux SDK 耗时较长且环境配置复杂。如果你只是想快速体验 hvisor 的 Android 虚拟化功能,可以跳过繁琐的编译和提取打包步骤。我们在百度网盘提供了已经配置好
virtio支持并编译打包好的 Root-Linux 烧录镜像(用于 SD 卡)和完整的 Androidupdate.img(用于板载 eMMC)。你可以直接下载使用:点击此处下载预编译镜像 (提取码: 394r)。
在主机上获取 Rockchip Android SDK。由于我们需要在虚拟机中启动,可以复用大部分原本供开发板裸机启动的镜像,但在编译前需要修改内核配置以支持 hvisor 的虚拟设备。
修改 Android 内核配置并编译
在 Android SDK 中,找到内核目录(kernel-5.10),修改对应的配置文件 arch/arm64/configs/rockchip_defconfig。为了支持通过 virtio 挂载的虚拟网络等设备,需要确保启用了以下配置项:
# 虚拟设备支持
CONFIG_VIRTIO_NET=y
CONFIG_VIRTIO_MMIO=y
CONFIG_VIRTIO_MMIO_CMDLINE_DEVICES=y
CONFIG_VIRTIO_CONSOLE=y
修改完成后,按照正常的 Rockchip Android SDK 编译流程进行编译(主要编译内核和 Boot 镜像):
source build/envsetup.sh
lunch rk3588_t-userdebug
# 编译 U-Boot、内核及 Android,指定具体的设备树配置
./build.sh -AUCKu -d sysoul_x3300
修改 Root-Linux 内核配置并编译
为了让 Root-Linux 能够创建网桥以及处理 Android 虚拟机的网络流量,必须确保 Root-Linux(即基础 Linux SDK)的内核开启了网桥(Bridge)、虚拟网络以及 TUN/TAP 设备支持。在 Rockchip Linux SDK 的内核目录中,检查并确保 defconfig 中包含以下配置:
CONFIG_MACVLAN=y
CONFIG_MACVTAP=y
CONFIG_IPVLAN=y
CONFIG_IPVTAP=y
CONFIG_TUN=y
CONFIG_BRIDGE=y
CONFIG_SIMPLE_PM_BUS=y
保存修改后,执行 Rockchip Linux SDK 的编译命令:
export RK_ROOTFS_SYSTEM="debian"
./build.sh rockchip_sysoul_x3300_defconfig
./build.sh
准备 Root-Linux 存储(烧录 SD 卡)
由于 Android 虚拟机直接使用了板载 eMMC 存储,我们需要将 Root-Linux 部署到 SD(TF)卡中。
-
格式化与建立分区表 在 Linux 主机下插入 SD 卡(假设识别为
/dev/sdb),使用sgdisk命令清除现有分区并建立包含指定 UUID 的 GPT 分区表:# 1. 清除现有的分区表 sudo sgdisk -Z /dev/sdb # 2. 创建分区 (需补上指定的 UUID 以确保 Root-Linux 挂载点正确) sudo sgdisk \ -n 1:16384:+4M -c 1:uboot \ -n 2:24576:+4M -c 2:misc \ -n 3:32768:+64M -c 3:boot -u 3:7A3F0000-0000-446A-8000-702F00006273 \ -n 4:163840:+128M -c 4:recovery \ -n 5:425984:+32M -c 5:backup \ -n 6:491520:+14336M -c 6:rootfs -u 6:614e0000-0000-4b53-8000-1d28000054a9 \ -n 7:29851648:+128M -c 7:oem \ -n 8:30113792:0 -c 8:userdata -u 8:614e0000-0000-4b53-8000-1d28000054b0 \ /dev/sdb # 3. 重新读取分区表 sudo partprobe /dev/sdb -
烧录镜像 进入 Linux SDK 编译生成的镜像目录,手动通过
dd命令将编译出的各个分区镜像写入对应的 SD 卡分区(执行前千万注意核对/dev/sdb是否为你的 SD 卡设备):# 0. 烧录 Loader (非常重要,否则无法启动,写在开头位置) sudo dd if=MiniLoaderAll.bin of=/dev/sdb seek=64 conv=notrunc # 1. 烧录 uboot sudo dd if=uboot.img of=/dev/sdb1 status=progress # 2. 烧录 misc sudo dd if=misc.img of=/dev/sdb2 status=progress # 3. 烧录 boot (内核) sudo dd if=boot.img of=/dev/sdb3 status=progress # 4. 烧录 recovery sudo dd if=recovery.img of=/dev/sdb4 status=progress # 5. 烧录 rootfs (系统文件) sudo dd if=rootfs.img of=/dev/sdb6 status=progress # 6. 烧录 oem sudo dd if=oem.img of=/dev/sdb7 status=progress # 7. 烧录 userdata sudo dd if=userdata.img of=/dev/sdb8 status=progress
提取 Kernel 和 Ramdisk
在进行下面的步骤之前,为了让你更好地理解接下来的配置,我们先来看一下基于 hvisor 的 Android 虚拟机与 Root-Linux 的计算资源分区设计图:
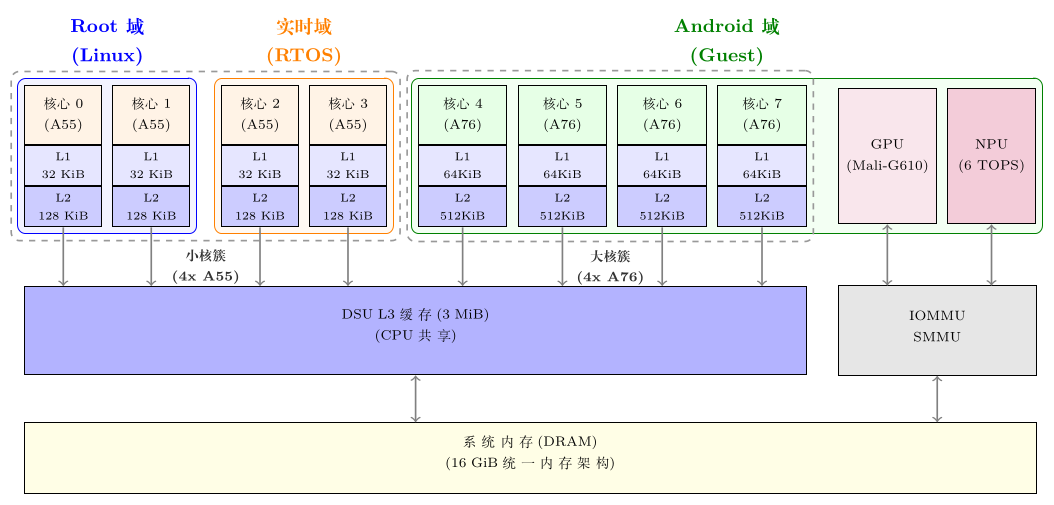
如上图所示,Android 虚拟机独占了 4 个 Cortex-A76 高性能大核,而 Root-Linux 运行在 Cortex-A55 效能核心上。(注:图中 RTOS 区域为架构设计的预留分区,在当前的 Android 快速上手配置中尚未实现,实际处于空置状态)。
U-Boot 启动环境变量配置
如果你的板子没有自动进入 Root-Linux,或者你需要通过网络进行调试启动,可以在 U-Boot 阶段设置环境变量,并通过 TFTP 加载各个镜像。这里提供了一组经过验证的配置:
setenv ipaddr 192.168.255.2
setenv netmask 255.255.255.0
setenv serverip 192.168.255.1
setenv board_dtb_addr 0x00400000
setenv hvisor_addr 0x00500000
setenv root_linux_dtb_addr 0x10000000
setenv kernel_addr 0x10400000
tftp ${board_dtb_addr} sysoul_x3300.dtb
tftp ${hvisor_addr} hvisor.bin
tftp ${root_linux_dtb_addr} zone0-linux.dtb
tftp ${kernel_addr} Image
bootm ${hvisor_addr} - ${board_dtb_addr}
- Android Kernel (
Image): 直接使用 Android SDK 编译生成的kernel/arch/arm64/boot/Image。 - Ramdisk (
ramdisk.img): 在 Rockchip SDK 中,Ramdisk 通常被打包在boot.img或vendor_boot.img内。我们可以利用 Android SDK 自带的工具(如unpack_bootimg和mkbootfs)进行提取和重打包。- 使用工具解压
boot.img以提取其内部包含的ramdisk压缩包。 - 对其中的文件结构按需进行裁剪(例如移除一些可能导致冲突的 init 挂载脚本),然后重新使用
mkbootfs打包生成一个独立的ramdisk.img文件。
- 使用工具解压
将处理好的镜像文件复制到主机的 TFTP 目录中:
TFTP_DIR="/srv/tftp"
ROCKCHIP_ANDROID_SDK_DIR="$HOME/rockchip_android_sdk"
cp "${ROCKCHIP_ANDROID_SDK_DIR}/kernel/arch/arm64/boot/Image" "${TFTP_DIR}/zone1-android.kernel"
# 假设你提取并打包后的文件名为 ramdisk.img
cp ramdisk.img "${TFTP_DIR}/zone1-android.ramdisk"
Ramdisk 与两阶段 init 启动机制说明
这里的 ramdisk.img 对应 Android 启动早期使用的 initramfs。对于 Android 13, init 进程通常采用两阶段 (Two-Stage Init) 启动流程,其目的在于支持动态分区 (super) 等现代分区方案,并在系统关键分区可用前完成最小化初始化。
- 第一阶段 init (initramfs / first stage):
Android 内核启动后先挂载 initramfs, 执行第一阶段 init。该阶段会完成
/dev、/proc、/sys等基础虚拟文件系统挂载,并加载存储相关驱动,使得 eMMC 上的系统分区可被识别与挂载。 - 根文件系统切换 (pivot_root / switch_root):
当 eMMC 上的关键分区(如
system、vendor等)挂载完成后,init 会切换根文件系统,从 initramfs 过渡到真实系统分区。 - 第二阶段 init (second stage):
在真实根文件系统上继续执行
/system/bin/init, 解析init.rc等脚本并拉起 Android 的核心服务,最终进入图形界面。
因此,配置中需要同时满足两点:一是 hvisor-tool 的 modules 里正确加载 ramdisk.img, 二是设备树 chosen 节点中用于描述 initrd 地址范围的字段与实际加载地址保持一致(否则内核可能找不到 initramfs 或无法进入两阶段启动流程)。
准备 Device-Tree
你无需手动进行复杂的修改。在 hvisor 代码仓库的对应开发板目录(platform/aarch64/sysoul-x3300/image/dts/)下,已经提供了一份适配好所有虚拟化和硬件直通节点的设备树源码文件 zone1-android.dts。
请直接使用该文件进行编译,并将生成的 dtb 文件拷贝至主机的 TFTP 目录中:
HVISOR_DIR="$HOME/hvisor"
TFTP_DIR="/srv/tftp"
# 编译设备树
dtc -I dts -O dtb -o zone1-android.dtb "${HVISOR_DIR}/platform/aarch64/sysoul-x3300/image/dts/zone1-android.dts"
cp zone1-android.dtb "${TFTP_DIR}"
注意:为了防止 Root-Linux 自动关闭不需要的时钟和电源域(导致 Android 内部的设备如 GPU 挂死),同时需要在 Root-Linux 的启动参数(cmdline)中加入
clk_ignore_unused和pd_ignore_unused。
准备 hvisor 管理工具
为了在 Root-Linux 中加载和管理 Android 虚拟机,我们需要编译 hvisor-tool 及其内核驱动模块 hvisor.ko。直接仿照 基于 RK3588 的 矽慧通 X3300 快速上手 中的步骤进行编译即可。
准备 JSON 配置文件
hvisor-tool 通过 JSON 文件来管理虚拟机的资源分配与设备隔离。
与常规的 Linux 虚拟机不同,Android 需要采用恒等映射(Identity Mapping)来透传物理内存与中断(如 GPU、NPU 的访问控制),以实现 DMA 的零拷贝。同时还需要配置多阶段启动所需的 Ramdisk 等模块。
你不必从头编写这份配置,hvisor 的代码仓库中已经提供了现成的配置文件,它们位于 platform/aarch64/sysoul-x3300/configs/ 目录下(例如 zone1-android.json 与 zone1-android-virtio.json)。
你只需要将这些配置文件复制到主机的 TFTP 目录中即可:
HVISOR_DIR="$HOME/hvisor"
TFTP_DIR="/srv/tftp"
cp "${HVISOR_DIR}/platform/aarch64/sysoul-x3300/configs/zone1-android*.json" "${TFTP_DIR}"
关键配置要点说明:
- CPU 划分:我们将 4 个 Cortex-A76 高性能大核(核心 4, 5, 6, 7)分配给 Android 虚拟机,保障其图形界面渲染和应用运行的性能。
- 内存恒等映射:物理地址(
physical_start)与虚拟地址(virtual_start)保持一致。这种设计对于 Mali-G610 GPU 和 NPU 的 DMA 零拷贝至关重要。 - 中断透传:分配了直通设备相关的硬件中断,包括 GPU、NPU 以及必要的电源管理控制器(在配置文件中可以直接看到十六进制的中断号定义)。
- 多阶段启动:在
modules中配置了ramdisk,让 Android 采用两阶段 init (Two-Stage Init) 的方式,先在 initramfs 中执行基础初始化挂载,然后再切换(pivot_root)至 eMMC 上的真实存储分区。
启动 Android 虚拟机
配置虚拟网络与外部 DHCP 服务器
为了让 Android 虚拟机能够顺利获取 IP 地址并访问外部网络,我们需要通过 Virtio-Net 并借助 Root-Linux 上的软件网桥将 Android 的网络桥接到外部物理网络。
具体的网络拓扑为:主机的物理网卡 -- eth0 (Root-Linux 物理网卡) -- br0 (Root-Linux 软件网桥) -- tap0 (hvisor virtio-net 后端) -- eth0 (Android 虚拟网卡)。
在该网络架构中,所有的远程节点、堡垒机、开发板等都被统一规划在 192.168.255.0/24 的网络内。在这一简化版的本地配置中,你的主机就相当于扮演了网关(兼 DHCP 服务器)的角色。
-
主机端配置 DHCP 服务器 由于开发板通过点对点网络直接连接到主机,主机需要充当 DHCP 服务器,为桥接在同一网段的 Android 虚拟机分配 IP。 在主机上安装
isc-dhcp-server并进行配置:sudo apt update && sudo apt install isc-dhcp-server编辑
/etc/dhcp/dhcpd.conf,添加以下子网配置(主机 IP 为192.168.255.1,分配100~199作为 DHCP 地址池):subnet 192.168.255.0 netmask 255.255.255.0 { range 192.168.255.100 192.168.255.199; option routers 192.168.255.1; option domain-name-servers 8.8.8.8, 114.114.114.114; }修改
/etc/default/isc-dhcp-server,指定监听的网卡(如enp49s0),然后重启服务:sudo systemctl restart isc-dhcp-server -
Root-Linux 端配置网桥 Root-Linux (Debian 11) 默认使用 NetworkManager 管理网络,在启动虚拟机之前,我们需要使用
nmcli创建一个网桥,并将物理网卡(如eth0)接入该网桥,同时为网桥分配原来的静态 IP:# 1. 创建网桥 br0,并配置静态 IP 192.168.255.2/24,网关指向主机 192.168.255.1,关闭 STP nmcli connection add type bridge ifname br0 con-name br0 \ ipv4.method manual \ ipv4.addresses 192.168.255.2/24 \ ipv4.gateway 192.168.255.1 \ ipv4.dns "8.8.8.8" \ bridge.stp no # 2. 将物理网卡 eth0 作为从设备接入网桥 br0 nmcli connection add type ethernet ifname eth0 con-name bridge-slave-eth0 master br0 # 3. 停用原有的 eth0 连接(如果有的话,防止冲突) nmcli connection down eth0 || true # 4. 创建 tap0 虚拟网卡设备,并直接作为从设备接入网桥 br0 nmcli connection add type tun ifname tap0 con-name bridge-slave-tap0 mode tap master br0 # 5. 启用网桥,并确认配置 nmcli connection up br0 ip addr执行完以上命令后,
br0网桥以及与其桥接的eth0和tap0都会就绪,并且tap0将专门供 hvisor 的 virtio-net 后端守护进程使用。
传输文件并启动
启动开发板并进入 Root-Linux 系统。首先利用 TFTP 客户端将主机上的镜像文件和配置文件下载至开发板:
HOST_IPV4="192.168.255.1"
# 切换到 /root 目录
cd ~
# 从 TFTP 服务器上,下载 hvisor-tool 和 zone1-android 所需内容
tftp "${HOST_IPV4}" <<EOF
get hvisor.ko
get hvisor
get zone1-android.kernel
get zone1-android.dtb
get zone1-android.ramdisk
get zone1-android.json
get zone1-android-virtio.json
quit
EOF
文件就绪后,加载 hvisor.ko 驱动并使用 hvisor-tool 启动 Android 虚拟机:
# 加载 hvisor.ko
insmod hvisor.ko
# 给 hvisor 添加可执行权限
chmod +x hvisor
# 启动 zone1-android 所需的 virtio-net 和 virtio-console 守护进程
nohup ./hvisor virtio start zone1-android-virtio.json &
# 启动 zone1-android
./hvisor zone start zone1-android.json
观察启动结果
执行启动命令后,Root-Linux 的终端通常会有对应的调用输出:
[ 105.246417] hvisor.ko: invoking hypercall to start the zone
此时 hvisor 将会分配对应的 Cortex-A76 物理核心并跳转至 Android 内核的入口。 建议为 Android 配置一个独立的物理串口进行日志输出(避免与 Root-Linux 共享一个串口,以防止由于输出拥堵导致 Android 的 console 挂死)。
可以在 Android 的串口中观察到完整的内核日志以及 init 进程的两阶段挂载信息:
[ 105.510077][ T0] Booting Linux on physical CPU 0x0000000400 [0x414fd0b0]
[ 105.510087][ T0] Linux version 5.10.157 (rk3588dev@xiuos) (Android (8490178, based on r450784d) clang version 14.0.6)
...
[ 106.015203][ T0] GICv3: 480 SPIs implemented
...
[ 109.175574][ T1] init: Using Android DT directory /proc/device-tree/firmware/android/
...
[ 118.722898][ T56] android_work: sent uevent USB_STATE=CONFIGURED
Android 杂项配置与调试
由于我们是在虚拟机中启动定制的 Android,部分功能可能需要手动介入:
-
查看编译配置:可以通过在 Android 的 Shell 中执行
zcat /proc/config.gz | grep VIRTIO来确认内核是否正确开启了对应的 virtio 功能。 -
显示屏方向配置:开发板默认的显示输出方向可能与你的显示器不符。如果不进行调整,鼠标操作会非常困难。可以使用以下命令强制旋转屏幕(例如顺时针旋转 90 度或 270 度):
wm user-rotation lock 1 # 或者 wm user-rotation lock 3 -
可执行文件路径:在开发和调试时,如果你需要 push 原生的可执行二进制文件到 Android 中运行,建议放在
/data/local/tmp目录下。该路径通常用于临时调试文件,写权限更稳定,且相比系统分区(例如/system、/vendor)更适合放置自定义二进制文件。例如,在 Android Shell 中执行:
cd /data/local/tmp chmod +x your_bin ./your_bin如果遇到
Permission denied, 请优先检查文件是否有可执行权限,以及目标目录是否可写。
等待几十秒的时间,直通了 eMMC、GPU 和 VOP2 显示子系统的 Android 虚拟机将启动其核心服务,随后图形化用户界面会输出显示。至此,Android 虚拟机在 hvisor 上启动成功。
此时,你可以分别在 Root-Linux 和 Android 虚拟机中查看系统信息。
如下图所示,Root-Linux 为 Debian 11,共有 2 个核心,Linux 内核版本为 5.10.160。
如下图所示,Android 为 Android 13,共有 4 个核心,Android 内核版本为 5.10.160。
也可以运行 Android 应用,显示实时渲染的图形界面。

基于 rk3568 的 Dayu200 快速上手 (OpenHarmony 虚拟机)
本文档旨在为开发者详细介绍在 Dayu200 开发板上部署并启动 OpenHarmony 虚拟机的完整流程。
Dayu200 开发板介绍
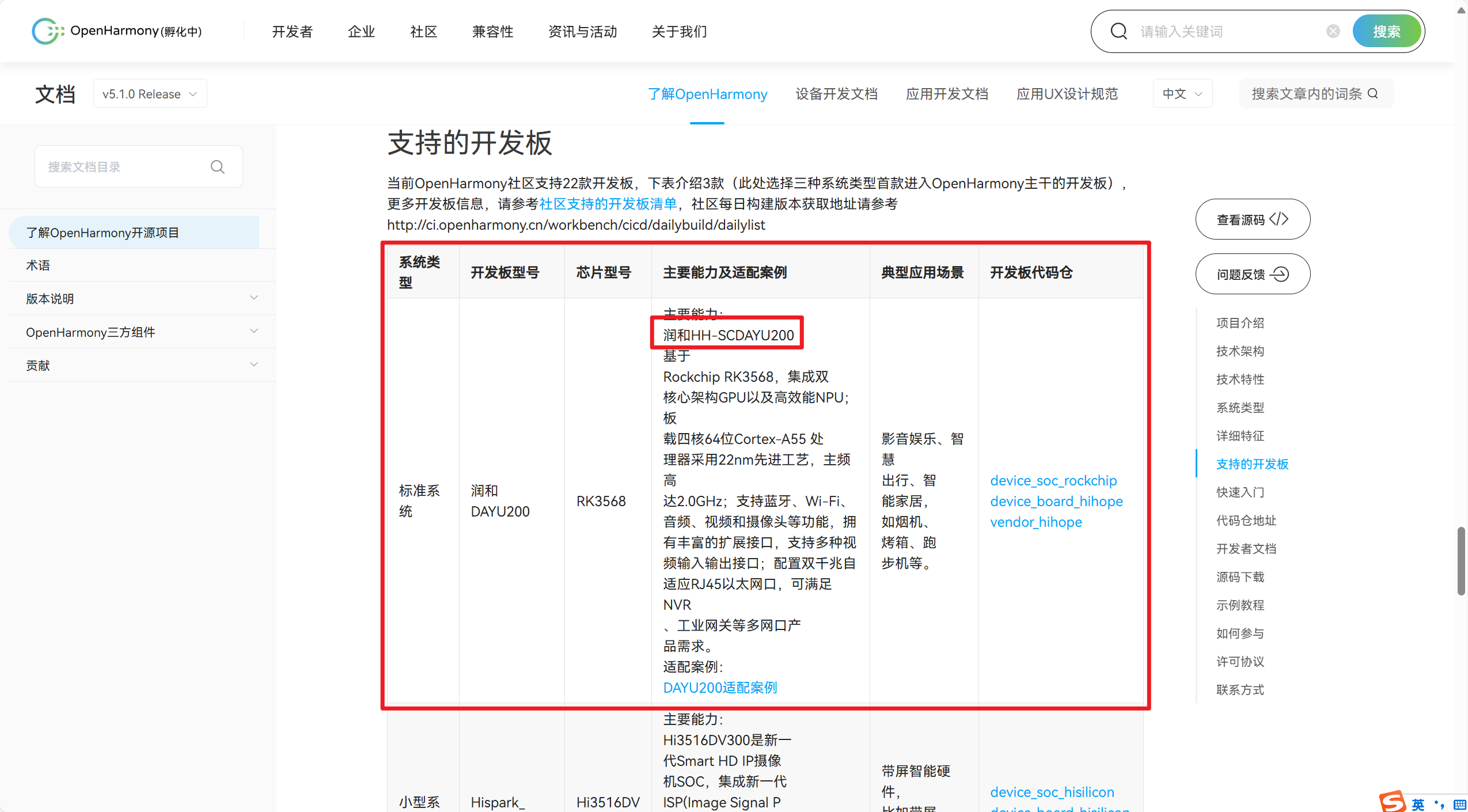

上述需要用到的接口有:DC12V电源、Debug串口(用于Serial串口)、USB3.0接口(用于传输文件)、Ethernet接口(用于连接网线)
为进行设备调试与查看启动日志,需要通过开发板发货提供的数据线,通过电脑的USB接口连接到开发板的调试串口。
默认串口参数如下:
| 参数项 | 参数值 |
|---|---|
| 波特率 (Baud Rate) | 1500000 |
| 数据位 (Data Bits) | 8 |
| 停止位 (Stop Bits) | 1 |
| 校验位 (Parity) | None |
OpenHarmony系统准备
准备Ubuntu20.04的VMware虚拟机环境(在WSL中无法编译)
sudo apt-get update; sudo apt-get install binutils; sudo apt-get install binutils-dev; sudo apt-get install git; sudo apt-get install git-lfs; sudo apt-get install gnupg; sudo apt-get install flex; sudo apt-get install bison; sudo apt-get install gperf; sudo apt-get install build-essential; sudo apt-get install zip; sudo apt-get install curl; sudo apt-get install zlib1g-dev; sudo apt-get install gcc-multilib; sudo apt-get install g++-multilib; sudo apt-get install libc6-dev-i386; sudo apt-get install libc6-dev-amd64; sudo apt-get install lib32ncurses5-dev; sudo apt-get install x11proto-core-dev; sudo apt-get install libx11-dev; sudo apt-get install lib32z1-dev; sudo apt-get install ccache; sudo apt-get install libgl1-mesa-dev; sudo apt-get install libxml2-utils; sudo apt-get install xsltproc; sudo apt-get install unzip; sudo apt-get install m4; sudo apt-get install bc; sudo apt-get install gnutls-bin; sudo apt-get install python3.9; sudo apt-get install python3-pip; sudo apt-get install ruby; sudo apt-get install genext2fs; sudo apt-get install device-tree-compiler; sudo apt-get install make; sudo apt-get install libffi-dev; sudo apt-get install e2fsprogs; sudo apt-get install pkg-config; sudo apt-get install perl; sudo apt-get install openssl; sudo apt-get install libssl-dev; sudo apt-get install libelf-dev; sudo apt-get install libdwarf-dev; sudo apt-get install u-boot-tools; sudo apt-get install mtd-utils; sudo apt-get install cpio; sudo apt-get install doxygen; sudo apt-get install liblz4-tool; sudo apt-get install openjdk-8-jre; sudo apt-get install gcc; sudo apt-get install g++; sudo apt-get install texinfo; sudo apt-get install dosfstools; sudo apt-get install mtools; sudo apt-get install default-jre; sudo apt-get install default-jdk; sudo apt-get install libncurses5; sudo apt-get install apt-utils; sudo apt-get install wget; sudo apt-get install scons; sudo apt-get install python3.9-distutils; sudo apt-get install tar; sudo apt-get install rsync; sudo apt-get install git-core; sudo apt-get install libxml2-dev; sudo apt-get install lib32z-dev; sudo apt-get install grsync; sudo apt-get install xxd; sudo apt-get install libglib2.0-dev; sudo apt-get install libpixman-1-dev; sudo apt-get install kmod; sudo apt-get install jfsutils; sudo apt-get install reiserfsprogs; sudo apt-get install xfsprogs; sudo apt-get install squashfs-tools; sudo apt-get install pcmciautils; sudo apt-get install quota; sudo apt-get install ppp; sudo apt-get install libtinfo-dev; sudo apt-get install libtinfo5; sudo apt-get install libncurses5-dev; sudo apt-get install libncursesw5; sudo apt-get install libstdc++6; sudo apt-get install gcc-arm-none-eabi; sudo apt-get install vim; sudo apt-get install ssh; sudo apt-get install locales; sudo apt-get install libxinerama-dev; sudo apt-get install libxcursor-dev; sudo apt-get install libxrandr-dev; sudo apt-get install libxi-dev
将python和python3软链接到3.8
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.8 1
mkdir ohos5
cd ohos5
repo init -u git@gitee.com:openharmony/manifest.git -b refs/tags/OpenHarmony-v5.1.0-Release --no-repo-verify
repo sync -c
repo forall -c 'git lfs pull'
安装hb编译工具
python3 -m pip install --user build/hb
vim ~/.bashrc
export PATH=~/.local/bin:$PATH
source ~/.bashrc
在容器中源码目录执行:
bash build/prebuilts_download.sh
使用命令行脚本编译:
./build.sh -p rk3568
如果期间存在
[OHOS INFO] [NINJA] [0/1] Regenerating ninja files
[OHOS INFO] [NINJA] [0/2] Regenerating ninja files
[OHOS INFO] [NINJA] [0/3] Regenerating ninja files
[OHOS INFO] [NINJA] [0/4] Regenerating ninja files
重复Regenerating ninja files的问题,修复所有文件的时间戳
find . -type f -exec touch {} +
然后重新编译成功,13900HX 花费3.5个小时编译OpenHarmony标准系统的rk3568
在这里HiHope_DAYU200/烧写工具及指南/windows/RKDevTool.exe · HiHope开源社区/Docs - 码云 - 开源中国下载烧录工具
安装对应的驱动程序,电脑连接开发板后,显示发现一个MASKROM设备
按住VOL-/RECOVERY 按键(图中标注的①号键) 和 RESET 按钮(图中标注的②号键)不松开, 烧录工具此时显示“没有发现设备” ;

松开 RESET 键, 烧录工具显示“发现一个 LOADER 设备”, 说明此时已经进入烧写模式,点击执行开始烧录
这样就能在开发板上运行原始的OpenHarmony系统了。
以下是OpenHarmony编译出来的产物
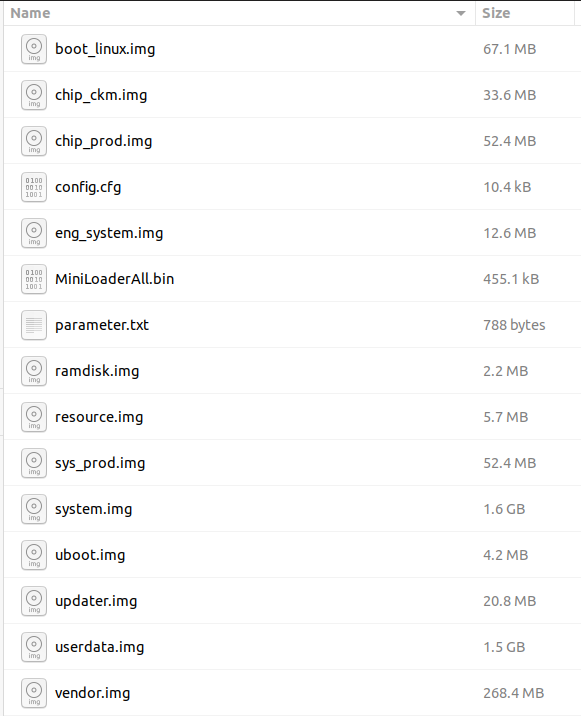
核心流程:U-Boot → 从存储设备加载 boot_linux.img → 解析并加载内核、设备树、ramdisk → 设置启动参数(bootargs)→ 启动 Linux 内核
在 RK3568 平台上,对应的启动镜像是 boot_linux.img,一个打包镜像,它把启动系统所需的多个组件打包在一起,方便 U-Boot 一次性加载。它包含以下三个核心部分:
| 文件 | 作用 | 来源 |
|---|---|---|
Image | Linux 内核镜像(未压缩的可执行镜像) | 由 kernel 源码编译生成,路径通常是 out/kernel/.../Image |
toybrick.dtb | 设备树二进制文件(Device Tree Blob),描述硬件信息 | 由 .dts 文件编译生成,如 rk3568-toybrick.dts → toybrick.dtb |
ramdisk.img | 初始化内存盘镜像,包含最基础的根文件系统(如 /init 脚本) | 由 OpenHarmony 编译系统生成,使用 cpio 格式打包 |
生成boot_linux.img的脚本代码在device/soc/rockchip/common/sdk_linux/scripts/mkimg这个路径下,使用的是 mkbootimg 工具,生成的是 Android 格式镜像,略不同于mkimage工具。两种格式的镜像都能被uboot启动
u-boot 启动时,会设置 bootargs 字符串,类似这样
setenv bootargs "initrd=0x84000000,0x292e00 init=/init blkdevparts=mmcblk0:1M(boot),15M(kernel),200M(system)... hardware=Hi3516DV300 root=/dev/ram0 rootfstype=ext4 default_boot_device=soc/1010000.himci.eMMC"
| 名称 | 示例 | 说明 |
|---|---|---|
initrd | 0x84000000,0x292e00 | 指定 initramfs 的地址和大小 |
init | /init | 指定内核启动后运行的第一个程序 |
blkdevparts | mmcblk0:1M(boot),15M(kernel), 200M(system),200M(vendor), 2M(misc),20M(updater),-(userdata) | 告诉内核 eMMC / SD 卡上的分区是怎么划分的 |
hardware | Hi3516DV300, rk3568 等 | 告诉内核当前硬件平台 |
root | /dev/ram0, 或 root=PARTUUID=... | 告诉内核从哪个设备加载根文件系统 |
rootfstype | ext4 | 根文件系统的类型 |
default_boot_device | soc/1010000.himci.eMMC | 默认启动设备路径,示例中这是一个设备树节点路径,指向 SoC 上的 eMMC 控制器 |
ohos.required_mount.xxx | /dev/block/platform/soc/1010000.himci.eMMC/by-name/xxx@usr@ext4@ro,barrier=1@wait,required | OpenHarmony 定义的一些必须挂载的分区,比如 system, vendor, userdata 等。 |
init 进程在系统启动初期,必须先找到并挂载 system、vendor 等关键分区,才能继续启动系统。
OpenHarmony通过TFTP裸启动
首先在电脑上配置好TFTP的运行环境,接下来尝试按照TFTP和定制设备树直接启动OpenHarmony
setenv serverip 192.168.1.10;
setenv ipaddr 192.168.1.20;
setenv loadaddr 0x61000000;
setenv fdt_addr 0x60000000;
setenv ramdisk_addr 0x0A200000;
tftp ${fdt_addr} zone0.dtb;
tftp ${loadaddr} Image;
tftp ${ramdisk_addr} uInitrd;
booti ${loadaddr} ${ramdisk_addr}:0x400000 ${fdt_addr}
其中zone0.dtb在hvisor的dayu200 platform配置路径下。 Image为OpenHarmony的系统在Obj/linux6.6下的编译镜像产物。 uInitrd为ramdisk(OpenHarmony的编译产物)经过了改装,U-Boot 在解析 ramdisk 时会先查找镜像头:
- 如果有 U-Boot 镜像头,它认为是一个合法的 ramdisk。
- 如果只是 gzip 压缩的 cpio(没有 U-Boot header),就会报错
ramdisk.img只是标准的 initramfs 文件,没有 U-Boot 镜像头, U-Boot 的 booti 不认,所以还需要执行
mkimage -A arm64 -O linux -T ramdisk -C gzip -d ramdisk.img uInitrd
ramdisk镜像大小只有2.14MB,而ramdisk的扇区大小是4MB,OpenHarmony在运行过程中需要sync一些数据到扇区的后面,因此booti命令还需要指定扇区的长度为0x400000。
OpenHarmony 前置工作准备
编译Hvisor-tool
OpenHarmony内核会强制验证模块签名,内核开启了 CONFIG_MODULE_SIG 并且强制 (CONFIG_MODULE_SIG_FORCE=y),而 hvisor.ko 没有用内核信任的私钥签名。
每次编译都会生成不同的密钥,即使命令完全一样。
 修改编译配置,使用脚本将下面的编译选项禁用:
修改编译配置,使用脚本将下面的编译选项禁用:
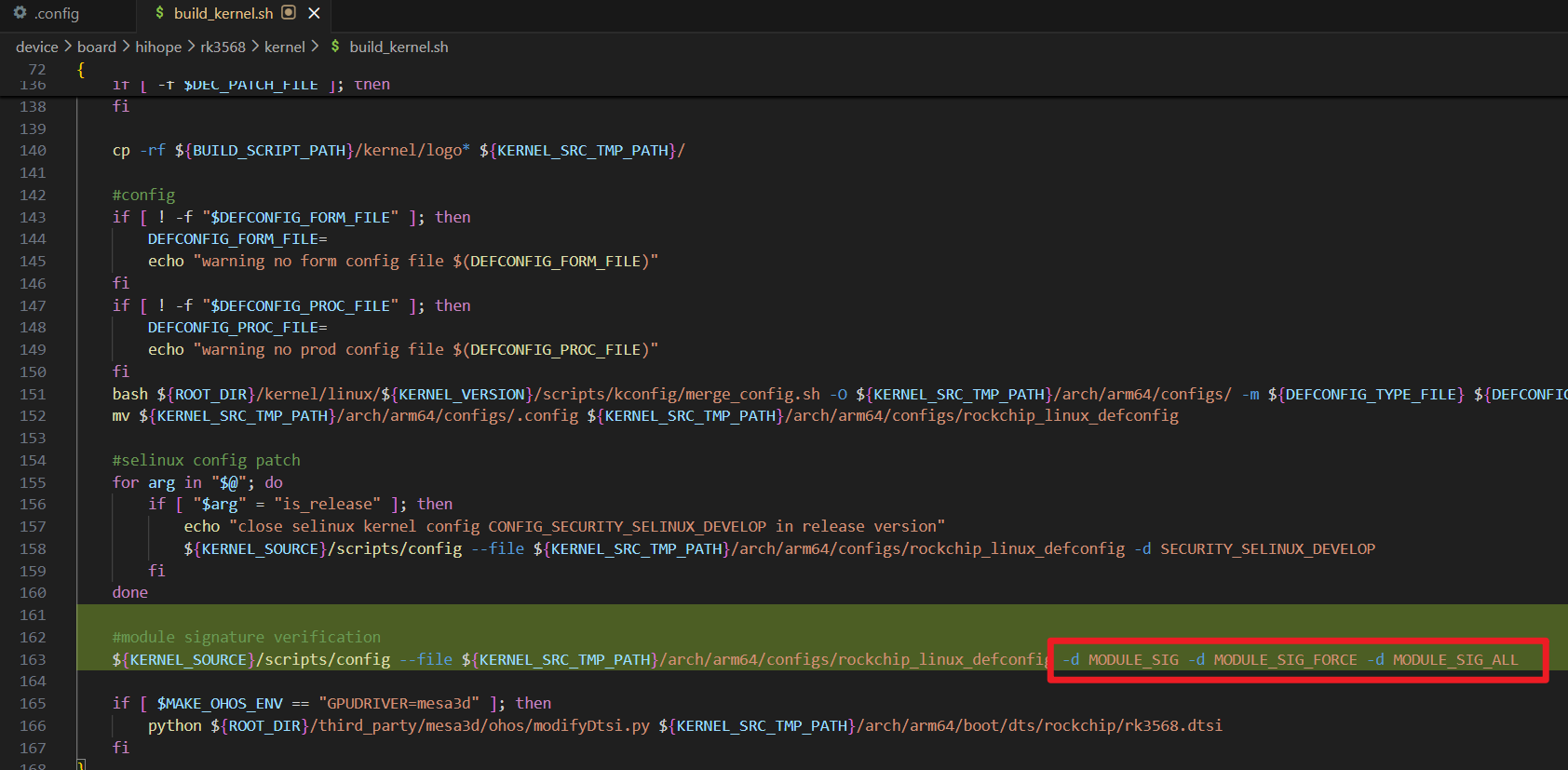
#module signature verification
${KERNEL_SOURCE}/scripts/config --file ${KERNEL_SRC_TMP_PATH}/arch/arm64/configs/rockchip_linux_defconfig -d MODULE_SIG -d MODULE_SIG_FORCE -d MODULE_SIG_ALL
还需要修改代码,如果不存在signing_key.pem就跳过
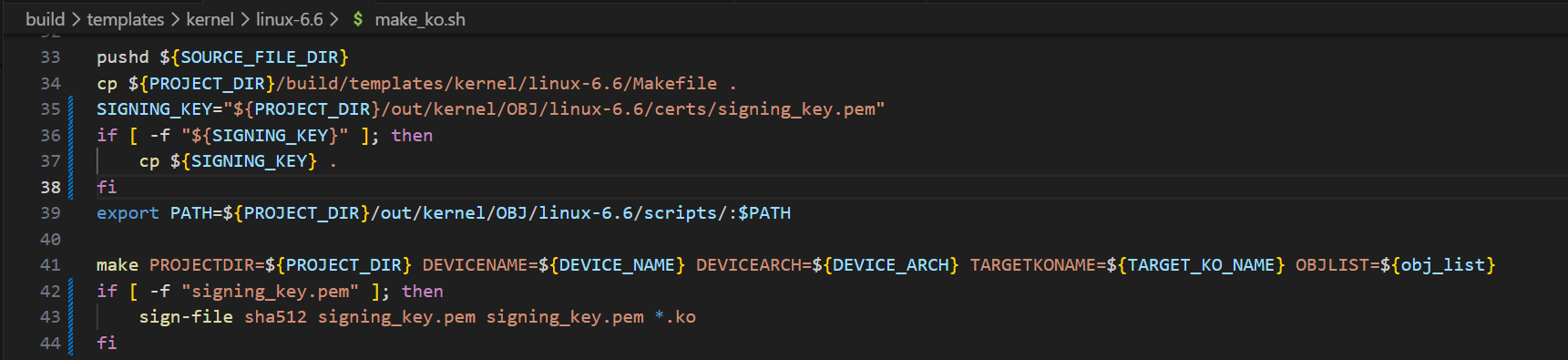
SIGNING_KEY="${PROJECT_DIR}/out/kernel/OBJ/linux-6.6/certs/signing_key.pem"
if [ -f "${SIGNING_KEY}" ]; then
cp ${SIGNING_KEY} .
fi
export PATH=${PROJECT_DIR}/out/kernel/OBJ/linux-6.6/scripts/:$PATH
make PROJECTDIR=${PROJECT_DIR} DEVICENAME=${DEVICE_NAME} DEVICEARCH=${DEVICE_ARCH} TARGETKONAME=${TARGET_KO_NAME} OBJLIST=${obj_list}
if [ -f "signing_key.pem" ]; then
sign-file sha512 signing_key.pem signing_key.pem *.ko
fi
此外,Hvisor使用了mmap /dev/mem,用于把 kernel/DTB 镜像写入物理内存。而OpenHarmony内核开启了 CONFIG_STRICT_DEVMEM,它会阻止通过 /dev/mem 访问 RAM 区域,mmap 直接返回 EPERM。因此需要再将此选项禁用。否则会出现如下错误:
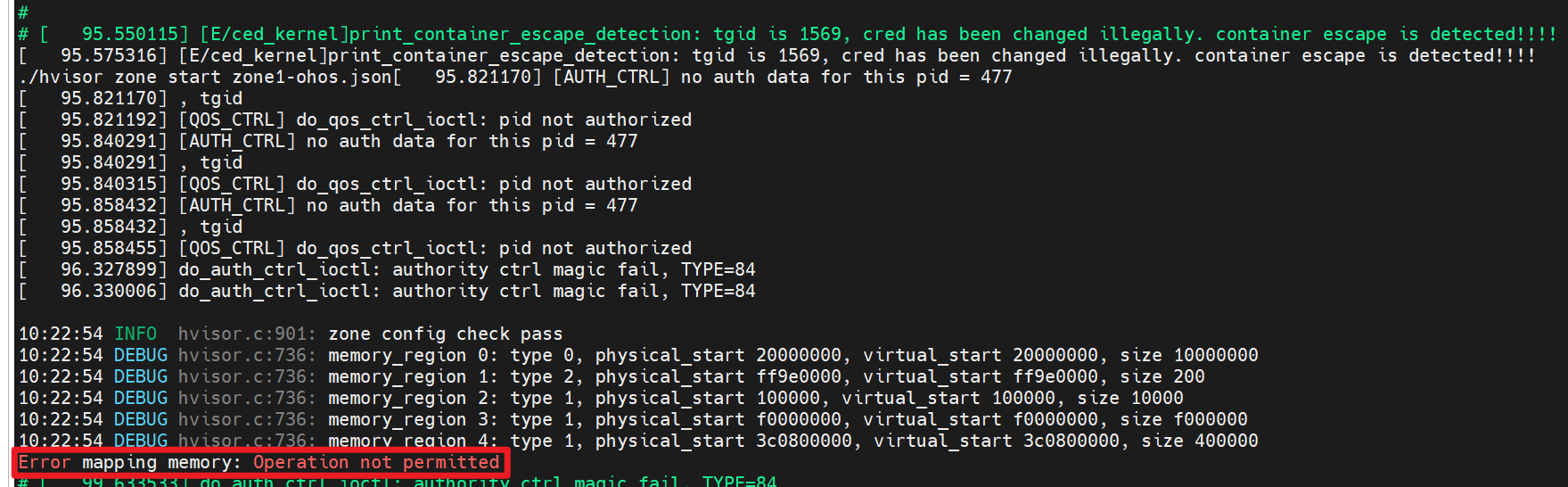
另外,还需要修改OpenHarmony的编译脚本,加上如下命令modules_prepare,这样才能针对OpenHarmony编译自定义模块也就是hvisor.ko:
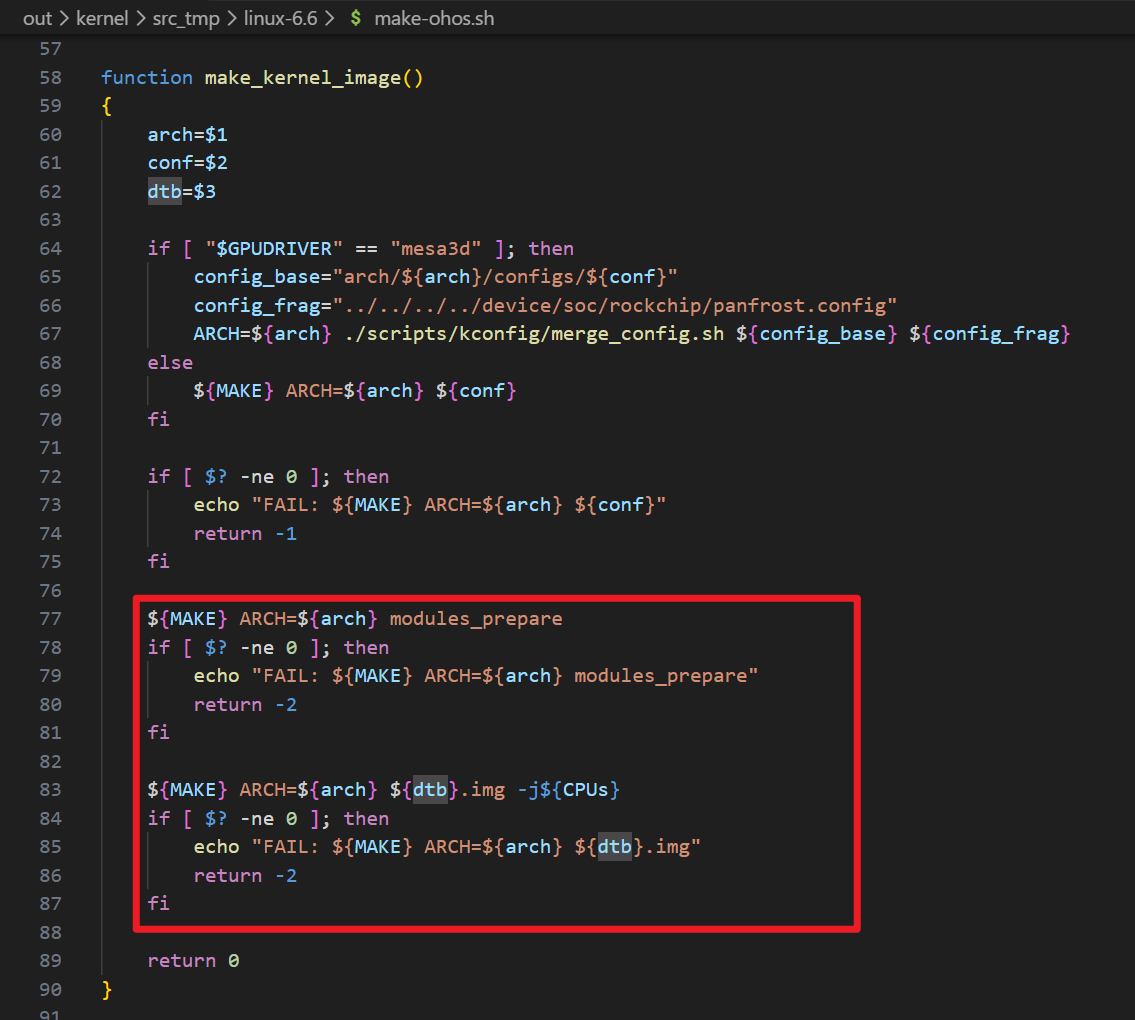 否则会出现如下报错:
否则会出现如下报错:
OpenHarmony使用LLVM编译,并且需要使用OpenHarmony提供的LLVM编译器,并且指定KDIR路径,下面是编译Hvisor-tool的命令:
export PATH=/home/stone/ohos5/prebuilts/clang/ohos/linux-x86_64/llvm/bin/:$PATH
export PATH=/home/stone/ohos5/prebuilts/develop_tools/pahole/bin/:$PATH
make LLVM=1 LLVM_IAS=1 CROSS_COMPILE=aarch64-linux-gnu- ARCH=arm64 LOG=LOG_INFO KDIR=/home/stone/ohos5/out/kernel/OBJ/linux-6.6 VIRTIO_GPU=n driver
make LLVM=1 LLVM_IAS=1 CROSS_COMPILE=aarch64-linux-gnu- ARCH=arm64 LOG=LOG_INFO KDIR=/home/stone/ohos5/out/kernel/OBJ/linux-6.6 VIRTIO_GPU=n tools
请将home/stone/ohos5替换为OpenHarmony的项目路径。
Openharmony SD卡配置
目前zone1的文件系统存放在SD卡上,对应的设备树节点为
dwmmc@fe2b0000 {
compatible = "rockchip,rk3568-dw-mshc\0rockchip,rk3288-dw-mshc";
reg = <0x00 0xfe2b0000 0x00 0x4000>;
interrupts = <0x00 0x62 0x04>;
clocks = <0x24 0xb0 0x24 0xb1 0x24 0x18a 0x24 0x18b>;
clock-names = "biu\0ciu\0ciu-drive\0ciu-sample";
fifo-depth = <0x100>;
max-frequency = <0x8f0d180>;
resets = <0x24 0xd4>;
reset-names = "reset";
status = "okay";
supports-sd;
bus-width = <0x04>;
cap-mmc-highspeed;
cap-sd-highspeed;
disable-wp;
no-1-8-v;
pinctrl-names = "default";
pinctrl-0 = <0xc5 0xc6 0xc7 0xc8>;
};
准备一张SD卡,接入Linux系统中,然后清除现有的分区表sudo sgdisk -Z /dev/sdb。
创建SD卡分区
sudo sgdisk \
-n 1:8192:16383 -c 1:uboot -t 1:8300 \
-n 2:16384:24575 -c 2:misc -t 2:8300 \
-n 3:24576:28671 -c 3:bootctrl -t 3:8300 \
-n 4:28672:40959 -c 4:resource -t 4:8300 \
-n 5:40960:237567 -c 5:boot_linux -t 5:8300 -u 5:a2d37d82-51e0-420d-83f5-470db993dd35 \
-n 6:237568:245759 -c 6:ramdisk -t 6:8300 \
-n 7:245760:4440063 -c 7:system -t 7:8300 -u 7:614e0000-0000-4b53-8000-1d28000054a9 \
-n 8:4440064:6537215 -c 8:vendor -t 8:8300 \
-n 9:6537216:6639615 -c 9:sys-prod -t 9:8300 \
-n 10:6639616:6742015 -c 10:chip-prod -t 10:8300 \
-n 11:6742016:6807551 -c 11:updater -t 11:8300 \
-n 12:6807552:6840319 -c 12:eng_system -t 12:8300 \
-n 13:6840320:6873087 -c 13:eng_chipset -t 13:8300 \
-n 14:6938624:7069695 -c 14:chip_ckm -t 14:8300 \
-n 15:19955712:0 -c 15:userdata -t 15:8300 \
/dev/sdb
把bootable标志位设置为1。
sudo sgdisk -A 5:set:2 /dev/sdb
sudo partprobe /dev/sdb
sudo sgdisk -i 5 /dev/sdb
SD卡烧录,其中数据源为 OpenHarmony 的编译产物(执行前千万注意核对 /dev/sdb 是否为你的 SD 卡设备):
sudo dd if=MiniLoaderAll.bin of=/dev/sdb seek=64 conv=notrunc status=progress
sudo dd if=uboot.img of=/dev/sdb1 status=progress
sudo dd if=misc.img of=/dev/sdb2 status=progress
sudo dd if=bootctrl.img of=/dev/sdb3 status=progress
sudo dd if=resource.img of=/dev/sdb4 status=progress
sudo dd if=boot_linux.img of=/dev/sdb5 status=progress
sudo dd if=ramdisk.img of=/dev/sdb6 status=progress
sudo dd if=system.img of=/dev/sdb7 status=progress
sudo dd if=vendor.img of=/dev/sdb8 status=progress
sudo dd if=sys_prod.img of=/dev/sdb9 status=progress
sudo dd if=chip_prod.img of=/dev/sdb10 status=progress
sudo dd if=updater.img of=/dev/sdb11 status=progress
sudo dd if=eng_system.img of=/dev/sdb12 status=progress
sudo dd if=eng_chipset.img of=/dev/sdb13 status=progress
sudo dd if=chip_ckm.img of=/dev/sdb14 status=progress
sudo dd if=userdata.img of=/dev/sdb15 status=progress
弹出SD卡:
sudo eject /dev/sdb
编译适配OpenHarmony的busybox
OpenHarmony自带的shell功能过于简陋,而busybox提供了很多诸如网络、串口相关的配置功能,因此需要使用 OpenHarmony 仓库内已经准备好的 ARM64 交叉编译工具链,生成一个可在 OpenHarmony ARM64 环境中直接使用的静态链接 BusyBox。
git clone https://github.com/mirror/busybox.git
export TOOLCHAIN_PREFIX=/home/stone/ohos5/prebuilts/gcc/linux-x86/aarch64/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-
make CROSS_COMPILE="$TOOLCHAIN_PREFIX" menuconfig
该命令可以打开配置界面,将下列config配置设为y
CONFIG_STATIC=y
CONFIG_STATIC_LIBGCC=y
CONFIG_PREFIX="./_install"
CONFIG_FEATURE_INSTALLER=y
CONFIG_INSTALL_APPLET_SYMLINKS=y
CONFIG_SH_IS_ASH=y
CONFIG_ASH=y
CONFIG_FEATURE_EDITING=y
CONFIG_FEATURE_TAB_COMPLETION=y
# 网络相关配置:
CONFIG_IFCONFIG=y
CONFIG_ROUTE=y
CONFIG_IP=y
CONFIG_PING=y
CONFIG_NETSTAT=y
CONFIG_UDHCPC=y
CONFIG_TFTP=y
CONFIG_TFTPD=y
CONFIG_WGET=y
CONFIG_NC=y
CONFIG_TELNET=y
CONFIG_TELNETD=y
CONFIG_TUNCTL=y
编译命令:
cd /home/stone/ohos5/busybox
export TOOLCHAIN_PREFIX=/home/stone/ohos5/prebuilts/gcc/linux-x86/aarch64/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-
make CROSS_COMPILE="$TOOLCHAIN_PREFIX"
make CROSS_COMPILE="$TOOLCHAIN_PREFIX" install
得到的编译结果里busybox/busybox 是 ARM64 静态链接可执行文件,将其传输到OpenHarmony的文件系统中。
编译针对OpenHarmony的picocom串口工具
OpenHarmony的zone0系统通过picocom与zone1进行连接,这里针对OpenHarmony环境自己写了一个脚本程序
// SPDX-License-Identifier: MIT
/*
* A tiny picocom-compatible terminal connector for OpenHarmony board bring-up.
*
* This is not a full upstream picocom replacement. It implements the small
* subset needed to connect zone0 to hvisor-tool's virtio-console PTY:
*
* picocom --nolock --noinit --noreset -b 115200 /dev/pts/0
*
* Exit with Ctrl-a Ctrl-x.
*/
#define _GNU_SOURCE
#include <errno.h>
#include <fcntl.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/select.h>
#include <termios.h>
#include <unistd.h>
#define ARRAY_SIZE(a) (sizeof(a) / sizeof((a)[0]))
static volatile sig_atomic_t g_stop;
struct options {
const char *device;
int baud;
bool noinit;
bool noreset;
};
struct baud_entry {
int value;
speed_t speed;
};
static const struct baud_entry g_baud_table[] = {
{50, B50}, {75, B75}, {110, B110},
{134, B134}, {150, B150}, {200, B200},
{300, B300}, {600, B600}, {1200, B1200},
{1800, B1800}, {2400, B2400}, {4800, B4800},
{9600, B9600}, {19200, B19200}, {38400, B38400},
#ifdef B57600
{57600, B57600},
#endif
#ifdef B115200
{115200, B115200},
#endif
#ifdef B230400
{230400, B230400},
#endif
#ifdef B460800
{460800, B460800},
#endif
#ifdef B921600
{921600, B921600},
#endif
#ifdef B1000000
{1000000, B1000000},
#endif
#ifdef B1500000
{1500000, B1500000},
#endif
};
static void on_signal(int sig)
{
(void)sig;
g_stop = 1;
}
static void usage(FILE *out, const char *argv0)
{
fprintf(out,
"usage: %s [--nolock] [--noinit] [--noreset] [-b BAUD] DEVICE\n"
"\n"
"Tiny picocom-compatible connector for /dev/pts/N or a serial TTY.\n"
"Exit with Ctrl-a Ctrl-x.\n",
argv0);
}
static int parse_baud(const char *text)
{
char *end = NULL;
long value;
errno = 0;
value = strtol(text, &end, 10);
if (errno != 0 || end == text || *end != '\0' || value <= 0 ||
value > 4000000) {
fprintf(stderr, "invalid baud rate: %s\n", text);
return -1;
}
return (int)value;
}
static speed_t baud_to_speed(int baud)
{
size_t i;
for (i = 0; i < ARRAY_SIZE(g_baud_table); i++) {
if (g_baud_table[i].value == baud) {
return g_baud_table[i].speed;
}
}
return (speed_t)0;
}
static int parse_args(int argc, char **argv, struct options *opts)
{
int i;
opts->baud = 115200;
for (i = 1; i < argc; i++) {
if (strcmp(argv[i], "-h") == 0 || strcmp(argv[i], "--help") == 0) {
usage(stdout, argv[0]);
exit(0);
} else if (strcmp(argv[i], "--nolock") == 0) {
continue;
} else if (strcmp(argv[i], "--noinit") == 0) {
opts->noinit = true;
} else if (strcmp(argv[i], "--noreset") == 0) {
opts->noreset = true;
} else if (strcmp(argv[i], "-b") == 0 ||
strcmp(argv[i], "--baud") == 0) {
if (i + 1 >= argc) {
fprintf(stderr, "%s requires an argument\n", argv[i]);
return -1;
}
opts->baud = parse_baud(argv[++i]);
if (opts->baud < 0) {
return -1;
}
} else if (strncmp(argv[i], "-b", 2) == 0 && argv[i][2] != '\0') {
opts->baud = parse_baud(argv[i] + 2);
if (opts->baud < 0) {
return -1;
}
} else if (strncmp(argv[i], "--baud=", 7) == 0) {
opts->baud = parse_baud(argv[i] + 7);
if (opts->baud < 0) {
return -1;
}
} else if (argv[i][0] == '-') {
fprintf(stderr, "unsupported option: %s\n", argv[i]);
return -1;
} else if (opts->device == NULL) {
opts->device = argv[i];
} else {
fprintf(stderr, "unexpected argument: %s\n", argv[i]);
return -1;
}
}
if (opts->device == NULL) {
usage(stderr, argv[0]);
return -1;
}
return 0;
}
static int set_raw_stdin(struct termios *saved)
{
struct termios raw;
if (tcgetattr(STDIN_FILENO, saved) != 0) {
perror("tcgetattr(stdin)");
return -1;
}
raw = *saved;
cfmakeraw(&raw);
if (tcsetattr(STDIN_FILENO, TCSANOW, &raw) != 0) {
perror("tcsetattr(stdin)");
return -1;
}
return 0;
}
static int set_raw_device(int fd, int baud, struct termios *saved)
{
struct termios raw;
speed_t speed;
if (tcgetattr(fd, saved) != 0) {
perror("tcgetattr(device)");
return -1;
}
raw = *saved;
cfmakeraw(&raw);
raw.c_cflag |= CLOCAL | CREAD;
raw.c_cflag &= ~CRTSCTS;
speed = baud_to_speed(baud);
if (speed == (speed_t)0) {
fprintf(stderr, "unsupported baud rate: %d\n", baud);
return -1;
}
cfsetispeed(&raw, speed);
cfsetospeed(&raw, speed);
if (tcsetattr(fd, TCSANOW, &raw) != 0) {
perror("tcsetattr(device)");
return -1;
}
return 0;
}
static int write_all(int fd, const unsigned char *buf, size_t len)
{
size_t off = 0;
while (off < len) {
ssize_t n = write(fd, buf + off, len - off);
if (n < 0) {
if (errno == EINTR) {
continue;
}
return -1;
}
if (n == 0) {
return -1;
}
off += (size_t)n;
}
return 0;
}
static int pump(int dev_fd)
{
bool escaped = false;
unsigned char buf[512];
while (!g_stop) {
fd_set rfds;
int maxfd = dev_fd > STDIN_FILENO ? dev_fd : STDIN_FILENO;
int ret;
FD_ZERO(&rfds);
FD_SET(STDIN_FILENO, &rfds);
FD_SET(dev_fd, &rfds);
ret = select(maxfd + 1, &rfds, NULL, NULL, NULL);
if (ret < 0) {
if (errno == EINTR) {
continue;
}
perror("select");
return -1;
}
if (FD_ISSET(dev_fd, &rfds)) {
ssize_t n = read(dev_fd, buf, sizeof(buf));
if (n < 0) {
if (errno == EINTR || errno == EAGAIN) {
continue;
}
perror("read(device)");
return -1;
}
if (n == 0) {
fprintf(stderr, "\r\n[device closed]\r\n");
return 0;
}
if (write_all(STDOUT_FILENO, buf, (size_t)n) != 0) {
perror("write(stdout)");
return -1;
}
}
if (FD_ISSET(STDIN_FILENO, &rfds)) {
ssize_t n = read(STDIN_FILENO, buf, sizeof(buf));
ssize_t i;
if (n < 0) {
if (errno == EINTR || errno == EAGAIN) {
continue;
}
perror("read(stdin)");
return -1;
}
if (n == 0) {
return 0;
}
for (i = 0; i < n; i++) {
unsigned char c = buf[i];
if (escaped) {
escaped = false;
if (c == 0x18 || c == 'x' || c == 'X') {
fprintf(stderr, "\r\n[exiting]\r\n");
return 0;
}
if (c != 0x01 &&
write_all(dev_fd, (const unsigned char *)"\001", 1) !=
0) {
perror("write(device)");
return -1;
}
} else if (c == 0x01) {
escaped = true;
continue;
}
if (write_all(dev_fd, &c, 1) != 0) {
perror("write(device)");
return -1;
}
}
}
}
return 0;
}
int main(int argc, char **argv)
{
struct options opts = {0};
struct termios saved_stdin;
struct termios saved_dev;
bool stdin_saved = false;
bool dev_saved = false;
int fd;
int ret;
if (parse_args(argc, argv, &opts) != 0) {
return 2;
}
signal(SIGINT, on_signal);
signal(SIGTERM, on_signal);
signal(SIGHUP, on_signal);
fd = open(opts.device, O_RDWR | O_NOCTTY);
if (fd < 0) {
perror(opts.device);
return 1;
}
if (!opts.noinit) {
if (set_raw_device(fd, opts.baud, &saved_dev) != 0) {
close(fd);
return 1;
}
dev_saved = true;
}
if (set_raw_stdin(&saved_stdin) != 0) {
if (dev_saved && !opts.noreset) {
tcsetattr(fd, TCSANOW, &saved_dev);
}
close(fd);
return 1;
}
stdin_saved = true;
fprintf(stderr, "connected to %s, exit with Ctrl-a Ctrl-x\r\n",
opts.device);
ret = pump(fd);
if (stdin_saved) {
tcsetattr(STDIN_FILENO, TCSANOW, &saved_stdin);
}
if (dev_saved && !opts.noreset) {
tcsetattr(fd, TCSANOW, &saved_dev);
}
close(fd);
return ret == 0 ? 0 : 1;
}
使用如下命令对picocom进行编译
#!/usr/bin/env bash
set -euo pipefail
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
OHOS_ROOT="$(cd "$SCRIPT_DIR/.." && pwd)"
TOOLCHAIN_PREFIX="${TOOLCHAIN_PREFIX:-$OHOS_ROOT/prebuilts/gcc/linux-x86/aarch64/gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-}"
if [[ ! -x "${TOOLCHAIN_PREFIX}gcc" ]]; then
echo "missing compiler: ${TOOLCHAIN_PREFIX}gcc" >&2
exit 1
fi
cd "$SCRIPT_DIR"
make clean
make TOOLCHAIN_PREFIX="$TOOLCHAIN_PREFIX"
make TOOLCHAIN_PREFIX="$TOOLCHAIN_PREFIX" install
file output/picocom
ls -l output/picocom
将编译产物复制到OpenHarmony的/data/zone目录下。后续通过该脚本控制连接zone1的串口终端。
将下列文件通过OpenHarmony开发者工具hdc,从主机电脑拷贝到OpenHarmony的EMMC文件系统上(需要通过开发板上的蓝色调试线连接):
hdc file send "D:\rk3568\configs\zone1-ohos.dtb" /data/zone
hdc file send "D:\rk3568\configs\zone1-ohos.json" /data/zone
hdc file send "D:\rk3568\configs\zone1-ohos-virtio.json" /data/zone
hdc file send "D:\rk3568\configs\zone1-ohos.kernel" /data/zone
hdc file send "D:\rk3568\configs\zone1-ohos.ramdisk" /data/zone
hdc file send "D:\rk3568\configs\hvisor.ko" /data/zone
hdc file send "D:\rk3568\configs\busybox" /data/zone
hdc file send "D:\rk3568\configs\picocom" /data/zone
其中zone1-ohos.kernel就是OpenHarmony编译出来的Image文件,zone1-ohos.ramdisk也是OpenHarmony的编译产物ramdisk。
OpenHarmony root zone 启动
在hvisor项目路径下执行make BID=aarch64/dayu200 all,编译适配dayu200开发板的hvisor。
编译的产物在cp target/aarch64-unknown-none/debug/hvisor.bin路径下
使用如下命令启动OpenHarmony root zone:
setenv serverip 192.168.1.10;
setenv ipaddr 192.168.1.20;
setenv loadaddr 0x40400000;
setenv board_dtb_addr 0x08300000;
setenv zone0_kernel_addr 0x61000000;
setenv zone0_fdt_addr 0x60000000;
setenv ramdisk_addr 0x0A200000;
tftp ${loadaddr} ${serverip}:hvisor.bin;tftp ${board_dtb_addr} ${serverip}:zone0.dtb; tftp ${zone0_kernel_addr} ${serverip}:Image; tftp ${zone0_fdt_addr} ${serverip}:zone0.dtb;tftp ${ramdisk_addr} ramdisk_emmc.img; bootm ${loadaddr} - ${board_dtb_addr};
OpenHarmony guest zone 启动
当前有两个网段:
外侧物理网段:192.168.1.0/24 Windows 主机:192.168.1.10 zone0 物理网口 eth0:192.168.1.20
内侧虚拟网段:192.168.200.0/24 zone0 虚拟网卡 tap0:192.168.200.1 zone1 虚拟网卡 eth0:192.168.200.2
zone0 在这里扮演两个角色:
- 它是 root zone,负责启动 zone1。
- 它也是 zone1 出网的网关和 NAT 路由器。
zone1 并没有直接拿到物理网卡。zone1 看到的 eth0 是 virtio-net 虚拟网卡,不是 dayu200 的真实以太网硬件。
为了让zone1能够访问不是本地网段 192.168.200.0/24 的地址,也就是外侧网段如Windows主机地址,需要加上默认路由,把包发给网关 192.168.200.1,并且从 eth0 这个接口发出去。
对于zone1:eth0 = zone1 的 virtio-net 前端网卡,192.168.200.1 = zone0 的 tap0 接下来在zone0的终端输入如下命令:
# Start dayu200 zone1 OpenHarmony with virtio-net and virtio-console.
echo "4 4 1 7" > /proc/sys/kernel/printk
cd /data/zone
mount -t proc proc /proc
mount -t sysfs sysfs /sys
# zone0/root OpenHarmony: create tap0 and NAT it through the real NIC.
# U-Boot TFTP uses board 192.168.1.20 <-> host 192.168.1.10, but OpenHarmony
# should configure the runtime NIC address again after boot.
ifconfig -a
ifconfig eth0 192.168.1.20 netmask 255.255.255.0 up
ping 192.168.1.10
mkdir -p /dev/net
mknod /dev/net/tun c 10 200
/data/zone/busybox tunctl -d tap0
tunctl -d tap0
tunctl -d -T tap0
/data/zone/busybox tunctl -t tap0
cat /sys/class/net/tap0/type
/data/zone/busybox ifconfig tap0 192.168.200.1 netmask 255.255.255.0 up
sysctl -w net.ipv4.ip_forward=1
netstat -rn
iptables -t nat -D POSTROUTING -s 192.168.200.0/24 -o eth0 -j MASQUERADE
iptables -t nat -A POSTROUTING -s 192.168.200.0/24 -o eth0 -j MASQUERADE
chmod 755 hvisor && chmod 644 hvisor.ko
insmod hvisor.ko
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
rm -f nohup.out
nohup ./hvisor virtio start zone1-ohos-virtio.json &
sleep 2
./hvisor zone start zone1-ohos.json
接着在zone1的命令行输入如下命令
# zone1/non-root OpenHarmony: configure the virtio-net interface.
echo "4 4 1 7" > /proc/sys/kernel/printk
mount -t proc proc /proc
mount -t sysfs sysfs /sys
ifconfig eth0 192.168.200.2 netmask 255.255.255.0 up
/data/zone/busybox route add default gw 192.168.200.1 dev eth0
ping 192.168.200.1
ping 192.168.1.10
可以看到zone1能成功通过virtio-net访问外网
并且在zone0中可以通过picocom建立与zone1的串口链接,在zone0中控制zone1的串口。
飞腾派SDK的获取
进入ieasy cloud官网,登录后选择飞腾派下载专区,依次选择5-系统镜像->飞腾派V3版本ubuntu镜像 250422(最新)进行下载。内核源码位于4-系统源码中。
准备好USB转TTL串口线(用于串口调试,串口线插入方式见飞腾派文档)、网线连接飞腾派与电脑、32GB的MicroSD卡并且使用win32diskimager烧录从官网下载的Ubuntu完整镜像(包含文件系统),拨码开关使用100让飞腾派从sd卡启动进入Ubuntu系统:

串口连接后,可通过MobaXterm软件进入调试窗口,选择新建Session->Serial。详细配置见飞腾派资料中的2-用户开发手册。
Ubuntu上Linux的最小镜像Image文件可通过链接下载,亦可以在进入飞腾派的Ubuntu系统上找到,镜像文件和设备树都位于Linux系统的/boot目录下。
编译 Hvisor 和设备树
-
和其他开发板类似,拉取 hvisor 最新代码,仓库地址:https://github.com/syswonder/hvisor。进入目录后编译 hvisor:
make BID=aarch64/phytium-pi LOG=info编译产生的文件位于
target/aarch64-unknown-none/debug/hvisor.bin -
进入
platform/aarch64/phytium-pi/image/dts目录,运行make对设备树进行编译,得到phytium-pi-board-v2.dtb、linux1.dtb、linux2.dtb。
制作文件系统
由于之前已经烧录到SD卡了,所以zone0的文件系统就是sd卡上之前烧录的文件系统,为了启动zone1还需要zone1-Linux的文件系统,有两种方式获取:
1.下载文件系统。 2.参考基于ubuntu_base构建文件系统自行制作文件系统。
通过 TFTP 启动 RootLinux
如果已经搭建了 TFTP 服务器,那么可以以方便的方式快速启动 RootLinux,具体而言:
- 将 Image、linux1.dtb、hvisor.bin、phytium-pi-board-v2.dtb 复制到 ~/tftp 文件夹下
- 用网线连接主机与开发板,配置主机ip为
192.168.1.10,子网掩码255.255.255.0。 - 直接开机并连接串口即可,uboot 将自动下载 tftp 文件夹下的内容并启动。
如果有搭建需求,可以参考嵌入式平台快速开发-Tftp 服务器搭建与配置。如果你是通过wsl的Ubuntu搭建TFTP服务器,通过网线与飞腾派开发板进行连接。由于WSL使用Windows的网卡配置,因此需要在Windows下修改以太网的ip地址,如果连不上可以试试关闭windows防火墙。
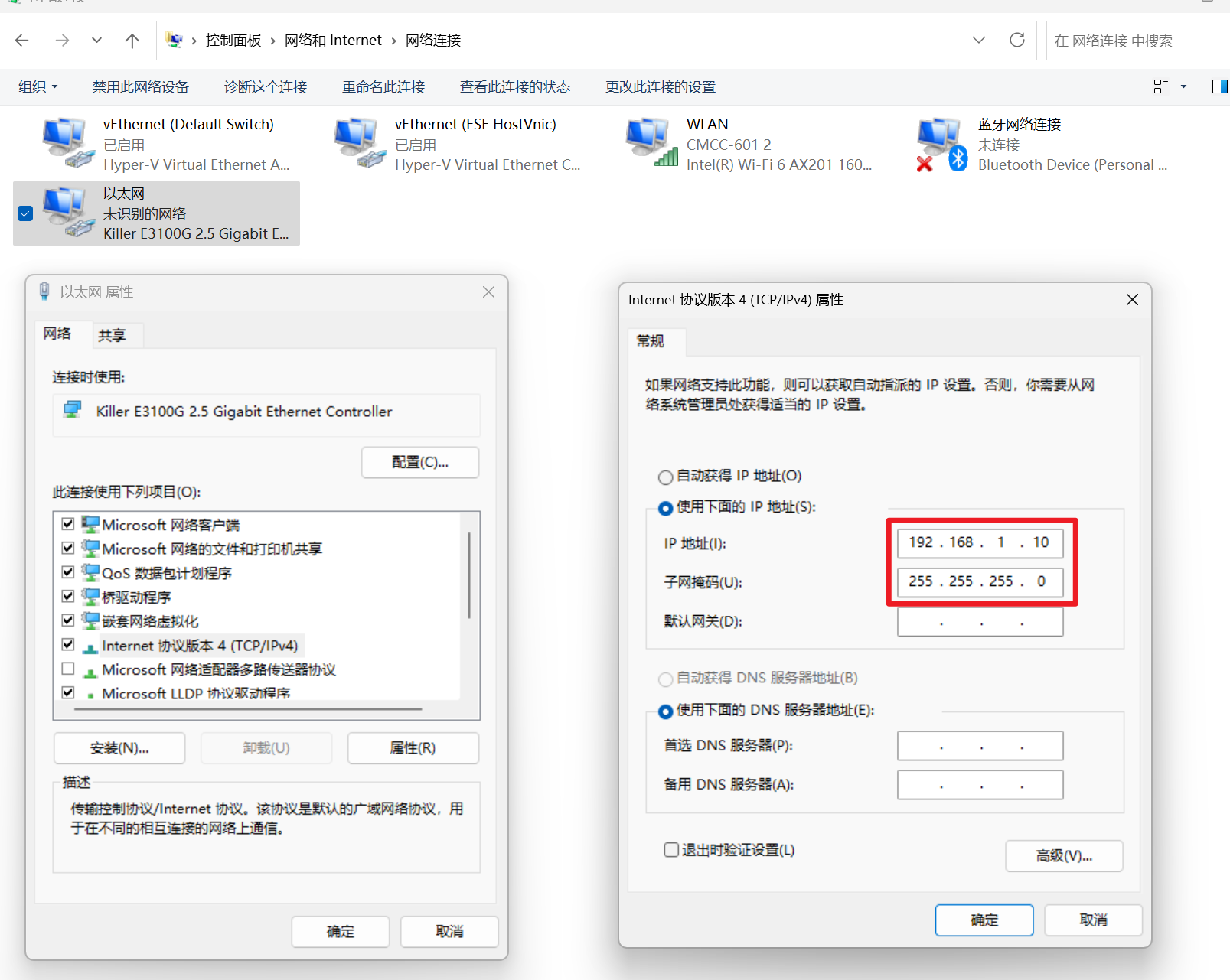
启动 Zone0-Linux
下载现成的配置文件
在飞腾派开发板上电后,快速连续敲击空格打断uboot启动:
执行启动命令
执行以下命令:
setenv serverip 192.168.1.10; setenv ipaddr 192.168.1.20; setenv loadaddr 0x90100000; setenv fdt_addr 0x90000000; setenv zone0_kernel_addr 0xa0400000; setenv zone0_fdt_addr 0xa0000000; tftp ${loadaddr} ${serverip}:hvisor.bin;
tftp ${fdt_addr} ${serverip}:phytium-pi-board-v2.dtb; tftp ${zone0_kernel_addr} ${serverip}:Image; tftp ${zone0_fdt_addr} ${serverip}:linux1.dtb; bootm ${loadaddr} - ${fdt_addr};
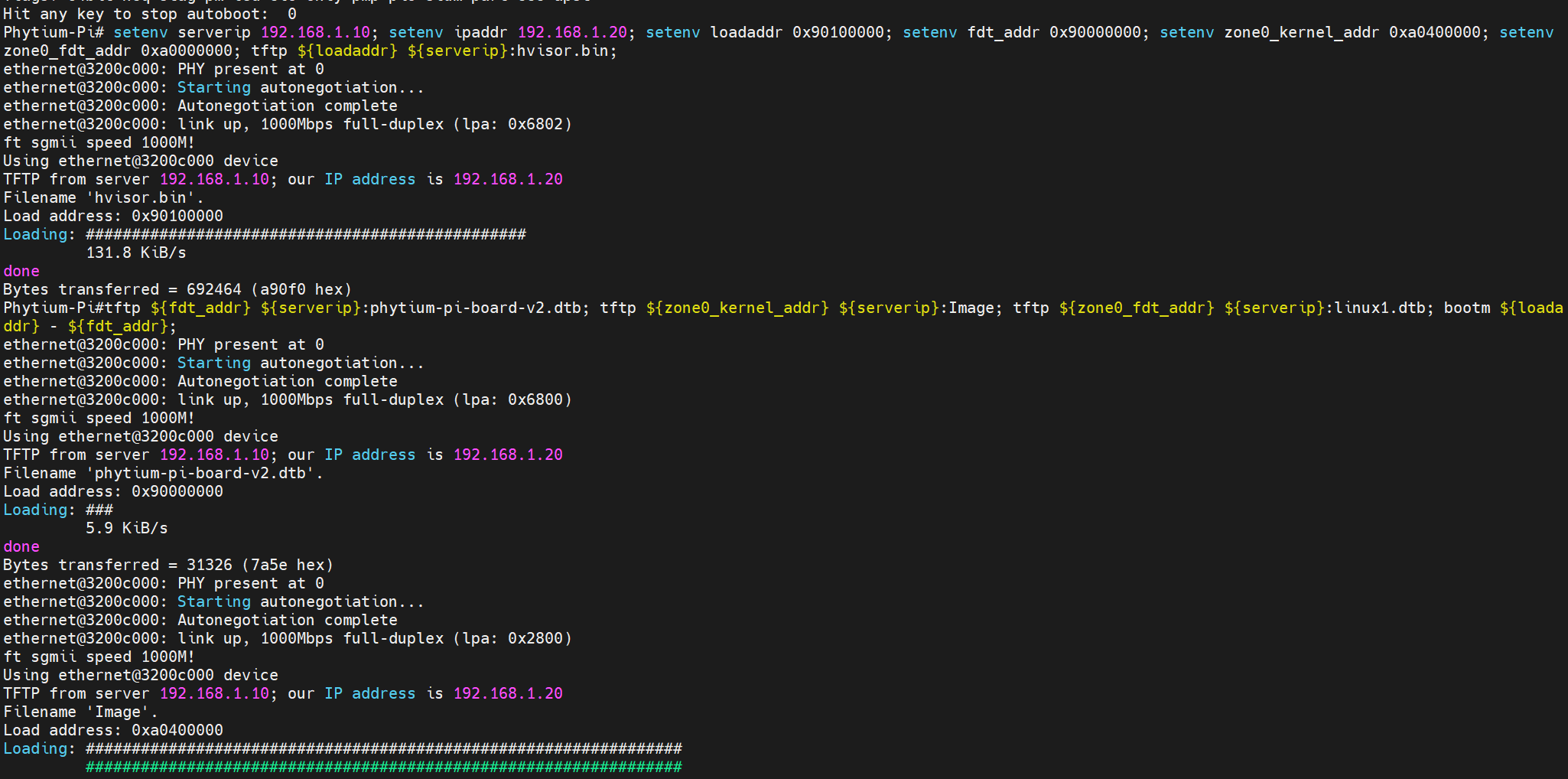
进入如下界面表示zone0 linux启动成功了:
启动Zone1-linux
编译 hvisor-tool
拉取 Hvisor-tool 的最新代码:https://github.com/syswonder/hvisor-tool/tree/main,进行编译:
make all ARCH=arm64 LOG=LOG_INFO KDIR=Phytium内核源码 VIRTIO_GPU=n ROOT=/path/to/target_rootfs
其中ROOT为Phytium根文件系统的路径,可以把之前下载的镜像mount到目录上。
更多细节请参考 hvisor-tool 的 Readme.md。编译结果位于output/hvisor和output/hvisor.ko。亦可在网盘链接里找到已经编译好的文件。
文件准备
在飞腾派的SD卡上的/home/user/zone1目录提前准备好如下文件(可以通过sd卡启动Linux,然后scp拷贝到该目录下:
- hvisor、hvisor.ko
- Image、linux2.dtb、rootfs2.ext4(zone1-Linux的文件系统)
- zone1-linux.json、zone1-linux-virtio.json(位于hvisor项目的
platform/aarch64/phytium-pi/configs目录)
执行启动命令
启动zone0-Linux后,在 /home/user/zone1 目录下执行下述命令(可以把这些命令统一写成start.sh然后直接执行该脚本)
chmod +777 hvisor
chmod +777 hvisor.ko
insmod hvisor.ko
rm nohup.out
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
mount -t proc proc /proc
mount -t sysfs sysfs /sys
nohup ./hvisor virtio start zone1-linux-virtio.json &
sleep 1
./hvisor zone start zone1-linux.json
依次执行如下命令,检查是否能成功进入zone1-Linux的终端
script /dev/null
screen /dev/pts/0
退出可按ctrl+A再按K键。
FPGA zcu102
# Before, Install vivado 2022.2 software
# Ubuntu 20.04 can work fine
sudo apt update
git clone https://github.com/U-interrupt/uintr-rocket-chip.git
cd uintr-rocket-chip
git submodule update --init --recursive
export RISCV=/opt/riscv64
git checkout 98e9e41
vim digilent-vivado-script/config.ini # Env Config
make checkout
make clean
make build
# Use vivado to open the vivado project, then change the top file, run synthesis, run implementation, generate bitstream.
# Connect the zcu102 - Jtag and Uart on your PC.
# Use dd command to flash the image include boot and rootfs part.
# Change the boot button mode to (On Off Off Off)
# Boot the power.
sudo screen /dev/ttyUSB0 115200 # Aarch64 Core Uart
sudo screen /dev/ttyUSB2 115200 # Riscv Core Uart
# On /dev/ttyUSB0
cd uintr-rocket-chip
./load-and-reset.sh
# Focus on ttyUSB2, then you will see the Riscv Linux Boot Msg.
在RocketChip中开启H扩展
vim path/to/repo/common/src/main/scala/Configs.scala
change
class UintrConfig extends Config(
new WithNBigCores(4) ++
new WithNExtTopInterrupts(6) ++
new WithTimebase((BigInt(10000000))) ++ // 10 MHz
new WithDTS("freechips.rocketchip-unknown", Nil) ++
new WithUIPI ++
new WithCustomBootROM(0x10000, "../common/boot/bootrom/bootrom.img") ++
new WithDefaultMemPort ++
new WithDefaultMMIOPort ++
new WithDefaultSlavePort ++
new WithoutTLMonitors ++
new WithCoherentBusTopology ++
new BaseSubsystemConfig
)
to
class UintrConfig extends Config(
new WithHypervisor ++
new WithNBigCores(4) ++
new WithNExtTopInterrupts(6) ++
new WithTimebase((BigInt(10000000))) ++ // 10 MHz
new WithDTS("freechips.rocketchip-unknown", Nil) ++
new WithUIPI ++
new WithCustomBootROM(0x10000, "../common/boot/bootrom/bootrom.img") ++
new WithDefaultMemPort ++
new WithDefaultMMIOPort ++
new WithDefaultSlavePort ++
new WithoutTLMonitors ++
new WithCoherentBusTopology ++
new BaseSubsystemConfig
)
qemu bosc-kmh hvisor
hvisor 更改为单核
qemu参数 smp 改为1
const.rs 中的 MAX_CPU_NUM 改为1
qemu_riscv64.rs 中的
pub const ROOT_ZONE_CPUS: u64 = (1 << 0);
修改: hvisor的二阶段映射
//src/arch/riscv64/s2pt.rs
attr |= Self::VALID | Self::USER | Self::ACCESSED | Self::DIRTY;//stage 2 page table must user
编译linux内核
git clone git@gitlab.bosoc.cc:openxiangshan/riscv-linux.git # 下载源码仓库
git checkout -b devel origin/devel # 切换分支到devel
# 注意: 发人员请基于上述主开发分支devel最新的HEAD进行开始工作
export CROSS_COMPILE=riscv64-unknown-linux-gnu- # 指定编译器文件前缀
export ARCH=riscv # 指定架构
export PATH=$PATH:/home/ran/toolchain/gcc12/riscv-toolchain-20230425/bin # 工具链路径
make distclean # 清理旧的编译产物, 此命令会导致重新编译所有文件, 请酌情使用
make defconfig xiangshan.config # 编译生成.config
gedit .config
CONFIG_BLK_DEV_INITRD=y
CONFIG_INITRAMFS_SOURCE="~/fdisk/kvm/rootfs_kvm_riscv64.cpio"
make
包含文件系统的 Image 打包到 hvisor.bin 中
打包完成后的fw_payload.bin有250M,更改内存布局缩小到78M
// config
#[link_section = ".img1"]
#[used]
pub static GUEST1_KERNEL: [u8; include_bytes!("../images/riscv64/kernel/Image").len()] =
*include_bytes!("../images/riscv64/kernel/Image");
#[link_section = ".dtb1"]
#[used]
pub static GUEST1_DTB: [u8; include_bytes!("../images/riscv64/devicetree/linux.dtb").len()] =
*include_bytes!("../images/riscv64/devicetree/linux.dtb");
. = . + 0x2000000;
gdtb = .;
. = 0x82000000;
.dtb1 : {
KEEP(*(.dtb1))
}
. = ALIGN(4K);
. = 0x83000000;
.img1 : {
KEEP(*(.img1))
}
按照linker脚本和kmh_v2_1core.dtb的内容,修改内存布局,PLIC,串口配置
//src/platform/qemu_riscv64.rs
pub const ROOT_ZONE_DTB_ADDR: u64 = 0x82000000;
pub const ROOT_ZONE_KERNEL_ADDR: u64 = 0x83000000;
pub const ROOT_ZONE_ENTRY: u64 = 0x83000000;
pub const ROOT_ZONE_CPUS: u64 = 1 << 0;
...
pub const ROOT_ZONE_MEMORY_REGIONS: [HvConfigMemoryRegion; 2] = [
HvConfigMemoryRegion {
mem_type: MEM_TYPE_RAM,
physical_start: 0x81000000,
virtual_start: 0x81000000,
size: 0x08000000,
}, // ram
HvConfigMemoryRegion {
mem_type: MEM_TYPE_IO,
physical_start: 0x310b0000,
virtual_start: 0x310b0000,
size: 0x10000,
}, // serial
];
将hvisor.bin 嵌入opensbi fw_payload
FPGA上运行时,使用打包好的软件镜像opensbi fw_payload运行
cd ~/source/opensbi && \
make PLATFORM=generic \
FW_PAYLOAD_PATH=/home/dorso/work/hvisor/target/riscv64gc-unknown-none-elf/debug/hvisor.bin \
FW_FDT_PATH=/home/dorso/source/opensbi/kmh-v2-1core.dtb
qemu bosc-kmh运行
QEMU := ~/source/qemu-devel/build/qemu-system-riscv64
# bosc的cpu不手动指定
QEMU_ARGS := -machine bosc-kmh
QEMU_ARGS += -nographic
QEMU_ARGS += -smp 1
QEMU_ARGS += -m 2G
# 指定制作好的fw_payload作为bios
QEMU_ARGS += -bios ~/source/opensbi/build/platform/generic/firmware/fw_payload.elf
FPGA 运行 hvisor
在opensbi目录下
./bin2fpgadata -i build/platform/generic/firmware/fw_payload.bin
执行成功后生成的软件镜像文件data.txt位于当前源码根目录
source /home/tools/Xilinx/Vivado/2020.2/settings64.sh
# 确认与FPGA相连的Linux 服务器已经通过上述source命令并执行了hw_server命令以启动相关服务, 然后本x86_64 Linux 电脑将使用下述命令中tcl脚本与后台服务器建立通信
vivado -mode batch -source ../onboard-ai1-fpga81-remote.tcl -tclargs <path to bitstream files>/ ./data.txt
其中<path to bitstream files>为使用的硬件镜像路径
如何编译
Rust环境配置
可以参考Rust 语言圣经配置Rust开发环境,也可参考如下的操作。
1. 安装 RustUp 与 Cargo
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | \
sh -s -- -y --no-modify-path --profile minimal --default-toolchain nightly
2. 安装工具链
目前项目使用的工具链如下:
- Rust nightly-2024-05-05
- rustfmt
- clippy
- cargo-binutils
- rust-src
- llvm-tools-preview
- taget: aarch64-unknown-none
可以自行检查是否安装了这些工具,也可以使用以下命令安装:
(1) 安装 toml-cli 和 cargo-binutils
cargo install toml-cli cargo-binutils
(2) 安装目标平台交叉编译工具链
rustup target add aarch64-unknown-none
(3) 解析 rust-toolchain.toml 安装 Rust 工具链
RUST_VERSION=$(toml get -r rust-toolchain.toml toolchain.channel) && \
Components=$(toml get -r rust-toolchain.toml toolchain.components | jq -r 'join(" ")') && \
rustup install $RUST_VERSION && \
rustup component add --toolchain $RUST_VERSION $Components
编译hvisor
首先将 hvisor 代码仓库 拉到本地,并切换到 dev 分支。
git clone -b dev https://github.com/syswonder/hvisor.git
运行下面这条命令进行编译:
make all
如何启动 Root Linux
安装QEMU
1. 安装依赖
sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \
gawk build-essential bison flex texinfo gperf libtool patchutils bc \
zlib1g-dev libexpat-dev pkg-config libglib2.0-dev libpixman-1-dev libsdl2-dev \
git tmux python3 python3-pip ninja-build
注意,上述依赖包可能不全,例如:
- 出现
ERROR: pkg-config binary 'pkg-config' not found时,可以安装pkg-config包;- 出现
ERROR: glib-2.48 gthread-2.0 is required to compile QEMU时,可以安装libglib2.0-dev包;- 出现
ERROR: pixman >= 0.21.8 not present时,可以安装libpixman-1-dev包。
若生成设置文件时遇到报错
ERROR: Dependency "slirp" not found, tried pkgconfig:下载 https://gitlab.freedesktop.org/slirp/libslirp 包,并按 README 安装即可。
2. 条件编译并安装QEMU
注意,QEMU 需要使用 9.0.1 或更高版本,以正常使用 PCI 虚拟化。
wget https://download.qemu.org/qemu-9.0.1.tar.xz
tar -xvf qemu-9.0.1.tar.xz
cd qemu-9.0.1
# 生成配置并编译
./configure --enable-kvm --enable-slirp --enable-debug --target-list=aarch64-softmmu,x86_64-softmmu
make -j$(nproc)
--enable-kvm表示启用 Kernel-based Virtual Machine 加速支持;--enable-slirp表示启用用户态网络协议栈(SLIRP),允许虚拟机无需主机 root 权限即可访问网络。--enable-debug表示编译带调试信息的版本--target-list=aarch64-softmmu,x86_64-softmmu表示只编译 ARM64 和 x86_64 的系统模拟器(softmmu表示全系统模拟),如果需要其他架构的 QEMU,可以参考QEMU官方文档。
3. 配置qemu的环境变量
编辑 ~/.bashrc 文件(如果启用其他shell则编辑对应文件,如使用zsh则编辑~/.zshrc文件),在文件的末尾加入如下代码:
# 请注意,qemu-9.0.1 的父目录可以随着你的实际安装位置灵活调整。另外需要把其放在 $PATH 变量开头。
export PATH="/path/to/qemu-9.0.1/build:$PATH"
随后即可在当前终端 source ~/.bashrc 更新系统路径,或者直接重启一个新的终端。
4. 测试QEMU是否安装成功
qemu-system-aarch64 --version
可以将aarch64替换为其他架构以检查对应版本的qemu是否正确安装。
启动Root Linux
1. 准备内核镜像
这里以 Linux Kernel 5.4 为例展示内核镜像的编译方法。
首先需要安装对应架构的交叉编译器,如果是aarch64架构可安装aarch64-none-linux-gnu-10.3;如果是riscv64架构可安装riscv-gnu-toolchain;如果是loongarch64架构可安装loongarch64-unknown-linux-gnu-工具链。下面以aarch64架构为例。
# CROSS_COMPILE 路径需要根据安装交叉编译器的路径进行更改
CROSS_COMPILE_PATH="<路径>/bin"
# 下载 linux 5.4 源码
git clone https://github.com/torvalds/linux -b v5.4 --depth=1
cd linux
git checkout v5.4
# 生成默认的编译配置
CROSS_COMPILE_PREFIX=${CROSS_COMPILE_PATH}/aarch64-none-linux-gnu-
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} defconfig
# 启用 CONFIG_BLK_DEV_RAM,以启用 RAM 块设备支持
./scripts/config --enable CONFIG_BLK_DEV_RAM
# 启用 CONFIG_IPV6 和 CONFIG_BRIDGE,以支持在 root linux 中创建网桥和 tap 设备
./scripts/config --enable CONFIG_IPV6
./scripts/config --enable CONFIG_BRIDGE
# 编译
make ARCH=arm64 CROSS_COMPILE=${CROSS_COMPILE_PREFIX} Image -j$(nproc)
如果编译 linux 时报错:
/usr/bin/ld: scripts/dtc/dtc-parser.tab.o:(.bss+0x20): multiple definition of `yylloc'; scripts/dtc/dtc-lexer.lex.o:(.bss+0x0): first defined here则修改 linux 文件夹下
scripts/dtc/dtc-lexer.lex.c,在YYLTYPE yylloc;前增加extern。再次编译,发现会报错openssl/bio.h: No such file or directory,此时执行sudo apt install libssl-dev。
编译过程中会出现:
RAM block device support (BLK_DEV_RAM) [Y/n/m/?] y Default number of RAM disks (BLK_DEV_RAM_COUNT) [16] (NEW) Default RAM disk size (kbytes) (BLK_DEV_RAM_SIZE) [4096] (NEW)即配置具体参数,直接回车采用默认值即可。
编译完毕,内核镜像位于 arch/arm64/boot/Image。
将镜像文件放置于platform/<架构>/<平台名>/image/kernel/目录下并命名为Image,例如platform/aarch64/qemu-gicv3/image/kernel。
2. 准备Root文件系统
可以参考如下方法使用 Ubuntu 22.04 自制根文件系统。以aarch64架构为例,如果编译的是其他架构的 qemu 需换成对应架构。
# QEMU 路径,需要根据之前安装时的路径进行更改
QEMU_PATH="<路径>/build/qemu-system-aarch64" # 这里换成对应架构
# 下载 ubuntu base
wget http://cdimage.ubuntu.com/ubuntu-base/releases/22.04/release/ubuntu-base-22.04.5-base-arm64.tar.gz
# 创建 rootfs,用于挂载后续的 rootfs1.img
mkdir -p rootfs
# 创建一个 1 GiB 大小的 rootfs1.img,可以通过修改 count 修改 img 大小
dd if=/dev/zero of=rootfs1.img bs=1M count=1024 oflag=direct
# 格式化为 ext4 文件系统
mkfs.ext4 rootfs1.img
# 挂载 rootfs1.img
sudo mount -t ext4 rootfs1.img rootfs/
# 将 ubuntu.tar.gz 的内容解压到 rootfs
sudo tar -xzf ubuntu-base-22.04.5-base-arm64.tar.gz -C rootfs/
# 让 rootfs 绑定和获取物理机的一些信息和硬件
sudo cp "${QEMU_PATH}" rootfs/usr/bin/
sudo cp /etc/resolv.conf rootfs/etc/resolv.conf
sudo mount -t proc /proc rootfs/proc
sudo mount -t sysfs /sys rootfs/sys
sudo mount -o bind /dev rootfs/dev
sudo mount -o bind /dev/pts rootfs/dev/pts
# 将文件系统切换到 rootfs
sudo chroot rootfs # 执行该指令可能会报错,请参考下面的解决办法
# 在 rootfs 中安装必要的软件包
apt-get update
apt-get install git sudo vim bash-completion \
kmod net-tools iputils-ping resolvconf ntpdate screen
apt-get clean
# 退出 rootfs
exit
# 卸载 rootfs
sudo umount rootfs/proc
sudo umount rootfs/sys
sudo umount rootfs/dev/pts
sudo umount rootfs/dev
sudo umount rootfs
此时可以顺便创建后续要用到的
rootfs2.img作为 NonRoot Linux 的根文件系统,其大小应适当减少,以便放入rootfs1.img中。QEMU_PATH="<路径>/build/qemu-system-aarch64" # 这里换成对应架构 # 创建 rootfs2.img,其大小适当减少到 256 MiB dd if=/dev/zero of=rootfs2.img bs=1M count=256 oflag=direct mkfs.ext4 rootfs2.img sudo mount -t ext4 rootfs2.img rootfs/ sudo tar -xzf ubuntu-base-22.04.5-base-arm64.tar.gz -C rootfs/ sudo cp "${QEMU_PATH}" rootfs/usr/bin/ sudo cp /etc/resolv.conf rootfs/etc/resolv.conf sudo mount -t proc /proc rootfs/proc sudo mount -t sysfs /sys rootfs/sys sudo mount -o bind /dev rootfs/dev sudo mount -o bind /dev/pts rootfs/dev/pts sudo umount rootfs/proc sudo umount rootfs/sys sudo umount rootfs/dev/pts sudo umount rootfs/dev sudo umount rootfs
最后卸载挂载,完成根文件系统的制作。
执行
sudo chroot rootfs时,如果报错chroot: failed to run command '/bin/bash': Exec format error,可以执行指令:sudo apt-get install qemu-user-static sudo update-binfmts --enable qemu-aarch64 # 这里换成对应的架构名称
将 Root 文件系统放置于platform/<架构>/<平台名>/image/virtdisk/目录下并命名为rootfs1.ext4,例如platform/aarch64/qemu-gicv3/image/virtdisk/rootfs1.ext4。
3. 准备设备树
切换到platform/<架构>/<平台名>/image/dts/目录下,下面以platform/aarch64/qemu-gicv3/image/dts/为例,执行make all命令,该命令会自动编译当前目录下所有.dts文件为.dtb文件,确保设备树源文件被转换为目标硬件可用的二进制格式。
cd platform/aarch64/qemu-gicv3/image/dts/
make all
cd - # 回到 hvisor 目录
4. 启动QEMU
在hviosr目录下执行执行make run命令启动 hvisor,可通过指定ARCH=<架构>调整架构、BOARD=<平台名>调整平台名、LOG=<日志等级>调整日志输出等级,例如
make ARCH=aarch64 LOG=info BOARD=qemu-gicv3 run
5. 进入 uboot 启动界面
启动 hvisor 后将自动加载uboot,等待uboot加载完成后,该界面下执行
bootm 0x40400000 - 0x40000000
该启动命令会从物理地址 0x40400000 启动 hvisor,0x40000000 本质上已无用,但因历史原因仍然保留。hvisor 启动时,会自动启动 root linux(用于管理的 Linux),并进入 root linux 的 shell 界面,root linux 即为 zone0,承担管理工作。
如何启动 NonRoot Linux(Zone1 Linux)
使用 hvisor-tool 启动 NonRoot Linux。
# Linux 源代码路径
LINUX_PATH="<路径>/linux"
git clone https://github.com/syswonder/hvisor-tool.git
cd hvisor-tool
make all ARCH=arm64 LOG=LOG_INFO KDIR="${LINUX_PATH}"
请务必保证 hvisor 中的 root linux 镜像也是由编译 hvisor-tool 时参数选项中的 Linux 源代码目录编译产生。
请务必保证 hvisor-tool 编译时采用的 linux header 版本与 root linux 的 linux header 版本一致,否则 hvisor-tool 的 driver 可能会无法加载。 可以通过使用 root linux 相同的交叉编译工具链进行编译。
编译完成后,需要将 hvisor-tool 的可执行文件 tools/hvisor 和内核模块 driver/hvisor.ko 复制到 root linux 的根文件系统中启动 zone1 linux 的目录,例如 /root,再同时将 zone1 的根文件系统、内核镜像、以及编译后的设备树放在同一目录。
还需要将 hvisor-tool 的配置文件放入文件系统中,文件名需要保持一致,配置文件位于platform/<架构>/<平台名>/configs/目录下。
以架构为aarch64、平台名为qemu-gicv3为例,则配置文件为platform/aarch64/qemu-gicv3/configs/zone1-linux-virtio.json 和 platform/aarch64/qemu-gicv3/configs/zone1-linux.json。
下面命令以aarch64架构为例,若为其他架构请更改命令对应的部分。
# 回到创建的 root linux 根文件系统时的目录
LINUX_PATH="<路径>/linux"
HVISOR_PATH="<路径>/hvisor"
HVISOR_TOOL_PATH="<路径>/hvisor-tool"
# 挂载
sudo mount -t ext4 rootfs1.img rootfs/
# 复制 hvisor-tool 的 driver/hvisor.ko 和 tools/hvisor
sudo cp "${HVISOR_TOOL_PATH}/driver/hvisor.ko" rootfs/root/
sudo cp "${HVISOR_TOOL_PATH}/tools/hvisor" rootfs/root/
# 复制`platform/<架构>/<平台名>/configs/`目录下的 hvisor-tool 的配置文件到 root 路径下
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/configs/zone1-linux-virtio.json" \
rootfs/root/zone1-linux-virtio.json
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/configs/zone1-linux.json" \
rootfs/root/zone1-linux.json
# 复制 zone1 linux 的根文件系统、内核镜像、以及编译后的设备树
sudo cp rootfs2.img \
rootfs/root/rootfs2.ext4
sudo cp "${LINUX_PATH}/arch/arm64/boot/Image" \
rootfs/root/Image
sudo cp "${HVISOR_PATH}/platform/aarch64/qemu-gicv3/image/dts/zone1-linux.dtb" \
rootfs/root/zone1-linux.dtb
# 卸载
sudo umount rootfs
之后在 QEMU 上即可通过 root linux 启动 zone1-linux。具体命令如下。
在 hvisor 目录下执行
make ARCH=<架构> LOG=<日志等级> BOARD=<平台名> run
例如
make ARCH=aarch64 LOG=info BOARD=qemu-gicv3 run
接下来启动 root linux
bootm 0x40400000 - 0x40000000
cd root
insmod hvisor.ko
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mkdir -p /dev/pts
mount -t devpts devpts /dev/pts
rm nohup.out
# 启动 zone1-linux 的 virtio
nohup ./hvisor virtio start zone1-linux-virtio.json &
# 启动 zone1-linux
./hvisor zone start zone1-linux.json && \
cat nohup.out | grep "char device" && \
script /dev/null
如果显示 virtio 出现 WARNING 或者 ERROR,可以查看 nohup.out 查看详细信息,或者使用 dmesg 命令查看内核日志。
如何启动Non Root RTOS
在RK3588上启动AArch64/AArch32 Zephyr虚拟机
目前hvisor支持在RK3588 PC开发板上,启动Zephyr作为Non Root RTOS虚拟机。Zephyr可以以两种模式启动:AArch32和AArch64。
具体启动与移植相关的文档,请见:在rk3588上通过hvisor启动64/32位zephyr
在NXP imx8mp上启动Xiuos
NXP imx8mp开发板上可在M核上启动Xiuos,并通过RPMsg与Linux通信,具体流程请见:在NXP上通过RPMsg实现Linux与Xiuos通信
Zone的配置和管理
hvisor项目作为一款轻量级的hypervisor,它使用了Type-1架构,允许在硬件之上直接运行多个虚拟机(zones)。下面是对zone配置和管理的关键点的详细说明:
资源分配
资源如CPU、内存、设备和中断对每个zone都是静态分配的,这意味着一旦分配,这些资源就不会在zones之间动态调度。
Root Zone配置
根zone的配置是硬编码在hvisor内部的,以Rust语言编写,并表现为一个C风格的结构体HvZoneConfig。这个结构体包含了zone ID、CPU数量、内存区域、中断信息、内核和设备树二进制(DTB)的物理地址与大小等关键信息。
Non-root Zones配置
非root zones的配置则存储在root linux的文件系统中,通常以JSON格式表示。例如:
{
"arch": "arm64",
"zone_id": 1,
"cpus": [2, 3],
"memory_regions": [
{
"type": "ram",
"physical_start": "0x50000000",
"virtual_start": "0x50000000",
"size": "0x30000000"
},
{
"type": "io",
"physical_start": "0x30a60000",
"virtual_start": "0x30a60000",
"size": "0x1000"
},
{
"type": "virtio",
"physical_start": "0xa003c00",
"virtual_start": "0xa003c00",
"size": "0x200"
}
],
"interrupts": [61, 75, 76, 78],
"kernel_filepath": "./Image",
"dtb_filepath": "./linux2.dtb",
"kernel_load_paddr": "0x50400000",
"dtb_load_paddr": "0x50000000",
"entry_point": "0x50400000"
}
arch字段指定了目标架构(例如arm64)。cpus是一个列表,指明了分配给该zone的CPU核心ID。memory_regions描述了不同类型的内存区域及其物理和虚拟起始地址与大小。interrupts列出了分配给zone的中断号。kernel_filepath和dtb_filepath分别指明了内核和设备树二进制文件的路径。kernel_load_paddr和dtb_load_paddr则是内核和设备树二进制在物理内存中的加载地址。entry_point指定了内核的入口点地址。
root linux的管理工具负责读取JSON配置文件并将其转换为C风格的结构体,随后传递给hvisor以启动非root zones。
命令行工具
命令行工具是附属于hvisor的管理工具,用于在管理虚拟机Root Linux上创建和关闭其他虚拟机,并负责启动Virtio守护进程,提供Virtio设备模拟。
仓库地址位于hvisor-tool。更详细的内容请见对应仓库README。
如何配置
Non-root Zones的配置可以参考:Non-root Zones 配置文档。
virtio的配置可以参考:virtio 配置文档。
如何使用
hvisor-tool的使用可以参考:管理工具使用文档。
hvisor-tool在qemu-aarch64下的使用示例可以参考:qemu-aarch64下的使用示例。
如果使用virtio设备,请先启动virtio守护进程,然后再启动Non-root Zones。
VirtIO配置文档
这里说明hvisor-tool如何配置virtio backend,介绍各字段的含义。
以下为配置示例:
{
"zones": [
{
"id": 1,
"memory_region": [
{
"zone0_ipa": "0x50000000",
"zonex_ipa": "0x50000000",
"size": "0x30000000"
}
],
"devices": [
{
"type": "net",
"addr": "0xa003600",
"len": "0x200",
"irq": 75,
"tap": "tap0",
"mac": [
"0x02",
"0x00",
"0x00",
"0x00",
"0x01",
"0x01"
],
"status": "enable"
},
{
"type": "console",
"addr": "0xa003800",
"len": "0x200",
"irq": 76,
"status": "enable"
},
{
"type": "blk",
"addr": "0xa003c00",
"len": "0x200",
"irq": 78,
"img": "rootfs2.ext4",
"status": "enable"
}
]
}
]
}
由于virtio需要前端和后端通过共享内存交换数据,virtio的virtqueue以及数据用buffer均分配在Guest的内存中,zone0上运行的virtio-backend需要能够访问zonex的内存以交换数据。
注意先启动virtio backend,再启动使用virtio设备的zonex。
相关字段说明:
id字段指定了zonex的ID,用于唯一标识该zonex。memory_region描述了虚拟机的内存区域,包括中间物理地址(IPA)和大小。zone0_ipa表示zone0访问zonex内存的起始IPA。zonex_ipa表示zonex内存区域的起始IPA。size表示zonex内存区域的大小。devices描述了 zone0 提供的 virtio 设备,包括网络设备、控制台设备、块设备和 GPU 设备。type字段指定了设备的类型,包括net、console、blk和gpu。addr字段指定了设备的MMIO起始地址(需要和zonex中的设备树匹配)。len字段指定了设备的MMIO长度。irq字段指定了设备使用的中断号。tap字段指定了虚拟网卡的名称,需要提前在root linux中创建网桥,并将该tap设备添加到网桥中。mac字段指定了该虚拟网卡的MAC地址。img字段指定了块设备的镜像文件路径。width字段指定了 virtio-gpu 的 scanout 宽度(仅gpu设备需要)。height字段指定了 virtio-gpu 的 scanout 高度(仅gpu设备需要)。status字段指定了设备的状态,包括enable和disable。
virtio不同设备的实现,参考:
更多内容请详见:hvisor-tool-README
Hvisor 虚拟机间通信协议规范
基本协议
基本协议是指所有通信协议都需要遵循的规范。
配置⽂件格式
每个参与通信的zone必须在⾃⼰的配置⽂件中增加共享内存区域的配置,例如:
"ivc_configs": [
{
"ivc_id": 0,
"peer_id": 1,
"control_table_ipa": "0xd0000000",
"shared_mem_ipa": "0xd0001000",
"rw_sec_size": "0",
"out_sec_size": "0x1000",
"interrupt_num": 66,
"max_peers": 2
},
],
ivc_configs是⼀个数组,每个元素规定⼀个通信区域,⼀个zone最多可以有2个通信区域:
- ivc_id:inter vm communication id,⼀起通信的zones的ivc_id必须相同。
- peer_id:每个参与通信的zone称为peer,这⾥指定peer的编号。
- control_table_ipa:control table的IPA起始地址。
- shared_mem_ipa:共享内存IPA起始地址。
- rw_sec_size:read/write section的⼤⼩。
- out_sec_size:output section的⼤⼩
- interrupt_num:该zone通信时⽤到的中断号,注意该中断号需要添加到配置⽂件中的 interrupts属性中
- max_peers:该通信区域中,参与通信的zone数量的最⼤值。
控制表格式
控制表⽤于zone参与⼀个通信区域的通信。虚拟机通过hypercall可获取共享内存的地址、控制表的地址和对应的ivc_id。
// 以下为只读字段
ivc_id:u32,指⽰该控制表所属的ivc id
max_peers: u32,指⽰ivc id下的通信区域最多⽀持的peer数量
RW Sec Size: u32,指⽰Read/Write Section⼤⼩
Out Sec Size:u32,指⽰Output Section⼤⼩
peer id:u32,该zone在该通信区域下的peer id
// 以下为只写字段
ipi_invoke:u32,写⼊peer id,向该peer发送中断通知
共享内存格式
共享内存的基本格式:
+-----------------------------+ -
| | :
| Output Section for peer n-1 | : Output Section Size
| (n = Maximum Peers) | :
+-----------------------------+ -
: :
: :
: :
+-----------------------------+ -
| | :
| Output Section for peer 1 | : Output Section Size
| | :
+-----------------------------+ -
| | :
Output Section for peer 0 : Output Section Size
| | :
+-----------------------------+ -
| | :
| Read/Write Section | : RW Section Size
| | :
+-----------------------------+ <-- Shared memory base address
共享内存分有两个区域:RW Section和Output Section。
- RW Section:对所有peers均可读写,⼤⼩由配置⽂件指定,可以为0。可⽤于多个peer通信时互 斥机制。
- Output Section:每个peer均有⼀个Output Section,且⼤⼩相同,由配置⽂件指定⼤⼩。Output Section for peer x对于peer x可读可写,对于其他peers只读,⽤于peer x向其他peer发送 数据使⽤。
虚拟机与共享内存交互机制
虚拟机需要执⾏id为5的hypercall,获取该虚拟机可进⾏通信的信息,格式为:
struct ivc_info {
__u64 len; // 以下各个数组的实际⻓度,也是通信域的个数
__u64 ivc_ct_ipas[CONFIG_MAX_IVC_CONFIGS]; // control table 控制表的ipa
__u64 ivc_shmem_ipas[CONFIG_MAX_IVC_CONFIGS]; // 共享内存ipa
__u32 ivc_ids[CONFIG_MAX_IVC_CONFIGS]; // 通信域id,ivc id
__u32 ivc_irqs[CONFIG_MAX_IVC_CONFIGS]; // 各个通信域下,该zone对应的物理中断号
}__attribute__((packed));
之后通过控制表control table,即可获取通信的相关信息进⾏通信。
运行示例
root linux 中ivc配置如下:
//可根据需要在对应平台下的board.rs添加如下配置,这⾥以qemu-gicv3为例
//hvisor/platform/aarch64/qemu-gicv3/board.rs
pub const ROOT_ZONE_IRQS: [u32; 9] = [33, 64, 77, 79, 35, 36, 37, 38, 65];//添加中断号65
pub const ROOT_ZONE_IVC_CONFIG: [HvIvcConfig; 1] = [
HvIvcConfig {
ivc_id: 0,
peer_id: 0,
control_table_ipa: 0xd0000000,
shared_mem_ipa: 0xd0001000,
rw_sec_size: 0,
out_sec_size: 0x1000,
interrupt_num: 65,
max_peers: 2,
},
];
在zone0的设备树中添加hvisor_ivc_device节点,设备树中的中断号要与ivc配置中的interrupt_num⼀致,这⾥为0x21是因为ARM架构要加上⼤⼩为32的偏移(0x21+32=65):
hvisor_ivc_device {
compatible = "hvisor";
interrupt-parent = <0x01>;
interrupts = <0x00 0x21 0x01>;
};
non-root linux中ivc配置如下:
//在zone1的虚拟机配置⽂件添加`ivc`配置,以`zone1-linux.json`为例
"interrupts": [66, 76, 78], //添加中断号66
"ivc_configs": [
{
"ivc_id": 0,
"peer_id": 1,
"control_table_ipa": "0xd0000000",
"shared_mem_ipa": "0xd0001000",
"rw_sec_size": "0",
"out_sec_size": "0x1000",
"interrupt_num": 66,
"max_peers": 2
}
],
在zone1的设备树中添加hvisor_ivc_device节点,设备树中的中断号要与ivc配置中的interrupt_num⼀致,这⾥为0x22是因为ARM架构要加上⼤⼩为32的偏移(0x22+32=66):
hvisor_ivc_device {
compatible = "hvisor";
interrupt-parent = <0x01>;
interrupts = <0x00 0x22 0x01>;
};
在运⾏hvisor-tool/tools/ivc_demo测试ivc功能时,需要分别在root linux和non-root linux中执⾏insmod ivc.ko创建/dev/hivc0设备
hvisor Kconfig 配置体系
1. 为什么需要 Kconfig
hvisor 支持多种 CPU 架构(aarch64、riscv64、loongarch64、x86_64)和多种开发板。不同板级需要不同的驱动与功能组合,例如:
- GICv2 / GICv3、PLIC、AIA 等中断控制器
- PL011 / UART16550 等串口
- PCI/PCIe 及 ECAM、DesignWare 等访问方式
- IOMMU、Virtio-PCI 等可选子系统
若把这些选项全部写死在 Cargo.toml 的 [features] 里,每增加一块板子就要维护一份 feature 列表,容易出错。Kconfig 的做法与 Linux 内核类似:
- 在统一的
Kconfig文件里声明所有可选项及其依赖关系; - 每块板子有一份
defconfig,记录默认开启哪些选项; - 构建时生成
.config,再转成 Rust 编译器能识别的rustc-cfg。
2. 快速编译
BID(Board ID)格式为 <arch>/<board>,例如 aarch64/qemu-gicv3、riscv64/qemu-plic。
Makefile 通过 ARCH 和 BOARD(或 BID=aarch64/qemu-gicv3)选择平台目录:
make defconfig ARCH=aarch64 BOARD=qemu-gicv3
make all ARCH=aarch64 BOARD=qemu-gicv3
3. 核心文件一览
| 路径 | 作用 |
|---|---|
kconfig/Kconfig | 全局 Kconfig 菜单:架构、中断、UART、PCIe、IOMMU 等 |
kconfig/cfg_map.toml | CONFIG_* 符号 → Rust cfg 名称的映射表 |
platform/<arch>/<board>/kconfig/defconfig | 该板级的默认 CONFIG_* 列表 |
.config | 构建时生成的完整配置(不要手动编辑后长期提交) |
build.rs | 根据 .config 发出 cargo:rustc-cfg=...,并链接 board.rs |
tools/kconfig/kconfig_cli.py | defconfig / menuconfig 入口 |
tools/kconfig/host_config.sh | 根据 .config 生成 .cargo/config.toml 等 |
4. 常用 Make command
| 命令 | 说明 |
|---|---|
make defconfig ARCH=... BOARD=... | 从板级 defconfig 生成 .config |
make menuconfig ARCH=... BOARD=... | 交互式修改配置(需 Python venv + curses) |
make savedefconfig ARCH=... BOARD=... | 将当前 .config 中的 CONFIG_* 写回 defconfig |
make all ARCH=... BOARD=... | defconfig → 生成 Cargo 配置 → 编译 → 内存重叠检查 |
make elf ARCH=... BOARD=... | 仅编译,不打包 bin |
make clean | 清理构建产物 |
首次使用需创建 Kconfig 虚拟环境(make defconfig 会自动触发):
./tools/kconfig/bootstrap_venv.sh
5. 如何新增一个 feature(完整流程)
以新增可选功能 MY_FEATURE 为例(Rust cfg 名为 my_feature)。
步骤 1:在 kconfig/Kconfig 中声明
在合适菜单下增加 bool 选项,并写好 depends on:
config MY_FEATURE
bool "My optional subsystem"
depends on PCI # 按实际需求填写
default n
若与其它选项有联动,可使用 select / depends on。
步骤 2:在 kconfig/cfg_map.toml 中注册映射
CONFIG_MY_FEATURE = "my_feature"
键名必须与 .config 中一致(带 CONFIG_ 前缀)。
步骤 3:在 Rust 源码中使用
#![allow(unused)] fn main() { #[cfg(my_feature)] mod my_feature_impl; #[cfg(my_feature)] pub fn init_my_feature() { ... } }
复杂条件可组合平台 cfg 与架构:
#![allow(unused)] fn main() { #[cfg(all(my_feature, target_arch = "riscv64"))] fn riscv_specific() { ... } }
不要再使用已废弃的 #[cfg(feature = "my_feature")] 或 Cargo.toml [features]。
步骤 4:在需要该功能的板级 defconfig 中启用
编辑 platform/<arch>/<board>/kconfig/defconfig,增加:
CONFIG_MY_FEATURE=y
示例(platform/aarch64/qemu-gicv3/kconfig/defconfig):
CONFIG_ARCH_AARCH64=y
CONFIG_PCI=y
CONFIG_VIRTIO_PCI=y
...
hvisor总体架构
-
CPU虚拟化
- 架构兼容性:支持aarch64, riscv64, 和loongarch等架构,每种架构有专门的CPU虚拟化组件。
- CPU分配:采用静态分配方式,预先决定每个虚拟机的CPU资源。
-
内存虚拟化
- 二阶段页表:利用二阶段页表技术,优化内存虚拟化过程。
-
中断虚拟化
- 中断控制器虚拟化:支持ARM GIC、RISC-V PLIC等不同架构的中断控制器虚拟化。
- 中断处理:管理中断信号的传递和处理流程。
-
I/O虚拟化
- IOMMU集成:支持IOMMU,增强DMA虚拟化的效率和安全性。
- VirtIO标准:遵循VirtIO规范,提供高性能的虚拟设备。
- PCI虚拟化:实现PCI虚拟化,确保虚拟机可以访问物理或虚拟I/O设备。
hvisor的初始化过程
摘要:介绍在qemu上运行hvisor和hvisor初始化过程涉及的相关知识。从qemu启动后开始跟踪整个流程,阅读完本文将对hvisor的初始化过程有一个大概的认识。
qemu启动流程
qemu模拟的计算机的启动过程:将必要文件加载到内存之后,PC寄存器被初始化为0x1000,从这里开始执行几条指令后就跳转到0x80000000开始执行bootloader(hvsior arm部分使用的是Uboot),执行几条指令后再跳转到uboot可以识别的内核的起始地址执行。
生成hvisor的可执行文件
rust-objcopy --binary-architecture=aarch64 target/aarch64-unknown-none/debug/hvisor --strip-all -O binary target/aarch64-unknown-none/debug/hvisor.bin.tmp
将hvisor的可执行文件转为逻辑二进制,保存为 hvisor.bin.tmp。
生成uboot可以识别的镜像文件
uboot是一种bootloader,它的主要任务是跳转到hvisor镜像的第一条指令开始执行,所以要保证生成的hvisor镜像是uboot可以识别的,这里需要使用 mkimage工具。
mkimage -n hvisor_img -A arm64 -O linux -C none -T kernel -a 0x40400000 -e 0x40400000 -d target/aarch64-unknown-none/debug/hvisor.bin.tmp target/aarch64-unknown-none/debug/hvisor.bin
-n hvisor_img:指定内核镜像的名称。-A arm64:指定架构为 ARM64。-O linux:指定操作系统为 Linux。-C none:不使用压缩算法。-T kernel:指定类型为内核。-a 0x40400000:指定加载地址为0x40400000。-e 0x40400000:指定入口地址为0x40400000。-d target/aarch64-unknown-none/debug/hvisor.bin.tmp:指定输入文件为之前生成的临时二进制文件。- 最后一个参数是生成的输出文件名,即最终的内核镜像文件
hvisor.bin。
初始化过程
aarch64.ld链接脚本
要知道hvisor是如何执行的,我们首先查看链接脚本 platform/aarch64/qemu-gicv3/linker.ld。链接脚本(Linker Script)是连接编译器与硬件的关键桥梁,由 GNU ld 工具使用,用于控制目标文件的段(section)如何被映射到输出可执行文件的内存布局中,决定了程序在内存中如何布局。它定义了程序入口点、各段的加载地址与运行地址、内存区域的排列顺序
特殊符号的定义(如 hvisor中的 __core_end )。
ENTRY(arch_entry)
BASE_ADDRESS = 0x40400000;
第一行设置了程序入口函数为 arch_entry ,这个入口可以在 arch/aarch64/entry.rs 中找到,稍后介绍。第二行定义了程序的基地址为0x40400000。
.text : {
*(.text.entry)
*(.text .text.*)
}
我们将 .text 段作为最开头的段,且把包含了入口第一条指令的 .text.entry 放在 .text 段的开头,这样就保证了hvisor确实会从和qemu约定的0x40400000处开始执行。
这里我们还需要记住一个东西叫 __core_end , 它是链接脚本的结束位置的地址,等一下启动过程中可以知道它的作用。
arch_entry
有了上面这些前提,我们可以走进hvisor的第一条指令了,也就是 arch_entry() 。
#![allow(unused)] fn main() { // src/arch/aarch64/entry.rs #[naked] #[no_mangle] #[link_section = ".text.entry"] pub unsafe extern "C" fn arch_entry() -> ! { unsafe { core::arch::asm!( " // x0 = dtbaddr mov x18, x0 /* Insert nop instruction to ensure byte at offset 10 in hvisor binary is non-zero. * Rockchip U-Boot (arch_preboot_os@arch/arm/mach-rockchip/board.c:670) performs * forced relocation if this byte is zero, causing boot failure. This padding * prevents unintended relocation by maintaining non-zero value at this critical * offset in the binary layout. */ nop nop bl {boot_cpuid_get} // x17 = cpuid adrp x2, __core_end // x2 = &__core_end mov x3, {per_cpu_size} // x3 = per_cpu_size madd x4, x17, x3, x3 // x4 = cpuid * per_cpu_size add x5, x2, x4 mov sp, x5 // sp = &__core_end + (cpuid + 1) * per_cpu_size // disable cache and MMU mrs x1, sctlr_el2 bic x1, x1, #0xf msr sctlr_el2, x1 // cache_invalidate(0): clear dl1$ mov x0, #0 bl {cache_invalidate} ic iallu cmp x17, 0 b.ne 1f // if (cpu_id == 0) cache_invalidate(2): clear l2$ mov x0, #2 bl {cache_invalidate} // ic iallu bl {clear_bss} bl {boot_pt_init} 1: bl {mmu_enable} mov x1, x18 mov x0, x17 mov x18, #0 mov x17, #0 bl {rust_main} // x0 = cpuid, x1 = dtbaddr ", options(noreturn), boot_cpuid_get = sym boot_cpuid_get, cache_invalidate = sym cache_invalidate, per_cpu_size = const PER_CPU_SIZE, rust_main = sym crate::rust_main, clear_bss = sym crate::clear_bss, boot_pt_init = sym super::mmu::boot_pt_init, mmu_enable = sym super::mmu::mmu_enable, ); } } }
arch_entry函数有三条属性(Attributes),
#[naked]告诉编译器生成一个“裸函数”,编译器不会自动插入函数开始时的“序言”(prologue,如保存寄存器、调整栈帧)。#[no_mangle]表示禁用符号名称修饰,使得链接器(ld)能通过这个名称找到它。#[link_section = ".text.entry"]指定该函数应被放入名为 .text.entry 的代码段(section),正好与之前linker.ld中对应。
再看内嵌汇编部分。第一句指令 mov x18, x0 ,将 x0 寄存器的值传入 x18 寄存器,这里x0中存的是设备树的地址。qemu模拟一台arm架构的计算机,这个计算机中同样有着各种各样的设备,比如鼠标显示屏这种输入输出设备,以及各种存储设备,当我们想要从键盘获取输入、往显示屏输出,都要从某个地方获取输入,或者把输出的数据放到某个地方,在计算机中我们用特定地址来访问。设备树中就保存了这些设备的访问地址,hypervisor作为所有软件的总管,自然要知道设备树的信息,那么Uboot在进入内核之前就会把这些信息放在 x0中,这是一种约定。
第二、三条指令为nop,因为某些 Rockchip 平台的 U-Boot 在加载镜像前会检查二进制文件第10个字节,如果该字节为 0,U-Boot 会认为这是一个“未重定位”的镜像,强行进行重定位(relocation),导致 Hypervisor 被错误地移动到错误地址,启动失败。通过插入 nop 指令(机器码非零),确保第10个字节不是 0,从而绕过 U-Boot 的误判。
bl {boot_cpuid_get} 指令调用 boot_cpuid_get 函数获取当前 CPU 核心的 ID(cpuid),后续用于初始化 per-CPU 数据、判断是否为主核(cpuid == 0)。
adrp x2, __core_end // x2 = &__core_end
mov x3, {per_cpu_size} // x3 = per_cpu_size
madd x4, x17, x3, x3 // x4 = (cpuid + 1) * per_cpu_size
add x5, x2, x4
mov sp, x5 // sp = __core_end + (cpuid + 1) * per_cpu_size
这些指令负责在多核处理器上为每个 CPU 核心(CPU core)设置独立的栈空间,每个 CPU 核心都需要自己的 运行时栈(stack),用于保存函数调用的返回地址、局部变量、寄存器备份等。
如果多个核心共享同一个栈,会造成数据冲突和崩溃。__core_end来自链接脚本linker.ld,作为hvisor整个程序空间的结束地址。adrp x2, __core_end将符号 __core_end 所在的 4KB 页面基地址 加载到 x2 寄存器中,mov x3, {per_cpu_size} 将常量 PER_CPU_SIZE 加载到 x3 寄存器中。madd x4, x17, x3, x3 是一个乘加指令,将 (cpuid + 1) * per_cpu_size 存入 x4 寄存器, +1 可以避免 CPU 0 的栈从 __core_end 正好开始,防止与前面的数据段(.bss)紧贴,留出安全间隙。add x5, x2, x4 将“基地址”和“偏移量”相加,得到最终的栈顶地址,将计算出的栈顶地址写入栈指针寄存器sp。
mrs x1, sctlr_el2
bic x1, x1, #0xf
msr sctlr_el2, x1
这些指令负责关闭缓存与 MMU ,确保在重新设置页表和缓存策略前,当前的 MMU、数据缓存(D-Cache)、指令缓存(I-Cache)全部关闭,避免旧状态干扰新配置。mrs是一个访问系统级别寄存器的指令,也就是把系统寄存器 mpidr_el1 的内容送到 x1 中。mrs x1, sctlr_el2读取 EL2 系统控制寄存器 SCTLR_EL2 的值到通用寄存器 x1。bic x1, x1, #0xf 相当于x1 = x1 & ~0xf,即清除 x1 的低 4 位,也就相当于下面这段代码:
sctlr_el2.M = 0; // 关闭 MMU
sctlr_el2.A = 0; // 关闭对齐检查(避免未对齐访问异常)
sctlr_el2.C = 0; // 关闭数据缓存
sctlr_el2.I = 0; // 关闭指令缓存
msr sctlr_el2, x1将修改后的值写回 SCTLR_EL2,立即生效。
mov x0, #0
bl {cache_invalidate}
ic iallu
这段代码负责清除当前 CPU 核心的 L1 数据缓存(L1 D-Cache) 和 L1 指令缓存(L1 I-Cache)。首先mov x0, #0设置参数 x0 = 0,表示目标是 L1 缓存,再通过 bl {cache_invalidate} 调用汇编编写的 cache_invalidate(cache_level: usize) 函数。ic iallu指令使当前核心的整个 L1 指令缓存无效。之前的SCTLR_EL2.I=0 只是“禁用”了 I-Cache,但缓存中可能仍有旧指令,必须显式 invalidate 才能清除。
cmp x17, 0
b.ne 1f
// if (cpu_id == 0) cache_invalidate(2): clear l2$
mov x0, #2
bl {cache_invalidate}
这段代码用于主核清理 L2 缓存,也就是尽管有多个 CPU 但是总共只会执行一次,L2 缓存是多个 CPU 核心共享的,如果每个核心都清理一次 L2,会造成重复和潜在竞争。
bl {clear_bss}
bl {boot_pt_init}
1:
bl {mmu_enable}
这段代码首先调用 clear_bss 函数,将 .bss 段清零,.bss 段存放未初始化的全局变量,再调用boot_pt_init函数初始化启动页表(Boot Page Table),为即将开启的 MMU 准备虚拟内存映射。boot_pt_init函数会读取平台定义的物理内存区域列表 BOARD_PHYSMEM_LIST,检查其合法性(对齐、排序),根据这个列表创建多级页表(L0 和 L1,因为只是“启动页表”,不需要精细控制,所以用大块映射即可),实现从虚拟地址到物理地址的映射,目前的映射是恒等映射,也就是虚拟地址完全等于物理地址。
接着调用mmu_enable函数,通过MAIR配置内存属性、设置页表基址(TTBR0)、设置页表控制(TCR)、启用 MMU、数据缓存(D-Cache)、指令缓存(I-Cache) ,让 CPU 开始使用虚拟地址,地址翻译开始生效,此刻起,所有地址都变为虚拟地址。
mov x1, x18
mov x0, x17
mov x18, #0
mov x17, #0
bl {rust_main} // x0 = cpuid, x1 = dtbaddr
最后一步跳转到 Rust 主函数fn rust_main(cpuid: usize, host_dtb: usize)开始执行,这也说明了这段汇编代码不会返回,与 option(noreturn)相对应。
进入rust_main()
fn rust_main(cpuid:usize, host_dtb:usize)
进入 rust_main需要两个参数,这两个参数是通过 x0 和 x1 传递的,还记得前面的entry中,我们的 x0 存放的是cpu_id,x1 存放的是设备树的相关信息。
install_trap_vector()
当处理器遇到异常或者中断的时候,就要跳转去相应的位置进行处理,这里就是在设置这些相应的跳转地址(可以视为在设置一张表),用于处理在Hypervisor级别的异常。每个特权级都有自己对应的一张异常向量表,除了EL0,应用程序的特权级,它必须跳转到其他特权级处理异常。VBAR_ELn 寄存器用于存储ELn这个特权级下的异常向量表的基地址。
extern "C" {
fn _hyp_trap_vector();
}
pub fn install_trap_vector() {
// Set the trap vector.
VBAR_EL2.set(_hyp_trap_vector as _)
}
VBAR_EL2.set() 将 _hyp_trap_vector() 的地址设置为EL2特权级的异常向量表的基地址。
_hyp_trap_vector() 这段汇编代码就是在构建异常向量表。汇编代码的具体定义位于src/arch/aarch64/trap.S。
异常向量表格式的简单介绍
根据发生异常的等级和处理异常的等级是否相同分为两类,如果等级不变,则按照是否使用当前等级的SP分为两组,如果异常等级改变,则按照执行模式是64位/32位分为两组,至此异常向量表被划分为4组。在每一组中,每个表项代表一种异常处理情况的入口。
主CPU
static MASTER_CPU: AtomicI32 = AtomicI32::new(-1);
let mut is_primary = false;
if MASTER_CPU.load(Ordering::Acquire) == -1 {
MASTER_CPU.store(cpuid as i32, Ordering::Release);
is_primary = true;
memory::heap::init();
memory::heap::test();
}
static MASTER_CPU: AtomicI32 中,AtomicI32 表示这是一种原子类型,表示对他的操作要么成功要么失败,不会出现中间状态,可以保证多线程环境下的安全访问,总之它就是一个很安全的 i32 类型。
MASSTER_CPU.load() 是进行读操作的一个方法,参数 Ordering::Acquire 表示,如果在我进行读之前有一些写操作,那么需要等这些写操作按顺序进行完了,我再读。总之,这个参数保证了数据被正确更改后再进行读取。
如果读出来是-1,和定义时候的一样,代表主CPU还没有被设置,就把 cpu_id 设为主CPU。同样的,Ordering::Release 的作用肯定也是指修改之前要保证所有其他的修改都完成了。
也就是说,这段代码实现的功能是,第一个进入此函数的 CPU(即 cpuid == 0 的主核)会发现 MASTER_CPU == -1,于是会设置自己为 MASTER_CPU,标记 is_primary = true,初始化全局堆内存(heap)。堆的作用是支持动态内存分配如Box, Vec, Arc 等,用于创建虚拟机、页表、设备模型等对象。
CPU的通用数据结构:PerCpu
hvisor支持不同的架构,合理的系统设计应该让不同的架构使用统一的接口,便于描述各部分的工作。PerCpu 就是这样一个通用的CPU描述,它为系统中的每一个 CPU 核心维护一份独立的私有数据。在多核系统中,每个 CPU 都有自己的栈、状态、当前运行的虚拟机等,不能共享这些数据,否则会引发竞态,所以需要一个机制,也就是给每个 CPU 分配一块专属内存区域。
#![allow(unused)] fn main() { #[repr(C)] pub struct PerCpu { pub id: usize, pub cpu_on_entry: usize, pub dtb_ipa: usize, pub arch_cpu: ArchCpu, pub zone: Option<Arc<RwLock<Zone>>>, pub ctrl_lock: Mutex<()>, pub boot_cpu: bool, // percpu stack } }
对于 PerCpu 的各个字段:
id: CPU的序号cpu_on_entry:CPU进入EL1也就是guest的时候第一条指令的地址,只有当这个CPU是boot CPU时,才会被置为有效值,初始化的时候我们设置为一个访问不到的地址。dtb_ipa:Guest VM 使用的设备树在客户机视角下的物理地址(IPA,中间物理地址)arch_cpu:与架构相关的CPU描述,行为是由PerCpu发起,具体的执行者是arch_cpu。cpu_idpsci_on: cpu是否启动
zone:zone其实就代表一个guestOS,对于同一个guestOS可能有多个cpu在为他服务ctrl_lock:为并发安全性而设置。boot_cpu:对于一个guestOS,区分为他服务的CPU的主核/次核,boot_cpu即表示当前CPU是否是某个guest的主核。
主核唤醒其他核
#![allow(unused)] fn main() { if is_primary { wakeup_secondary_cpus(cpu.id, host_dtb); } fn wakeup_secondary_cpus(this_id: usize, host_dtb: usize) { for cpu_id in 0..MAX_CPU_NUM { if cpu_id == this_id { continue; } cpu_start(cpu_id, arch_entry as _, host_dtb); } } pub fn cpu_start(cpuid: usize, start_addr: usize, opaque: usize) { let new_cpuid = { if cpuid >= MAX_CPU_NUM { panic!("Invalid cpuid: {}", cpuid); } BOARD_MPIDR_MAPPINGS[cpuid] }; psci::cpu_on(new_cpuid, start_addr as _, opaque as _).unwrap_or_else(|err| { if let psci::error::Error::AlreadyOn = err { } else { panic!("can't wake up cpu {}", cpuid); } }); } }
如果当前CPU是主CPU,就由当前CPU来唤醒其他的次核,次核执行 cpu_start ,在 cpu_start 中,cpu_on 实际上调用了 call64中的SMC指令,陷入EL3来执行唤醒CPU的动作。
那么从 cpu_on 的声明中我们大概可以猜测它的功能,唤醒一个CPU,这个CPU将要从 arch_entry 这个地方开始执行。这是因为多核处理器之间会进行通信协作,那么就必须保证CPU的一致性,所以以相同的入口开始执行,为保持同步,应该保证每个CPU都运行到某个状态,那么可以由接下来的几句代码来验证。
ENTERED_CPUS.fetch_add(1, Ordering::SeqCst);
wait_for(|| PerCpu::entered_cpus() < MAX_CPU_NUM as _);
assert_eq!(PerCpu::entered_cpus(), MAX_CPU_NUM as _);
其中 ENTERED_CPUS.fetch_add(1, Ordering::SeqCst) 代表按照顺序一致性增加 ENTERED_CPUS 的值,那么每个CPU执行一次后,这个 assert_eq 宏应该可以顺利通过。
主核还需要干的事primary_init_early()
初始化日志
- 全局的日志记录器的创建
- 日志级别过滤器的设置,设置日志级别过滤器的主要作用是决定哪些日志消息应该被记录和输出。
初始化堆空间和页表
- 在.bss段申请了一段空间作为堆空间,设置好分配器
- 设置页帧分配器
解析设备树的信息
根据 rust_main 参数中的设备树地址堆设备树的信息进行解析。
创建GIC实例
实例化一个全局的静态变量GIC,是通用中断控制器的一个实例。
初始化hvisor的页表
这个页表只是针对hypervisor自身VA转为PA的实现。(以内核和应用的关系来理解)
为每个VM创建zone
zone其实就代表一个guestVM,是虚拟机(Virtual Machine)的运行时管理结构体,里面包含了某个guestVM可能会用到的各种信息。
#![allow(unused)] fn main() { pub struct Zone { pub name: [u8; CONFIG_NAME_MAXLEN], // 虚拟机名称 pub id: usize, // 虚拟机 ID pub mmio: Vec<MMIOConfig>, // MMIO 区域及其处理函数 pub cpu_num: usize, // 分配给该 Zone 的 CPU 数量 pub cpu_set: CpuSet, // 分配给该 Zone 的 CPU 集合 pub irq_bitmap: [u32; 1024 / 32], // 中断位图(支持最多 1024 个中断) pub gpm: MemorySet<Stage2PageTable>, // 客户机物理内存映射(S2PT) pub pciroot: PciRoot, // PCI 总线根设备 pub is_err: bool, // 是否发生错误 } }
#![allow(unused)] fn main() { let zone = zone_create(root_zone_config()).unwrap(); add_zone(zone); }
zone_create 会接收一个HvZoneConfig类型的参数,这是一个只读的、编译时/启动时确定的虚拟机配置结构体,用于在创建 Zone(虚拟机)时传递所有必要的初始化参数,其核心作用是将静态的HvZoneConfig配置转换为动态的Zone运行时结构,完成虚拟机资源的分配和初始化。HvZoneConfig描述了虚拟机所需的CPU、内存、中断、PCI设备等资源,而Zone则是这些资源在运行时的具体实现。
#![allow(unused)] fn main() { pub struct HvZoneConfig { pub zone_id: u32, // 虚拟机唯一 ID(0 通常是 root VM) cpus: u64, // CPU 位图(bitmask),表示分配哪些 CPU 核心(如 0b101 = CPU0 和 CPU2) num_memory_regions: u32, // 内存区域数量 memory_regions: [HvConfigMemoryRegion; CONFIG_MAX_MEMORY_REGIONS], // 客户机物理内存布局(GPA 映射) num_interrupts: u32, // 分配的中断数量 interrupts: [u32; CONFIG_MAX_INTERRUPTS], // 属于该 VM 的中断 ID 列表(如 GIC IRQ) num_ivc_configs: u32, // IVC(Inter-VM Communication)通道数量 ivc_configs: [HvIvcConfig; CONFIG_MAX_IVC_CONFIGS], // IVC 通道配置(跨虚拟机通信) pub entry_point: u64, // 客户机启动入口地址(GPA) pub kernel_load_paddr: u64, // 内核镜像加载的客户机物理地址 pub kernel_size: u64, // 内核大小(若为 INVALID_ADDRESS 表示不指定) pub dtb_load_paddr: u64, // 设备树(DTB)加载的客户机物理地址 pub dtb_size: u64, // DTB 大小(若为 INVALID_ADDRESS 表示不指定) pub name: [u8; CONFIG_NAME_MAXLEN], // 虚拟机名称 pub arch_config: HvArchZoneConfig, // 架构特定配置 pub pci_config: HvPciConfig, // PCI 总线配置 pub num_pci_devs: u64, // 分配的虚拟 PCI 设备数量 pub alloc_pci_devs: [u64; CONFIG_MAX_PCI_DEV], // 分配的 PCI 设备 BDF(Bus:Device:Function)列表 } pub struct HvConfigMemoryRegion { pub mem_type: u32, // RAM / IO / VIRTIO pub physical_start: u64, // GPA 起始地址 pub virtual_start: u64, // IPA(客户机视角的虚拟地址) pub size: u64, } pub struct HvIvcConfig { pub ivc_id: u32, // 通信通道 ID pub peer_id: u32, // 对端 Zone ID pub control_table_ipa: u64, // 控制表的客户机虚拟地址 pub shared_mem_ipa: u64, // 共享内存的客户机虚拟地址 pub rw_sec_size: u32, // 读写段大小 pub out_sec_size: u32, // 输出段大小 pub interrupt_num: u32, // 通知中断号 pub max_peers: u32, // 最大对端数 } pub struct HvPciConfig { pub ecam_base: u64, // ECAM 基地址(GPA) pub ecam_size: u64, // ECAM 大小 pub num_buses: u32, // PCI 总线数量 } pub struct Zone { pub name: [u8; CONFIG_NAME_MAXLEN], pub id: usize, pub mmio: Vec<MMIOConfig>, // 管理 Zone 的内存映射 I/O pub cpu_num: usize, // 记录分配给该 Zone 的 CPU 核心数量 pub cpu_set: CpuSet, // 位图,记录哪些 CPU 核心被分配给了该 Zone pub irq_bitmap: [u32; 1024 / 32], // 中断位图,用于记录该 Zone 拥有的中断号(IRQ) pub gpm: MemorySet<Stage2PageTable>, // 用于虚拟化内存管理的二级页表 pub pciroot: PciRoot, // 管理该 Zone 的 PCI(Peripheral Component Interconnect)总线和设备。 pub is_err: bool, // 表示该 Zone 是否处于错误状态 } }
zone_create函数在hisor Hypervisor中具有多种应用场景:
- 创建Root Zone:当zone_id为0时,创建特权虚拟机(通常为宿主机操作系统),拥有完整的硬件访问权限。
- 创建普通虚拟机:当zone_id大于0时,创建非特权虚拟机,其资源访问受到Hypervisor的严格限制。
下面详细讲解一下该函数的运行流程:
#![allow(unused)] fn main() { let mut zone = Zone::new(zone_id, &config.name); zone.pt_init(config.memory_regions()).unwrap(); zone.mmio_init(&config.arch_config); zone.arch_zone_configuration(config)?; zone.pci_init( &config.pci_config, config.num_pci_devs as _, &config.alloc_pci_devs, ); }
首先基于配置创建新的Zone结构体,调用pt_init方法初始化Stage2页表,将HvConfigMemoryRegion数组转换为虚拟机的内存布局,建立GPA到 HPA 的映射关系。然后调用mmio_init初始化架构相关的 MMIO 设备。再调用arch_zone_configuration进行架构的特定配置。再调用pci_init初始化虚拟 PCI 总线。
#![allow(unused)] fn main() { let mut cpu_num = 0; for cpu_id in config.cpus().iter() { if let Some(zone) = get_cpu_data(*cpu_id as _).zone.clone() { return hv_result_err!( EBUSY, format!( "Failed to create zone: cpu {} already belongs to zone {}", cpu_id, zone.read().id ) ); } zone.cpu_set.set_bit(*cpu_id as _); cpu_num += 1; } zone.cpu_num = cpu_num; }
这段代码遍历配置中指定的 CPU 列表(cpus())、检查每个 CPU 是否已被其他 Zone 占用,若已绑定,则返回 EBUSY 错误,成功则将其加入当前 Zone 的 cpu_set,最终设置 cpu_num 为分配的 CPU 数量
#![allow(unused)] fn main() { zone.virqc_init(config); zone.irq_bitmap_init(config.interrupts()); let mut dtb_ipa = INVALID_ADDRESS as u64; for region in config.memory_regions() { // region contains config.dtb_load_paddr? if region.physical_start <= config.dtb_load_paddr && region.physical_start + region.size > config.dtb_load_paddr { dtb_ipa = region.virtual_start + config.dtb_load_paddr - region.physical_start; } } }
virqc_init函数初始化虚拟中断控制器(Virtual IRQ Controller),irq_bitmap_init根据配置中的中断列表(如串口、网卡使用的 IRQ 号),更新 irq_bitmap,设置哪些中断号是这个 Zone “拥有”的。
接着计算 DTB 的 IPA 地址(设备树位置),客户机操作系统启动时需要加载设备树(Device Tree Blob, DTB),dtb_load_paddr 是 DTB 在客户机视角下的物理地址(GPA),但由于 GPA 和 IPA 可能有偏移(因为映射到了不同的 HPA),我们需要知道“当客户机访问这个 GPA 时,它实际上对应哪个 IPA?”,所以这里通过遍历内存区域,找到包含 dtb_load_paddr 的 region, 然后根据 virtual_start - physical_start 的偏移量,算出对应的 IPA。最终结果存入 dtb_ipa,后面会传递给每个 CPU 上下文。
#![allow(unused)] fn main() { info!("zone cpu_set: {:#b}", zone.cpu_set.bitmap); let cpu_set = zone.cpu_set; let new_zone_pointer = Arc::new(RwLock::new(zone)); { cpu_set.iter().for_each(|cpuid| { let cpu_data = get_cpu_data(cpuid); cpu_data.zone = Some(new_zone_pointer.clone()); //chose boot cpu if cpuid == cpu_set.first_cpu().unwrap() { cpu_data.boot_cpu = true; } cpu_data.cpu_on_entry = config.entry_point as _; cpu_data.dtb_ipa = dtb_ipa as _; #[cfg(target_arch = "aarch64")] { cpu_data.arch_cpu.is_aarch32 = config.arch_config.is_aarch32 != 0; } }); } Ok(new_zone_pointer) }
这段代码是最关键的一步,让每个物理 CPU 知道自己要运行哪个 Zone。cpu_data.zone 指向当前 CPU 要运行的 Zone,boot_cpu标记是否为主引导 CPU,cpu_on_entry表示当 CPU 被唤醒时跳转的入口地址,dtb_ipa表示设备树在 IPA 空间的位置,供客户机读取硬件信息,is_aarch32为架构标志,决定运行 32 位还是 64 位模式。
最后代码返回一个引用计数的可读写锁包裹的 Zone 实例,后续可以通过这个句柄进行vcpu_run、查询状态、动态添加设备、销毁 Zone。
上面主核CPU要做的事情告一段落,以 INIT_EARLY_OK.store(1, Ordering::Release) 作为标记,而其他CPU在主核完成之前,只能进行等待 wait_for_counter(&INIT_EARLY_OK, 1)。
地址空间初始化
上个部分提到的IPA和PA其实是地址空间的内容,具体的内容将在内存管理的文档中给出,这里做一个简要介绍。
如果不考虑Hypervisor,guestVM作为一个内核,会进行内存管理的工作,也就是应用程序的虚拟地址VA到内核的PA的过程,那么这里的PA,就是真正的内存物理地址。
在考虑Hypervisor的情况下,Hypervisor作为一个内核的角色也同样会做内存管理的工作,只是这时候的应用程序就变成了guestVM,而guestVM是不会意识到Hypervisor的存在的(否则需要更改guestVM的设计,这不符合我们提高性能的初衷)。我们将guestVM中的PA叫做IPA或者GPA,因为它不是最终的物理地址,而是Hypervisor让guestVM看到的中间物理地址,所以整个系统中存在着两套内存管理机制,guestVM管理的VA到IPA的转换,以及Hypervisor管理的从IPA到PA的转换。
run_vm()
在 zone_create 中,我们完成了虚拟机的资源分配和配置,但还没有真正运行它。现在终于到了即将启动guestVM的时刻了。
#![allow(unused)] fn main() { // percpu.rs // impl PerCpu > run_vm pub fn run_vm(&mut self) { if !self.boot_cpu { info!("CPU{}: Idling the CPU before starting VM...", self.id); self.arch_cpu.idle(); } info!("CPU{}: Running the VM...", self.id); self.arch_cpu.run(); } }
真正的启动发生在 run_vm 函数中,而它最终会调用到 ArchCpu 的两个核心方法:
run():主函数,用于启动或恢复虚拟机执行
idle():备用函数,用于非启动 CPU 的“待机”状态
将非boot_cpu设置为空闲状态
对于非boot_cpu,将其设置为空闲状态并等待唤醒。在 idle 函数中实现。
核心CPU的启动
#![allow(unused)] fn main() { pub fn run(&mut self) -> ! { assert!(this_cpu_id() == self.cpuid); this_cpu_data().activate_gpm(); self.reset(this_cpu_data().cpu_on_entry, this_cpu_data().dtb_ipa); if self.is_aarch32 { info!("cpu {} is aarch32", self.cpuid); HCR_EL2.write(...); // 切换为 AArch32 模式 SPSR_EL2.set(0x1D3); // 返回 Supervisor 模式 } self.power_on = true; info!("cpu {} started at {:#x?}", self.cpuid, this_cpu_data().cpu_on_entry); unsafe { vmreturn(self.guest_reg() as *mut _ as usize); } } }
首先确保当前运行的物理 CPU 与 ArchCpu 实例匹配,防止跨 CPU 错误调用。接着调用activate_gpm激活当前 CPU 的 Stage 2 页表,实际上是调用 gpm.activate(),它会将 VTTBR_EL2 寄存器设置为当前 Zone 的 Stage 2 页表基地址,从而启用虚拟机的内存视图(即 GPA → HPA 映射)。
self.reset(entry, dtb)函数会重置 vCPU 的寄存器状态,为进入客户机做准备,具体来说,它会设置ELR_EL2(Exception Link Register at EL2)寄存器为客户机的入口点,当从 EL2 返回时(执行 eret),CPU 会跳转到 ELR_EL2 指向的地址,另外还会设置 SPSR_EL2(Saved Program Status Register) 寄存器,定义了返回后处理器的状态为禁止调试、异步中止、IRQ、FIQ,并且返回到 EL1(内核态),使用 SP_EL1 堆栈。接着初始化客户机的通用寄存器,x0 被设为设备树(DTB)的物理地址,这是 Linux 内核启动所需参数。然后回调用activate_vmm函数设置 Stage 2 页表控制寄存器。
vmreturn是最关键的一步,这是一个汇编函数:
#![allow(unused)] fn main() { #[naked] #[no_mangle] pub unsafe extern "C" fn vmreturn(_gu_regs: usize) -> ! { core::arch::asm!( " /* x0: guest registers */ mov sp, x0 ldp x1, x0, [sp], #16 /* x1 is the exit_reason */ ldp x1, x2, [sp], #16 ldp x3, x4, [sp], #16 ldp x5, x6, [sp], #16 ldp x7, x8, [sp], #16 ldp x9, x10, [sp], #16 ldp x11, x12, [sp], #16 ldp x13, x14, [sp], #16 ldp x15, x16, [sp], #16 ldp x17, x18, [sp], #16 ldp x19, x20, [sp], #16 ldp x21, x22, [sp], #16 ldp x23, x24, [sp], #16 ldp x25, x26, [sp], #16 ldp x27, x28, [sp], #16 ldp x29, x30, [sp], #16 /*now el2 sp point to per cpu stack top*/ eret //ret to el2_entry hvc #0 now,depend on ELR_EL2 ", options(noreturn), ) } }
可以看到vmreturn这部分的内容主要是对我们刚才保存的上下文进行恢复,并且返回到虚拟机执行。
将栈顶设置为 x0,在调用这个函数的时候通过 x0 传入一个参数 _gu_regs ,这个参数其实就是寄存器上下文的起始地址。这样我们就可以通过 sp 对各个寄存器进行恢复。
ldp 是arm架构下的一个加载指令,ldp x1,x0,[sp] 代表从 sp 这个地址处,加载两个64位的值到 x1 和 x0 中。并且会自动将 sp 的值+16,也就是两个寄存器的大小。这里没有按照 x0,x1 的原因是,我们将 exit 相关的信息,放在了寄存器上下文的开头,而它的下一个才是 x0 。
完成上下文的恢复以后,sp 的值就增加了32*8的大小,指向了percpu区域的末尾。
最后我们执行 eret 语句,此时cpu从当前特权级EL2的 ELR_EL2 中取出返回地址,并且通过 SPSR_EL2 知道了他要返回到EL1特权级。还记得我们在设计 percpu 的时候,对于boot-cpu,我们将我们在qemu启动参数中写好的内存被放置的地址,设置为cpu返回后执行的第一条指令的地址,所以返回EL1后,cpu就会从内核的第一条指令开始执行。
至此,读者应该对hvisor的大致启动过程以及设计模块有了大致理解。
PerCPU结构体
在hvisor的架构中,PerCpu结构体扮演着核心角色,用于实现每个CPU核心的本地状态管理以及支持CPU虚拟化。下面是对PerCpu结构体及相关函数的详细介绍:
PerCpu结构体定义
PerCpu结构体被设计为每个CPU核心存储其特定数据和状态的容器。它的布局如下:
#[repr(C)]
pub struct PerCpu {
pub id: usize,
pub cpu_on_entry: usize,
pub dtb_ipa: usize,
pub arch_cpu: ArchCpu,
pub zone: Option<Arc<RwLock<Zone>>>,
pub ctrl_lock: Mutex<()>,
pub boot_cpu: bool,
// percpu stack
}
各字段定义如下:
id: CPU核心的标识符。
cpu_on_entry: 一个用于追踪CPU进入状态的地址,初始化为INVALID_ADDRESS,表示无效地址。
dtb_ipa: 设备树二进制的物理地址,同样初始化为INVALID_ADDRESS。
arch_cpu: 一个指向ArchCpu类型的引用,ArchCpu包含特定于架构的CPU信息和功能。
zone: 一个可选的Arc<RwLock<Zone>>类型,表示当前CPU核心正在运行的虚拟机(zone)。
ctrl_lock: 一个互斥锁,用于控制访问和同步PerCpu的数据。
boot_cpu: 一个布尔值,指示是否为引导CPU。
PerCpu的构造和操作
PerCpu::new: 此函数创建并初始化PerCpu结构体。它首先计算结构体的虚拟地址,然后安全地写入初始化数据。对于RISC-V架构,还会更新CSR_SSCRATCH寄存器来存储ArchCpu的指针。
run_vm: 当调用此方法时,如果当前CPU不是引导CPU,则会先将其置于空闲状态,然后再运行虚拟机。
entered_cpus: 返回已进入虚拟机运行状态的CPU核心数。
activate_gpm: 激活所关联zone的GPM(Guest Page Management)。
获取PerCpu实例
get_cpu_data: 提供基于CPU ID获取PerCpu实例的方法。
this_cpu_data: 返回当前执行CPU的PerCpu实例。
AArch64下的CPU虚拟化
CPU启动机制
在AArch64架构下,hvisor利用psci::cpu_on()函数唤醒指定的CPU核心,将其从关闭状态带入运行状态。该函数接收CPU的ID、启动地址以及一个不透明参数作为输入。遇到错误时,如CPU已处于唤醒状态,函数会进行适当的错误处理避免重复唤醒。
CPU虚拟化初始化与运行
ArchCpu结构体封装了特定于架构的CPU信息和功能,其reset()方法负责将CPU设置为虚拟化模式的初始状态。这包括:
- 设置ELR_EL2寄存器至指定的入口点
- 配置SPSR_EL2寄存器
- 清空通用寄存器
- 重置虚拟机相关寄存器
activate_vmm(),激活虚拟内存管理器(VMM)
activate_vmm()方法用于配置VTCR_EL2和HCR_EL2寄存器,启用虚拟化环境。
ArchCpu的run()和idle()方法分别用于启动和闲置CPU。启动时,激活zone的GPM(Guest Page Management),重置到指定的入口点和设备树二进制(DTB)地址,然后通过vmreturn宏跳转到EL2入口点。在闲置模式下,CPU被重置到等待状态(WFI),并准备parking指令页面以供闲置期间使用。
EL1与EL2之间的切换
hvisor在AArch64架构中使用EL2作为hypervisor模式,而EL1用于guest OS。handle_vmexit宏处理从EL1到EL2的上下文切换(VMEXIT事件),保存用户模式寄存器上下文,调用外部函数处理退出原因,之后返回到hypervisor代码段继续执行。vmreturn函数用于从EL2模式回到EL1模式(VMENTRY事件),恢复用户模式寄存器上下文后,通过eret指令返回到guest OS的代码段。
MMU配置与启用
为了支持虚拟化,enable_mmu()函数在EL2模式下配置MMU映射,包括设置MAIR_EL2、TCR_EL2和SCTLR_EL2寄存器,允许指令和数据缓存能力,并确保虚拟范围覆盖整个48位地址空间。
通过这些机制,hvisor在AArch64架构上实现了高效的CPU虚拟化,允许多个独立的zones在静态分配的资源下运行,同时保持系统稳定性和性能。
RISCV下的CPU虚拟化
摘要:围绕ArchCpu结构,介绍RISCV架构下的CPU虚拟化工作。
涉及的两个数据结构
hvisor支持多种架构,每个架构的CPU虚拟化需要做的工作不同,但在一个系统中又应该提供统一的接口,故我们将CPU拆分成 PerCpu 和 ArchCpu 两个数据结构。
PerCpu
这是一个通用的CPU的描述,在 PerCpu 的文档中已给出介绍。
ArchCpu
ArchCpu 是针对具体架构(本文中介绍RISCV架构)的CPU结构。由这个结构承担CPU具体的行为。
在ARM架构下,也有对应的 ArchCpu ,与本节介绍的 ArchCpu 具体结构略有不同,但他们具有相同的接口(也就是都具有初始化等行为)。
包含的字段如下:
pub struct ArchCpu {
pub x: [usize; 32], //x0~x31
pub hstatus: usize,
pub sstatus: usize,
pub sepc: usize,
pub stack_top: usize,
pub cpuid: usize,
// pub first_cpu: usize,
pub power_on: bool,
pub init: bool,
pub sstc: bool,
}
各个字段的解释如下:
x:通用寄存器的值hstatus:存储Hypervisor状态寄存器的值sstatus:存储Supervisor状态寄存器的值,管理S模式的状态信息,如中断使能标志等sepc:异常处理结束的返回地址stack_top:对应的cpu栈的栈顶power_on:该cpu是否被开启init:该cpu是否已初始化sstc:是否配置了定时器中断
相关方法
这一部分讲解涉及的方法。
ArchCpu::init
这个方法主要是对cpu进行初始化工作,设置初次进入vm的时候的上下文,以及一些CSR的初始化。
pub fn init(&mut self, entry: usize, cpu_id: usize, dtb: usize) {
write_csr!(CSR_SSCRATCH, self as *const _ as usize); //arch cpu pointer
self.sepc = entry;
self.hstatus = 1 << 7 | 2 << 32; //HSTATUS_SPV | HSTATUS_VSXL_64
self.sstatus = 1 << 8 | 1 << 63 | 3 << 13 | 3 << 15; //SPP
self.stack_top = self.stack_top() as usize;
self.x[10] = cpu_id; //cpu id
self.x[11] = dtb; //dtb addr
set_csr!(CSR_HIDELEG, 1 << 2 | 1 << 6 | 1 << 10); //HIDELEG_VSSI | HIDELEG_VSTI | HIDELEG_VSEI
set_csr!(CSR_HEDELEG, 1 << 8 | 1 << 12 | 1 << 13 | 1 << 15); //HEDELEG_ECU | HEDELEG_IPF | HEDELEG_LPF | HEDELEG_SPF
set_csr!(CSR_HCOUNTEREN, 1 << 1); //HCOUNTEREN_TM
//In VU-mode, a counter is not readable unless the applicable bits are set in both hcounteren and scounteren.
set_csr!(CSR_SCOUNTEREN, 1 << 1);
write_csr!(CSR_HTIMEDELTA, 0);
set_csr!(CSR_HENVCFG, 1 << 63);
//write_csr!(CSR_VSSTATUS, 1 << 63 | 3 << 13 | 3 << 15); //SSTATUS_SD | SSTATUS_FS_DIRTY | SSTATUS_XS_DIRTY
// enable all interupts
set_csr!(CSR_SIE, 1 << 9 | 1 << 5 | 1 << 1); //SEIE STIE SSIE
// write_csr!(CSR_HIE, 1 << 12 | 1 << 10 | 1 << 6 | 1 << 2); //SGEIE VSEIE VSTIE VSSIE
write_csr!(CSR_HIE, 0);
write_csr!(CSR_VSTVEC, 0);
write_csr!(CSR_VSSCRATCH, 0);
write_csr!(CSR_VSEPC, 0);
write_csr!(CSR_VSCAUSE, 0);
write_csr!(CSR_VSTVAL, 0);
write_csr!(CSR_HVIP, 0);
write_csr!(CSR_VSATP, 0);
}
write_csr!(CSR_SSCRATCH, self as *const _ as usize) 延续了上一个方法的内容,将 ArchCpu 的地址写入 sscratch 。将返回地址设置为入口,将 hstatus 的 SPV 字段设置为1,代表返回vm的时候vm是运行在VS态下的(或理解为异常发生前的vm是在VS态运行的);VSXL 字段设置了VS模式下寄存器的长度。sstatus 的 SPP 等字段给出 Trap 发生之前 CPU 处在哪个特权级等信息。SPP 与 SPV 字段,结合起来使用,能够确定在HS模式下执行 sret 指令应该返回哪个特权级,返回的地址由 spec 设置。
HIDELEG 和 CSR_HEDELEG 这两个寄存器的设置是将某些中断委托给VS态处理。HCOUNTEREN 和 SCOUNTEREN 用于限制vm能够访问的性能计数器,此处是使能了 TM 字段,代表允许访问 time 寄存器。HTIMEDELTA 用于调整vm读取 time 寄存器的值,在VS或者VU模式下读取 time 将返回 HTIMEDELTA 和 time 的和。SIE 的作用的中断使能,我们开启了所有中断。
在代码中注意 write_csr! 和 set_csr! 的区别,write_csr! 采用的是直接写入,也就是覆盖的方法,而 set_csr! 则是采用“or”的做法,设置某些位。
ArchCpu::idle
通过执行wfi指令,将非主cpu设置为低功耗的idle状态。
设置一个特殊的内存页,包含了使得CPU进入低功耗等待状态的指令,从而在系统中未分配任何任务给某些CPU时,可以将它们置于低功耗等待状态,直到发生中断。
pub fn idle(&mut self) -> ! {
extern "C" {
fn vcpu_arch_entry() -> !;
}
assert!(this_cpu_id() == self.cpuid);
self.init(0, this_cpu_data().id, this_cpu_data().opaque);
// reset current cpu -> pc = 0x0 (wfi)
PARKING_MEMORY_SET.call_once(|| {
let parking_code: [u8; 4] = [0x73, 0x00, 0x50, 0x10]; // 1: wfi; b 1b
unsafe {
PARKING_INST_PAGE[..4].copy_from_slice(&parking_code);
}
let mut gpm = MemorySet::<Stage2PageTable>::new();
gpm.insert(MemoryRegion::new_with_offset_mapper(
0 as GuestPhysAddr,
unsafe { &PARKING_INST_PAGE as *const _ as HostPhysAddr - PHYS_VIRT_OFFSET },
PAGE_SIZE,
MemFlags::READ | MemFlags::WRITE | MemFlags::EXECUTE,
))
.unwrap();
gpm
});
unsafe {
PARKING_MEMORY_SET.get().unwrap().activate();
vcpu_arch_entry();
}
}
将该cpu的入口地址设置为0,而0地址将会被映射到 parking page ,parking page 中设置了一些wfi指令的编码。wfi指令使得CPU进入等待状态,直到有中断发生。
然后进入 vcpu_arch_entry ,vcpu_arch_entry 指向一段汇编代码,功能是根据 sscratch 找到 ArchCpu 进行上下文的恢复,然后执行 sret ,返回到 spec 的地址处执行,即执行刚刚设置的wfi指令(而不是内核代码),进入低功耗模式。
虽然在这里也进行了一些初始化的工作,但是并没有将cpu的初始化标志 init 设置为 true ,所以后续真正要唤醒并运行该cpu时,会重新进行初始化(在run方法中体现)。
ArchCpu::run
该方法主要内容是进行了一些初始化,设置了正确的cpu执行入口,以及修改cpu已初始化的标志。
pub fn run(&mut self) -> ! {
extern "C" {
fn vcpu_arch_entry() -> !;
}
assert!(this_cpu_id() == self.cpuid);
//change power_on
this_cpu_data().activate_gpm();
if !self.init {
self.init(
this_cpu_data().cpu_on_entry,
this_cpu_data().id,
this_cpu_data().opaque, //dtb_ipa
);
self.init = true;
}
self.power_on = true;
info!("CPU{} run@{:#x}", self.cpuid, self.sepc);
info!("CPU{:#x?}", self);
unsafe {
vcpu_arch_entry();
}
}
可以看到这次的初始化,正确设置了cpu的入口地址,该入口地址指向内核的代码。然后进入 vcpu_arch_entry 执行,恢复上下文,再返回到内核的代码执行。
vcpu_arch_entry / VM_ENTRY
这是一段汇编代码,描述的是从hvisor进入vm的时候需要处理的工作。首先就是通过 sscratch 寄存器得到原本的 ArchCpu 中的上下文信息,再将 hstatus 、sstatus 、sepc 设置成之前我们保存的值,保证返回到vm的时候是VS态、并且从正确位置开始执行。最后恢复通用寄存器的值,并使用 sret 返回vm。
.macro VM_ENTRY
csrr x31, sscratch
ld x1, 32*8(x31)
csrw hstatus, x1
ld x1, 33*8(x31)
csrw sstatus, x1
ld x1, 34*8(x31)
csrw sepc, x1
ld x0, 0*8(x31)
...
ld x31, 31*8(x31)
sret
j .
.endm
VM_EXIT
从vm退出进入hvisor时,也需要保存vm退出时候的相关状态。
首先还是通过 sscratch 寄存器得到 ArchCpu 的地址,但在这里我们会交换 sscratch 和 x31 的信息,而不是直接覆盖 x31 。然后将除 x31 外的通用寄存器的值进行保存,那么 x31 的信息现在在 sscratch 中,所以我们先把 x31 的值保存到 sp ,再交换 x31 和 sscratch ,将 x31 的信息通过 sp 存到 ArchCpu 的对应位置。
再将 hstatus 、sstatus 、sepc 进行保存,当我们在hvisor处理完工作,将要返回vm的时候,需要用到VM_ENTRY的代码,将这三个寄存器的值进行恢复到vm进入hvisor之前的状态,所以在这里我们应该进行保存。
ld sp, 35*8(sp) 将 ArchCpu 所保存的内核栈的栈顶放到 sp 中进行使用,便于我们在hvisor中去使用内核栈。
csrr a0, sscratch 这一句,将 sscratch 的值放到 a0 寄存器中,当我们保存完上下文,跳转到异常处理函数的时候,参数将会通过 a0 传递,那么在异常处理的时候就能够访问保存起来的上下文,比如退出码等等。
.macro VM_EXIT
csrrw x31, sscratch, x31
sd x0, 0*8(x31)
...
sd x30, 30*8(x31)
mv sp, x31
csrrw x31, sscratch, x31
sd x31, 31*8(sp)
csrr t0, hstatus
sd t0, 32*8(sp)
csrr t0, sstatus
sd t0, 33*8(sp)
csrr t0, sepc
sd t0, 34*8(sp)
ld sp, 35*8(sp)
csrr a0, sscratch
.endm
LoongArch 处理器虚拟化
LoongArch指令集是中国龙芯中科公司于2020年发布的自主RISC指令集,包括基础指令集、二进制翻译拓展(LBT)、向量拓展(LSX)、高级向量扩展(LASX)和虚拟化拓展(LVZ)五个模块。
本文将主要对LoongArch指令集的CPU虚拟化设计进行简要介绍,其相关说明来自目前已经公开的KVM源代码以及代码注释。
LoongArch寄存器简介
通用寄存器使用约定[1]
| 名称 | 别名 | 用途 | 在调用中是否保留 |
|---|---|---|---|
$r0 | $zero | 常数 0 | (常数) |
$r1 | $ra | 返回地址 | 否 |
$r2 | $tp | 线程指针 | (不可分配) |
$r3 | $sp | 栈指针 | 是 |
$r4 - $r5 | $a0 - $a1 | 传参寄存器、返回值寄存器 | 否 |
$r6 - $r11 | $a2 - $a7 | 传参寄存器 | 否 |
$r12 - $r20 | $t0 - $t8 | 临时寄存器 | 否 |
$r21 | 保留 | (不可分配) | |
$r22 | $fp / $s9 | 栈帧指针 / 静态寄存器 | 是 |
$r23 - $r31 | $s0 - $s8 | 静态寄存器 | 是 |
浮点寄存器使用约定[1]
| 名称 | 别名 | 用途 | 在调用中是否保留 |
|---|---|---|---|
$f0 - $f1 | $fa0 - $fa1 | 传参寄存器、返回值寄存器 | 否 |
$f2 - $f7 | $fa2 - $fa7 | 传参寄存器 | 否 |
$f8 - $f23 | $ft0 - $ft15 | 临时寄存器 | 否 |
$f24 - $f31 | $fs0 - $fs7 | 静态寄存器 | 是 |
临时寄存器也被称为调用者保存寄存器。 静态寄存器也被称为被调用者保存寄存器。
CSR寄存器
控制状态寄存器(Control and Status Register, CSR) 是LoongArch架构中一类特殊的寄存器,用于控制处理器的运行状态。 控制状态寄存器一览表(不包括LVZ虚拟化拓展中新的CSR):
| 编号 | 名称 | 编号 | 名称 | 编号 | 名称 |
|---|---|---|---|---|---|
| 0x0 | 当前模式信息 CRMD | 0x1 | 例外前模式信息 PRMD | 0x2 | 扩展部件使能 EUEN |
| 0x3 | 杂项控制 MISC | 0x4 | 例外配置 ECFG | 0x5 | 例外状态 ESTAT |
| 0x6 | 例外返回地址 ERA | 0x7 | 出错虚地址 BADV | 0x8 | 出错指令 BADI |
| 0xc | 例外入口地址 EENTRY | 0x10 | TLB 索引 TLBIDX | 0x11 | TLB 表项高位 TLBEHI |
| 0x12 | TLB 表项低位 0 TLBELO0 | 0x13 | TLB 表项低位 1 TLBELO1 | 0x18 | 地址空间标识符 ASID |
| 0x19 | 低半地址空间全局目录基址 PGDL | 0x1A | 高半地址空间全局目录基址 PGDH | 0x1B | 全局目录基址 PGD |
| 0x1C | 页表遍历控制低半部分 PWCL | 0x1D | 页表遍历控制高半部分 PWCH | 0x1E | STLB 页大小 STLBPS |
| 0x1F | 缩减虚地址配置 RVACFG | 0x20 | 处理器编号 CPUID | 0x21 | 特权资源配置信息 1 PRCFG1 |
| 0x22 | 特权资源配置信息 2 PRCFG2 | 0x23 | 特权资源配置信息 3 PRCFG3 | 0x30+n (0≤n≤15) | 数据保存 SAVEn |
| 0x40 | 定时器编号 TID | 0x41 | 定时器配置 TCFG | 0x42 | 定时器值 TVAL |
| 0x43 | 计时器补偿 CNTC | 0x44 | 定时中断清除 TICLR | 0x60 | LLBit 控制 LLBCTL |
| 0x80 | 实现相关控制 1 IMPCTL1 | 0x81 | 实现相关控制 2 IMPCTL2 | 0x88 | TLB 重填例外入口地址 TLBRENTRY |
| 0x89 | TLB 重填例外出错虚地址 TLBRBADV | 0x8A | TLB 重填例外返回地址 TLBRERA | 0x8B | TLB 重填例外数据保存 TLBRSAVE |
| 0x8C | TLB 重填例外表项低位 0 TLBRELO0 | 0x8D | TLB 重填例外表项低位 1 TLBRELO1 | 0x8E | TLB 重填例外表项高位 TLBREHI |
| 0x8F | TLB 重填例外前模式信息 TLBRPRMD | 0x90 | 机器错误控制 MERRCTL | 0x91 | 机器错误信息 1 MERRINFO1 |
| 0x92 | 机器错误信息 2 MERRINFO2 | 0x93 | 机器错误例外入口地址 MERRENTRY | 0x94 | 机器错误例外返回地址 MERRERA |
| 0x95 | 机器错误例外数据保存 MERRSAVE | 0x98 | 高速缓存标签 CTAG | 0x180+n (0≤n≤3) | 直接映射配置窗口 n DMWn |
| 0x200+2n (0≤n≤31) | 性能监测配置 n PMCFGn | 0x201+2n (0≤n≤31) | 性能监测计数器 n PMCNTn | 0x300 | load/store 监视点整体控制 MWPC |
| 0x301 | load/store 监视点整体状态 MWPS | 0x310+8n (0≤n≤7) | load/store 监视点 n 配置 1 MWPnCFG1 | 0x311+8n (0≤n≤7) | load/store 监视点 n 配置 2 MWPnCFG2 |
| 0x312+8n (0≤n≤7) | load/store 监视点 n 配置 3 MWPnCFG3 | 0x313+8n (0≤n≤7) | load/store 监视点 n 配置 4 MWPnCFG4 | 0x380 | 取指监视点整体控制 FWPC |
| 0x381 | 取指监视点整体状态 FWPS | 0x390+8n (0≤n≤7) | 取指监视点 n 配置 1 FWPnCFG1 | 0x391+8n (0≤n≤7) | 取指监视点 n 配置 2 FWPnCFG2 |
| 0x392+8n (0≤n≤7) | 取指监视点 n 配置 3 FWPnCFG3 | 0x393+8n (0≤n≤7) | 取指监视点 n 配置 4 FWPnCFG4 | 0x500 | 调试寄存器 DBG |
| 0x501 | 调试例外返回地址 DERA | 0x502 | 调试数据保存 DSAVE |
对于实现了LVZ虚拟化拓展的处理器,还有一组用于控制虚拟化的CSR寄存器[3]。
| 编号 | 名称 |
|---|---|
| 0x15 | 客户机TLB控制 GTLBC |
| 0x16 | TLBRD读Guest项 TRGP |
| 0x50 | 客户机状态 GSTAT |
| 0x51 | 客户机控制 GCTL |
| 0x52 | 客户机中断控制 GINTC |
| 0x53 | 客户机计数器补偿 GCNTC |
GCSR寄存器组
在实现虚拟化的LoongArch处理器中会额外有一组 GCSR(Guest Control and Status Register) 寄存器。
进入Guest模式的流程(来自Linux KVM源码)[3]
-
【
switch_to_guest】: -
清空
CSR.ECFG.VS字段(设置为0,即所有异常共用一个入口地址) -
读取Hypervisor中保存的guest eentry(客户OS中断向量地址)-> GEENTRY
- 然后将GEENTRY写入
CSR.EENTRY
- 然后将GEENTRY写入
-
读取Hypervisor中保存的guest era(客户OS异常返回地址)-> GPC
- 然后将GPC写入
CSR.ERA
- 然后将GPC写入
-
读取
CSR.PGDL全局页表地址,存到Hypervisor中 -
从Hypervisor中加载guest pgdl到
CSR.PGDL -
读出
CSR.GSTAT.GID和CSR.GTLBC.TGID,写入CSR.GTLBC -
将
CSR.PRMD.PIE置1,打开Hypervisor级的全局中断 -
将
CSR.GSTAT.PGM置1,其目的是使ertn指令进入guest mode -
Hypervisor将自己保存的该guest的通用寄存器(GPRS)恢复到硬件寄存器上(恢复现场)
-
执行
ertn指令,进入guest模式
虚拟化相关的异常[2][3]
| code | subcode | 缩写 | 介绍 |
|---|---|---|---|
| 22 | - | GSPR | 客户机敏感特权资源异常,由cpucfg、idle、cacop指令触发,以及在虚拟机访问了不存在的GCSR和IOCSR时触发,强制陷入Hypervisor进行处理(如软件模拟) |
| 23 | - | HVC | hvcl超级调用指令触发的异常 |
| 24 | 0 | GCM | 客户机GCSR软件修改异常 |
| 24 | 1 | GCHC | 客户机GCSR硬件修改异常 |
处理Guest模式下异常的流程(来自Linux KVM源码)[3]
-
【
kvm_exc_entry】: -
Hypervisor首先保存好guest的通用寄存器(GPRS),保护现场。
-
Hypervisor保存
CSR.ESTAT-> host ESTAT -
Hypervisor保存
CSR.ERA-> GPC -
Hypervisor保存
CSR.BADV-> host BADV,即触发地址错误例外时,记录出错的虚拟地址 -
Hypervisor保存
CSR.BADI-> host BADI,该寄存器用于记录触发同步类例外的指令的指令码,所谓同步类例外是指除了中断(INT)、客户机CSR硬件修改例外(GCHC)、机器错误例外(MERR)之外的所有例外。 -
读取Hypervisor保存好的host ECFG,写入
CSR.ECFG(即切换到host下的异常配置) -
读取Hypervisor保存好的host EENTRY,写入
CSR.EENTRY -
读取Hypervisor保存好的host PGD,写入
CSR.PGDL(恢复host页表全局目录基址,低半空间) -
设置
CSR.GSTAT.PGM关闭 -
清空
GTLBC.TGID域 -
恢复kvm per cpu寄存器
- kvm汇编里涉及到KVM_ARCH_HTP, KVM_ARCH_HSP, KVM_ARCH_HPERCPU
-
跳转到KVM_ARCH_HANDLE_EXIT位置处理异常
-
判断刚才的函数ret是否<=0
- 若<=0,则继续运行host
- 否则继续运行guest,保存percpu寄存器,因为可能会切换到不同的CPU继续运行guest。保存host percpu寄存器到
CSR.KSAVE寄存器
-
跳转到
switch_to_guest
vCPU上下文需要保存的寄存器
由LoongArch函数调用规范可知如果需要手动切换CPU函数运行上下文,需要保存的寄存器如下(不考虑浮点寄存器):$s0-$s9、$sp、$ra
参考资料
[1] 龙芯中科技术股份有限公司.龙芯架构ELF psABI规范.Version 2.01.
[2] 龙芯中科技术股份有限公司.龙芯架构参考手册.卷一:基础架构.
[3] https://github.com/torvalds/linux/blob/master/arch/loongarch/kvm/switch.S.
X86_64 架构下的 CPU 虚拟化
Intel VT-x
Intel 与 AMD 作为 x86 架构的两大厂商,分别推出了自己的硬件辅助虚拟化技术。Intel 将其命名为 VT-x 或 VMX,AMD 则称之为 AMD-V 或 SVM。Hvisor 实现了基于 Intel VT-x 的虚拟化,因此本小节重点围绕 VT-x 展开介绍。VT-x 引入了两种运行模式,统称为 VMX(Virtual Machine eXtension)操作模式,分别为:
- 根操作模式(VMX root operation),简称根模式,hypervisor 在此模式下运行。
- 非根操作模式(VMX non-root operation),简称非根模式,guest OS 在此模式下运行。
这两种模式均支持 Ring 0 至 Ring 3,guest OS 内核可以直接运行在非根模式下的 Ring 0 中,不再需要对特权级进行压缩。hypervisor 使用 vmlaunch 指令可将处理器从根模式切换到非根模式并进入 guest OS,这一过程被称为 VM entry。当 guest OS 执行某些需由 hypervisor 接管的操作时,会从非根模式返回到根模式,这一过程被称为 VM exit。相较于早期虚拟化机制以是否为特权指令作为陷入条件,VT-x 采用更灵活的策略,仅在 guest OS 执行敏感指令时才触发 VM exit。
在 CPU 虚拟化中,多个 vCPU 可以共享同一个 pCPU,其调度由 hypervisor 统一管理。当某个 vCPU 被分配到 pCPU 上运行时,基于该 vCPU 的 guest OS 就可以正常调度其内部的进程。也就是说,guest OS 内部的进程以时间片方式复用 vCPU,而多个 vCPU 又轮流使用底层的 pCPU。每当 vCPU 获得或释放 pCPU,或者在运行期间发生根模式与非根模式之间的切换,都会触发上下文切换。
VT-x 针对这种因资源复用引发的上下文切换,提供了底层硬件支持。每个 vCPU 都配备了一个独立的虚拟机控制结构(virtual machine control structures,VMCS),可类比为进程调度使用的上下文结构。hypervisor 可在发生上下文切换时,借助 VMCS 保存或恢复 vCPU 的运行状态,从而实现高效的 pCPU 共享机制。每个 VMCS 占据一块大小为 4KB 的物理内存,称为 VMCS region,其内部依照功能不同被划分为多个区域:
- Guest-state area:用于保存 guest OS 的当前运行状态。在发生 VM exit 时,CPU 会自动将 guest OS 的相关状态写入此区域;而在 VM entry 时,则会从该区域加载并恢复 guest OS 的运行上下文。
- Host-state area:该区域仅在 VM exit 时使用,用于恢复 hypervisor 的预设状态。由于进入 hypervisor 类似于触发中断,因此每次 VM exit 直接使用固定的上下文即可,无需在 VM entry 时保存 hypervisor 的上下文。
- VM-exit information fields:由硬件在 VM exit 发生时自动填写,记录 guest OS 退出的原因,供 hypervisor 后续处理使用。
- VM-execution/entry/exit control fields:用于配置 CPU 在非根模式下的运行行为、进入与退出条件等控制信息。
Hvisor 的 CPU 虚拟化实现
Hvisor 使用 PerCpu 结构体封装 pCPU 的虚拟化功能,该结构体内部包含一个名为 arch_cpu 的字段,类型为 ArchCpu,由各体系架构自行实现。x86 架构下的 ArchCpu 主要包含以下字段:
guest_regs:用于在 VM exit 时保存 zone 的通用寄存器状态,并在 VM entry 时进行恢复。由于通用寄存器不包含在 VMCS 的 guest-state 区域中,因此需要由软件负责保存与恢复。vmcs_region:当前 vCPU 使用的 VMCS 区域。
Hvisor 在完成 rust_main() 中的初始化步骤后,会进入 PerCpu 提供的 run_vm() 方法,并最终由 ArchCpu 接管虚拟化的相关流程。在 x86 架构下的 ArchCpu 实现中,Hvisor 会首先检测当前 pCPU 是否支持 VT-x。如果支持,执行 vmxon 指令使能 VMX。随后,调用 setup_vmcs() 方法,将 vmcs_region 绑定至当前的 pCPU,并完成必要的 VMCS 配置。
虚拟化准备工作完成后,Hvisor 执行 vmlaunch 指令正式进入非根模式。如果当前 vCPU 是 zone0 的 BSP,控制流将跳转至 zone0 的入口地址,执行客户机操作系统的初始化流程;其余 vCPU 则进入一段循环的 guest 代码,等待被 zone0 BSP 唤醒。当 zone0 BSP 运行到多核启动阶段时,会向其余 vCPU 发送 INIT 和 Start-up 类型的 IPI。Hvisor 会在此时唤醒目标 vCPU,使其从 IPI 信号提供的入口地址进入 zone0。
如果 vCPU 在非根模式下触发 VM exit,控制流将返回根模式,并根据 VMCS 预先配置的 host RIP 字段跳转至 ArchCpu::vmx_exit_handler(),运行相应的处理程序。处理完成后,Hvisor 再执行 vmresume 指令,重新回到非根模式。
使能 VMX
在使能 VMX 之前,Hvisor 首先需通过 cpuid 指令确认 pCPU 是否支持 VT-x。若支持,则进一步检查 BIOS 是否启用了 vmxon。具体方法是读取 IA32_FEATURE_CONTROL 特定模块寄存器(model specific register, MSR),主要关注其中的第 0 位(lock bit)和第 2 位(enable VMX outside SMX operation)。如果第 2 位为 1,说明可以继续启用 VMX;反之,则需要将其置为 1。但该操作只能在第 0 位为 0 的情况下进行。若 lock bit 为 1 且第 2 位为 0,意味着 BIOS 已显式禁用了 vmxon,此时需要在 BIOS 设置中手动开启。
确认当前 pCPU 支持 VT-x 且未禁用 vmxon 后,Hvisor 会将控制寄存器 CR4 的第 13 位(VMXE)设置为 1,为 ArchCpu::vmxon_region 分配一块 4KB 的内存空间,最后执行 vmxon 指令并传入 vmxon_region 的地址,实现 VMX 的使能。由于 vmxon 指令仅对当前执行的 pCPU 生效,因此每个 pCPU 都必须分别执行一次 vmxon,并使用独立的 vmxon_region 内存区域。
VMCS 配置
在执行 vmlaunch 首次进入非根模式之前,Hvisor 需要完成对 VMCS 的配置,该过程由 setup_vmcs() 方法负责。在该方法中,首先为 ArchCpu::vmcs_region 分配一块 4KB 内存,接着通过 vmclear 和 vmptrld 指令将其与当前 pCPU 绑定,并依次调用 setup_vmcs_host()、setup_vmcs_guest() 和 setp_vmcs_control() 完成对 VMCS 各区域的配置。需要注意的是,VMCS 的读写必须通过 vmread 和 vmwrite 指令完成,不能直接使用普通内存访问操作。
-
setup_vmcs_host()用于配置 VMCS 的 host-state 区域。大多数字段可以直接读取当前 Hvisor 的寄存器状态进行设置。而指令指针host RIP需要写入ArchCpu::vmx_exit_handler()的地址,使得 VM exit 时会自动跳转到处理程序中。栈指针host RSP也要进行特殊设置,以实现 vCPU 的上下文切换,下文将予以介绍。 -
setup_vmcs_guest()负责 guest-state 区域的初始化。Hvisor 选择以 16 位实模式启动 zone,因此需要关闭guest CR0中的保护模式位PE和分页位PG,并配置guest CR0的guest/host mask及read shadow,使得 zone 可以在之后自行修改guest CR0以进入保护模式和长模式。由于实模式下并没有段描述符与页表,Hvisor 无需为客户机进行 GDT 和页表的配置,在实现上更加简便。但若是希望从 32 位入口点进入 zone,则必须借助一段额外的 16 位跳板代码,在非根模式下完成 GDT 的初始化并切换至保护模式。 -
setp_vmcs_control()负责设置 VMCS 中的 VM-execution/entry/exit control 区域。对该区域的配置包括但不限于:在primary processor-based VM-execution controls(以下简称primary controls)中禁用对CR3的读写拦截,允许 zone 自由切换页表;在secondary processor-based VM-execution controls(以下简称secondary controls)中启用unrestricted guest,允许 zone 在实模式下运行。
vCPU 上下文切换
在 VM entry 与 VM exit 的过程中,硬件会利用 VMCS 自动完成 Hvisor 与 zone 的上下文切换。但这一机制并不涵盖 zone 的通用寄存器(general purpose registers, GPR),需由软件显式保存与恢复。因此,在执行 vmlaunch 或 vmresume 之前,需从内存中恢复 zone 的 GPR;而在 VM exit 后,尽管 VMCS 已完成状态切换,但通用寄存器中仍保留着 zone GPR,需在此时将其保存至特定内存区域,供后续 VM exit 处理程序访问。
Hvisor 使用 ArchCpu::guest_regs 字段专门保存 zone GPR,并将其末尾位置作为 VM exit 时的临时栈顶。同时,ArchCpu::host_stack_top 字段负责记录 Hvisor 的真实栈顶。在配置 VMCS 时,将 host RSP 设置为临时栈顶的地址。这样在发生 VM exit 时,硬件会首先将栈指针指向 guest_regs 的末尾,Hvisor 随即将 zone GPR 压入临时栈,即 guest_regs 所在内存区域。等到 zone GPR 保存完成后,再将栈指针恢复为 host_stack_top 的值,回到真实的 Hvisor 栈中。而在 VM entry 进入 zone 之前,Hvisor 还需将栈指针设置为 guest_regs 的起始地址,从该处依次弹出并恢复 zone GPR。
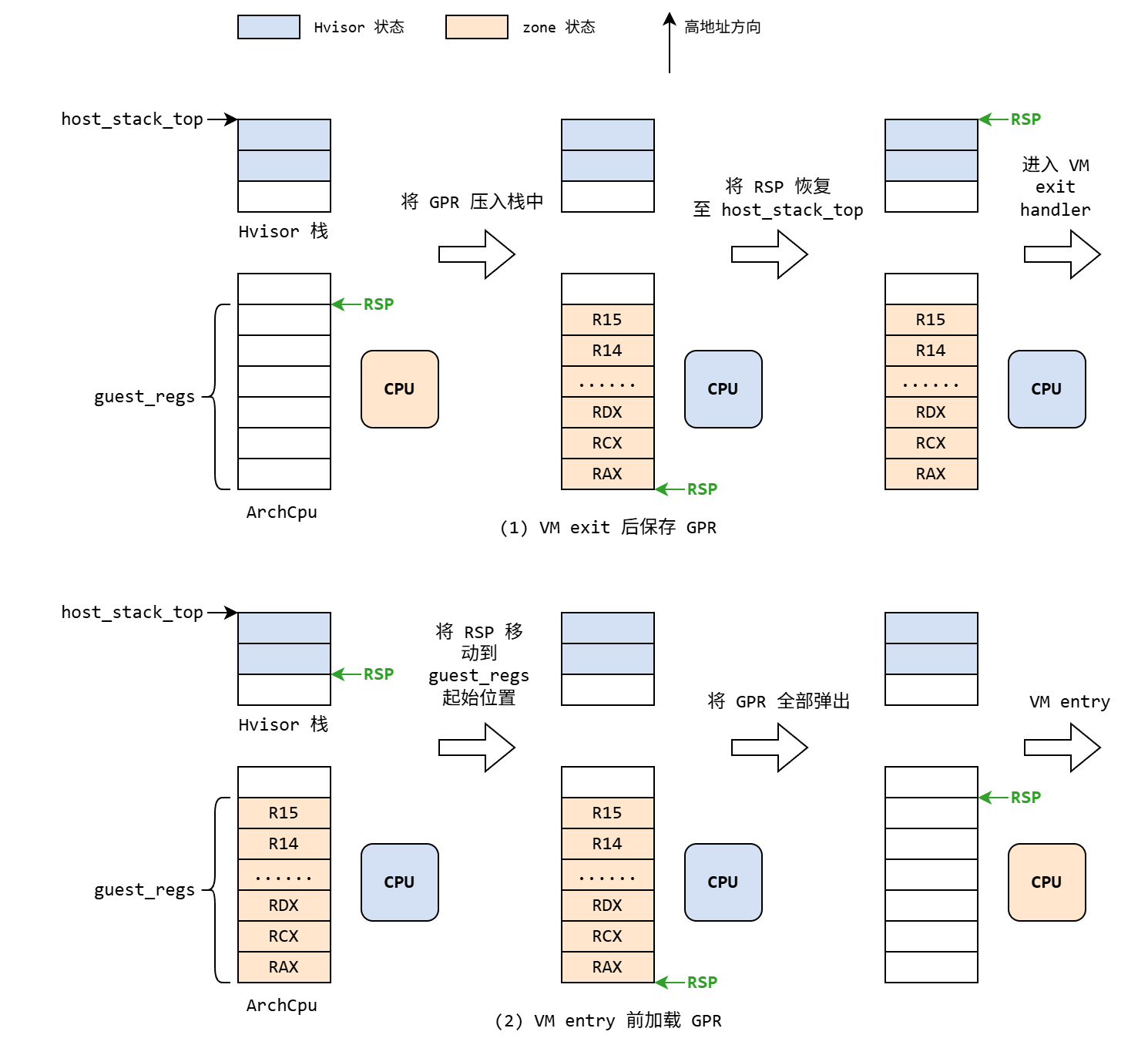
内存管理
堆上的内存分配
初始化分配器
平常在使用编程语言的时候,会遇到动态分配内存,比如在C语言中通过 malloc 或者 new 分配一块内存,再比如Rust中的 Vec 、String 等,都是在堆上分配内存。
为了能够在堆上分配内存,我们需要做以下这些事情:
- 初始化的时候提供一大块内存空间
- 提供分配和释放的接口
- 管理空闲块
总之,我们需要分配一大段空间,并且要设置一个分配器,将这段空间交给分配器管理,并且告诉Rust,我们现在有一个分配器了,请你把它用起来,允许我们使用 Vec 、String 这种在堆上分配内存的变量。也就是下面这几句在做的事情。
use buddy_system_allocator::LockedHeap;
use crate::consts::HV_HEAP_SIZE;
#[cfg_attr(not(test), global_allocator)]
static HEAP_ALLOCATOR: LockedHeap<32> = LockedHeap::<32>::new();
/// Initialize the global heap allocator.
pub fn init() {
const MACHINE_ALIGN: usize = core::mem::size_of::<usize>();
const HEAP_BLOCK: usize = HV_HEAP_SIZE / MACHINE_ALIGN;
static mut HEAP: [usize; HEAP_BLOCK] = [0; HEAP_BLOCK];
let heap_start = unsafe { HEAP.as_ptr() as usize };
unsafe {
HEAP_ALLOCATOR
.lock()
.init(heap_start, HEAP_BLOCK * MACHINE_ALIGN);
}
info!(
"Heap allocator initialization finished: {:#x?}",
heap_start..heap_start + HV_HEAP_SIZE
);
}
#[cfg_attr(not(test), global_allocator)] 是条件编译的属性,仅当不在测试环境中时,将下一行定义的 HEAP_ALLOCATOR设置为Rust的全局内存分配器,现在Rust知道我们可以进行动态分配了。
HEAP_ALLOCATOR.lock().init(heap_start, HEAP_BLOCK * MACHINE_ALIGN) 将我们申请的一大段空间交给分配器管理。
测试
pub fn test() {
use alloc::boxed::Box;
use alloc::vec::Vec;
extern "C" {
fn sbss();
fn ebss();
}
let bss_range = sbss as usize..ebss as usize;
let a = Box::new(5);
assert_eq!(*a, 5);
assert!(bss_range.contains(&(a.as_ref() as *const _ as usize)));
drop(a);
let mut v: Vec<usize> = Vec::new();
for i in 0..500 {
v.push(i);
}
for (i, val) in v.iter().take(500).enumerate() {
assert_eq!(*val, i);
}
assert!(bss_range.contains(&(v.as_ptr() as usize)));
drop(v);
info!("heap_test passed!");
}
在这段测试中,使用 Box 和 Vec 来检验我们分配的内存,是否在 bss 段中。
我们刚才交给分配器的一大段内存,是一个未初始化的全局变量,会被放在 bss 段,只需要测试我们获得变量的地址是否在这个范围内即可。
Armv8的内存管理知识
寻址
地址总线默认48位,而发出的寻址请求是64位的,所以可以根据高16位将虚拟地址划分为2个空间:
- 高16位为1:内核空间
- 高16位为0:用户空间
站在guestVM的角度,在进行虚拟地址到物理地址的转换的时候,CPU会根据虚拟地址第63位的值选择TTBR寄存器,TTBR寄存器存的是一级页表的基地址,如果是用户空间,选择TTBR0,如果是内核空间,选择TTBR1。
四级页表映射(以页面大小为4K举例)
除了高16位是用来判断使用哪个页表基址寄存器外,后面的36位中,每9位作为每一级页表的页表项的索引,低12位为页内偏移。如下图所示。
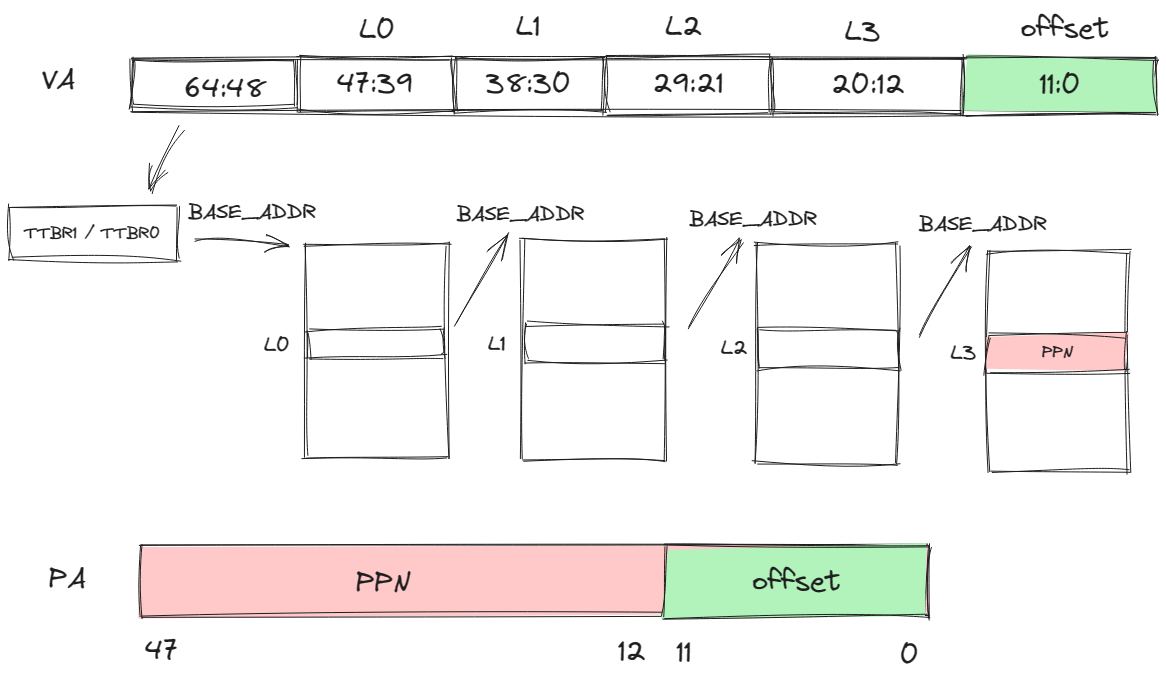
Stage-2页表机制
在开启虚拟化的环境下,系统中存在着两种地址映射过程:
- guestVM通过Stage-1地址转换,利用
TTBR0_EL1或者TTBR1_EL1,将访问的VA转换为IPA,再通过Stage-2地址转换,利用VTTBR0_EL2将IPA转化为PA。 - Hypervisor上可能会跑自己的应用,该应用的VA到PA的转换只需要一次转换,利用
TTBR0_EL2寄存器。
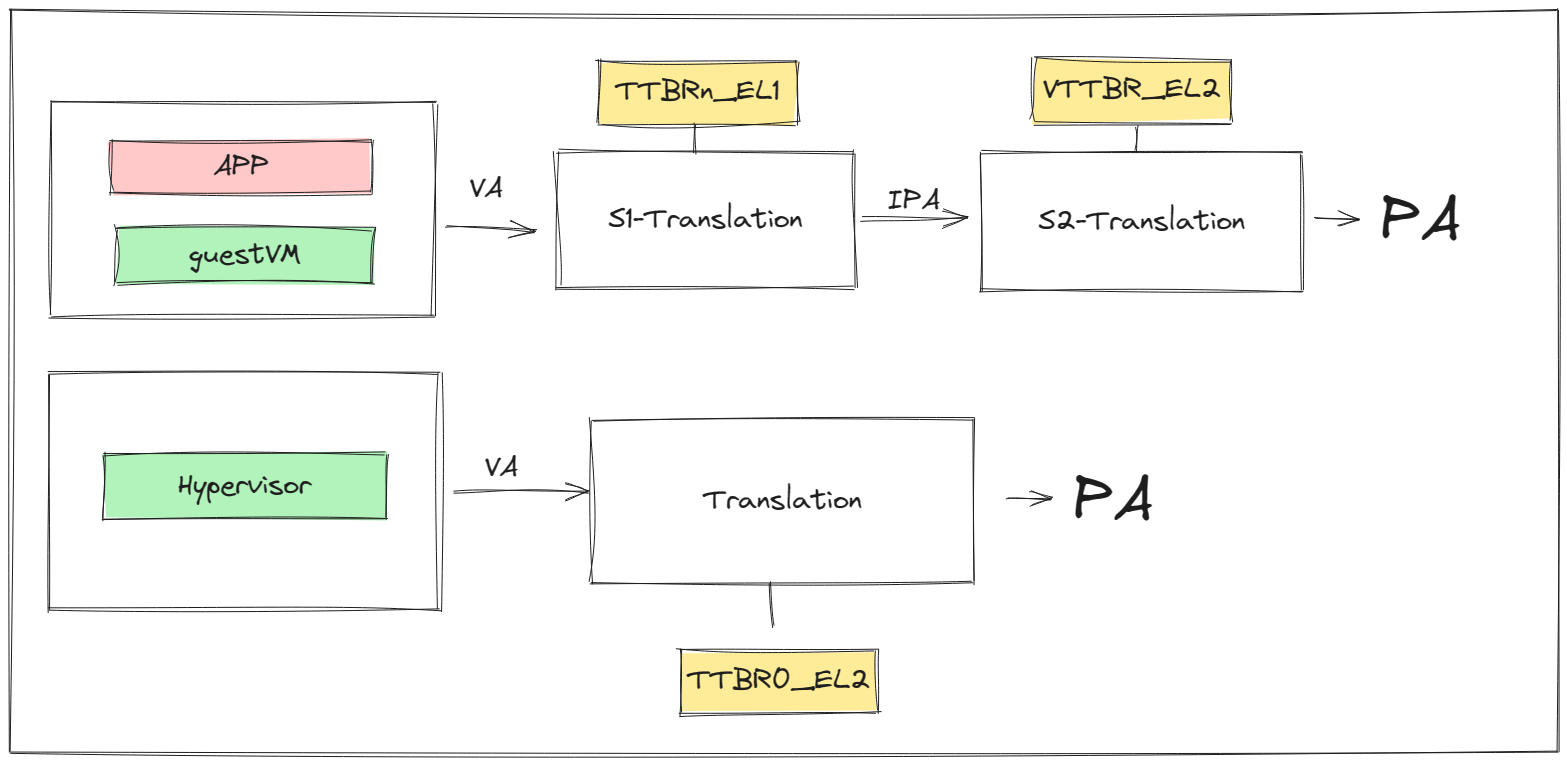
hvsior的内存管理
物理页帧的管理
和上面关于堆的构造类似,页帧的分配也需要一个分配器,然后把我们用来分配的一段内存交给分配器管理。
基于位图的分配器
use bitmap_allocator::BitAlloc;
type FrameAlloc = bitmap_allocator::BitAlloc1M;
struct FrameAllocator {
base: PhysAddr,
inner: FrameAlloc,
}
BitAlloc1M 是一个基于位图的分配器,它通过管理页面编号,提供哪些页面是空闲的、哪些是占用的信息。
然后将位图分配器和用于页帧分配的起始地址封装成一个页帧分配器。
所以我们看到初始化函数如下:
fn init(&mut self, base: PhysAddr, size: usize) {
self.base = align_up(base);
let page_count = align_up(size) / PAGE_SIZE;
self.inner.insert(0..page_count);
}
传入页帧分配区域的起始地址,以及可供分配的空间大小,计算出这段空间中可供分配的页帧数 page_size,然后将所有页帧的编号通过 insert 函数告诉位图分配器。
页帧的结构
pub struct Frame {
start_paddr: PhysAddr,
frame_count: usize,
}
页帧的结构中包含了这个页帧的起始地址,这个页帧实例对应的页帧数,可能是0、1、或者大于1。
为什么存在页帧数为0的情况?
当hvisor希望访问通过
Frame访问页帧内容时,这时需要一个临时的实例,不涉及页帧分配以及页帧回收,就以0作为一个标志。
为什么存在页帧数大于1的情况?
某些情况下,要求我们分配连续的内存,并且大小超过一个页,也就是分配多个连续页帧。
分配alloc
现在我们知道了页帧分配器可以分配一个空闲页帧的编号,把编号变为以一个 Frame 实例就完成了页帧的分配,单个页帧分配如下:
impl FrameAllocator {
fn init(&mut self, base: PhysAddr, size: usize) {
self.base = align_up(base);
let page_count = align_up(size) / PAGE_SIZE;
self.inner.insert(0..page_count);
}
}
impl Frame {
/// Allocate one physical frame.
pub fn new() -> HvResult<Self> {
unsafe {
FRAME_ALLOCATOR
.lock()
.alloc()
.map(|start_paddr| Self {
start_paddr,
frame_count: 1,
})
.ok_or(hv_err!(ENOMEM))
}
}
}
可以看到帧分配器帮助我们分配一个页帧,并返回起始物理地址,然后再创建 Frame 实例。
页帧的回收
Frame 结构和实际物理页联系在一起,遵循RAII设计规范,那么当一个 Frame 离开作用域,对应的内存区域也需要归还给hvisor。这要求我们实现 Drop Trait 中的 drop 方法,如下:
impl Drop for Frame {
fn drop(&mut self) {
unsafe {
match self.frame_count {
0 => {} // Do not deallocate when use Frame::from_paddr()
1 => FRAME_ALLOCATOR.lock().dealloc(self.start_paddr),
_ => FRAME_ALLOCATOR
.lock()
.dealloc_contiguous(self.start_paddr, self.frame_count),
}
}
}
}
impl FrameAllocator{
unsafe fn dealloc(&mut self, target: PhysAddr) {
trace!("Deallocate frame: {:x}", target);
self.inner.dealloc((target - self.base) / PAGE_SIZE)
}
}
在 drop 中可以看到,帧计数为0的页帧不需要释放对应的物理页,帧计数大于1的说明是连续分配的页帧,需要回收不止一个物理页。
页表相关的数据结构
通过上面有关Armv8内存管理的知识,我们知道构建页表的过程分为两个部分,hvisor自己用的页表,以及Stage-2转换的页表,我们重点介绍Stage-2页表。
在此之前,我们还需要了解几个会用到的数据结构。
逻辑段MemoryRegion
逻辑段的描述,包括起始地址、大小、权限标志、映射方式。
pub struct MemoryRegion<VA> {
pub start: VA,
pub size: usize,
pub flags: MemFlags,
pub mapper: Mapper,
}
地址空间MemorySet
每个进程的地址空间的描述,包括了逻辑段的集合,以及该进程对应的页表。
pub struct MemorySet<PT: GenericPageTable>
where
PT::VA: Ord,
{
regions: BTreeMap<PT::VA, MemoryRegion<PT::VA>>,
pt: PT,
}
4级页表Level4PageTableImmut
root 是L0页表所在的页帧。
pub struct Level4PageTableImmut<VA, PTE: GenericPTE> {
/// Root table frame.
root: Frame,
/// Phantom data.
_phantom: PhantomData<(VA, PTE)>,
}
构建Stage-2页表
我们需要为每个zone都构建一个Stage-2页表。
Stage-2页表需要映射的区域:
- guestVM所见的memory区域
- guestVM会访问的设备树的IPA
- guestVM所见的UART设备的内存区域
向地址空间中添加映射关系
/// Add a memory region to this set.
pub fn insert(&mut self, region: MemoryRegion<PT::VA>) -> HvResult {
assert!(is_aligned(region.start.into()));
assert!(is_aligned(region.size));
if region.size == 0 {
return Ok(());
}
if !self.test_free_area(®ion) {
warn!(
"MemoryRegion overlapped in MemorySet: {:#x?}\n{:#x?}",
region, self
);
return hv_result_err!(EINVAL);
}
self.pt.map(®ion)?;
self.regions.insert(region.start, region);
Ok(())
}
在地址空间中添加映射关系,除了上面的在我们的 Map 结构中添加虚拟地址和逻辑段的映射关系,还需要在页表中进行映射,如下:
fn map(&mut self, region: &MemoryRegion<VA>) -> HvResult {
assert!(
is_aligned(region.start.into()),
"region.start = {:#x?}",
region.start.into()
);
assert!(is_aligned(region.size), "region.size = {:#x?}", region.size);
trace!(
"create mapping in {}: {:#x?}",
core::any::type_name::<Self>(),
region
);
let _lock = self.clonee_lock.lock();
let mut vaddr = region.start.into();
let mut size = region.size;
while size > 0 {
let paddr = region.mapper.map_fn(vaddr);
let page_size = if PageSize::Size1G.is_aligned(vaddr)
&& PageSize::Size1G.is_aligned(paddr)
&& size >= PageSize::Size1G as usize
&& !region.flags.contains(MemFlags::NO_HUGEPAGES)
{
PageSize::Size1G
} else if PageSize::Size2M.is_aligned(vaddr)
&& PageSize::Size2M.is_aligned(paddr)
&& size >= PageSize::Size2M as usize
&& !region.flags.contains(MemFlags::NO_HUGEPAGES)
{
PageSize::Size2M
} else {
PageSize::Size4K
};
let page = Page::new_aligned(vaddr.into(), page_size);
self.inner
.map_page(page, paddr, region.flags)
.map_err(|e: PagingError| {
error!(
"failed to map page: {:#x?}({:?}) -> {:#x?}, {:?}",
vaddr, page_size, paddr, e
);
e
})?;
vaddr += page_size as usize;
size -= page_size as usize;
}
Ok(())
}
我们大概解读一下上面这段函数,对于一个逻辑段 MemoryRegion ,我们以页为单位进行映射,每次映射一个页,直到覆盖整个逻辑段的大小。
具体的行为如下:
在对每一页映射之前,首先我们根据逻辑段的映射方式,确定这一页映射后对应的物理地址 paddr 。
然后确定页面的大小 page_size ,我们从1G的页面开始判断,如果物理地址能够对齐,剩下未映射的页面大小大于1G,并且没有禁用大页面映射,则选择1G作为页面大小,否则再检查2M页面大小,如果都不满足,则使用常规的4KB大小的页面。
目前我们获取了需要填充到页表项的信息了,我们将页面起始地址和页面大小合并为一个 Page 实例,在页表中进行映射,也就是修改页表项:
fn map_page(
&mut self,
page: Page<VA>,
paddr: PhysAddr,
flags: MemFlags,
) -> PagingResult<&mut PTE> {
let entry: &mut PTE = self.get_entry_mut_or_create(page)?;
if !entry.is_unused() {
return Err(PagingError::AlreadyMapped);
}
entry.set_addr(page.size.align_down(paddr));
entry.set_flags(flags, page.size.is_huge());
Ok(entry)
}
简单阐述这个函数的功能:首先我们根据VA,准确的说是根据这个VA对应的页号VPN,获取到对应的PTE,在PTE中填入控制位信息,以及物理地址(其实应该是PPN),具体可以在 PageTableEntry 中的set_addr方法看到,我们并没有把整个物理地址都填入,而是填入了除低12位以外的内容,因为我们的页表只关注页帧号的映射。
我们重点来看下如何获取PTE:
fn get_entry_mut_or_create(&mut self, page: Page<VA>) -> PagingResult<&mut PTE> {
let vaddr: usize = page.vaddr.into();
let p4 = table_of_mut::<PTE>(self.inner.root_paddr());
let p4e = &mut p4[p4_index(vaddr)];
let p3 = next_table_mut_or_create(p4e, || self.alloc_intrm_table())?;
let p3e = &mut p3[p3_index(vaddr)];
if page.size == PageSize::Size1G {
return Ok(p3e);
}
let p2 = next_table_mut_or_create(p3e, || self.alloc_intrm_table())?;
let p2e = &mut p2[p2_index(vaddr)];
if page.size == PageSize::Size2M {
return Ok(p2e);
}
let p1 = next_table_mut_or_create(p2e, || self.alloc_intrm_table())?;
let p1e = &mut p1[p1_index(vaddr)];
Ok(p1e)
}
首先我们找到L0页表的起始地址,然后根据VA中L0的索引获取对应的页表项 p4e ,不过我们还不可以直接从 p4e 中获取下一级页表的起始地址,可能对应的页表还没创建,如果没有创建,就创建一个新的页表(这个过程也是需要分配页帧的),接着返回页表的起始地址,以此类推,我们获得了最后的L4页表中L4索引对应的页表项PTE。
经过上面这样的过程对memory的映射(UART设备同理),我们还需要将L0页表基址填入VTTBR_EL2寄存器中,这个过程可以在Zone的MemorySet的Level4PageTable的activate函数中看到。
在非虚拟化环境下,guestVM应该还可以访问MMIO和GIC等设备相关的内存区域,为什么没有进行映射?
这是因为虚拟化环境下,hvisor才是资源的管理者,不能随意让guestVM访问设备相关的区域,在前面异常处理中我们提过对MMIO/GIC的访问,实际上会由于没有进行地址映射而陷入EL2,由EL2进行访问后返回结果,如果在页表中进行了映射,那就会直接通过二阶段地址转换访问到资源,而没有经过EL2的控制。
所以在我们的设计中,只是对允许该Zone访问的MMIO在Zone中进行了注册,当发生相关异常的时候用来判断某个MMIO资源是否允许该Zone访问。
ARM GICv3模块
1. GICv3模块
GICv3初始化流程
hvisor中的GICv3初始化流程涉及了GIC分布控制器(GICD)和GIC重新分布控制器(GICR)的初始化,以及中断处理和虚拟中断注入的机制。这一过程的关键步骤:
- SDEI版本检查:通过smc_arg1!(0xc4000020)获取Secure Debug Extensions Interface (SDEI)的版本信息。
- ICCs配置:设置icc_ctlr_el1以仅提供优先级下降功能,设置icc_pmr_el1以定义中断优先级掩码,使能Group 1 IRQs。
- 清除待处理中断:调用gicv3_clear_pending_irqs函数,清除所有待处理的中断,确保系统处于干净状态。
- VMCR和HCR配置:设置ich_vmcr_el2和ich_hcr_el2寄存器,使能虚拟化CPU接口,准备虚拟中断处理。
待处理中断处理
pending_irq函数读取icc_iar1_el1寄存器,返回当前正在处理的中断ID,若值大于等于0x3fe则视为无效中断。deactivate_irq函数通过写入icc_eoir1_el1和icc_dir_el1寄存器来清除中断标志,使能中断。
虚拟中断注入
inject_irq函数检查是否有可用的List Register (LR),并将虚拟中断信息写入其中。此函数区分硬件中断和软件生成中断,适当设置LR中的字段。
GIC数据结构初始化
- GIC是一个全局的Once容器,用于延迟初始化Gic结构体,其中包含了GICD和GICR的基地址及其大小。
- primary_init_early和primary_init_late函数分别在早期和后期初始化阶段配置GIC,使能中断。
区域(Zone)级别的初始化
在Zone结构体中,arch_irqchip_reset方法负责重置分配给特定zone的所有中断,通过直接写入GICD的ICENABLER和ICACTIVER寄存器来实现。
2. vGICv3模块
hvisor的VGICv3(Virtual Generic Interrupt Controller version 3)模块提供了对ARMv8-A架构中GICv3的虚拟化支持。它通过MMIO(Memory Mapped I/O)访问和中断比特图管理来控制和协调不同zone(虚拟机实例)间的中断请求。
MMIO区域注册
在初始化阶段,Zone结构体的vgicv3_mmio_init方法注册了GIC分布控制器(GICD)和每个CPU的GIC重新分布控制器(GICR)的MMIO区域。MMIO区域注册是通过mmio_region_register函数完成的,该函数关联了特定的处理器或中断控制器地址,以及相应的处理函数vgicv3_dist_handler和vgicv3_redist_handler。
中断比特图初始化
Zone结构体的irq_bitmap_init方法用于初始化中断比特图,这是为了跟踪哪些中断属于当前zone。通过遍历提供的中断列表,每个中断都会被插入到比特图中。insert_irq_to_bitmap函数负责将特定的中断号映射到比特图中的相应位置。
MMIO访问限制
restrict_bitmask_access函数用于限制对GICD寄存器的MMIO访问,确保只有属于当前zone的中断才能被修改。该函数检查访问是否针对当前zone的中断,如果是,则更新访问掩码,以允许或限制特定的读写操作。
VGICv3 MMIO处理
vgicv3_redist_handler和vgicv3_dist_handler函数分别处理GICR和GICD的MMIO访问。vgicv3_redist_handler函数处理GICR的读写操作,检查是否访问的是当前zone的GICR,如果是,则允许访问;否则,忽略该访问。vgicv3_dist_handler函数根据不同的GICD寄存器类型,调用vgicv3_handle_irq_ops或restrict_bitmask_access函数,以适当地处理中断路由和配置寄存器的访问。
通过上述机制,hvisor能够有效地管理跨zone的中断,确保每个zone只能够访问和控制分配给它的中断资源,同时提供必要的隔离性。这使得在多zone环境中,VGICv3能够高效、安全地工作,支持复杂的虚拟化场景。
中断的来源
在 hvisor 中有三种中断类型:时钟中断,软件中断和外部中断。
时钟中断:当 time 寄存器变得大于 timecmp 寄存器时,产生一个时钟中断
软件中断: 在多核系统中,一个 hart 向另一个 hart 发送核间中断,通过SBI调用来实现
外部中断: 外部设备通过中断线将中断信号传给处理器
时钟中断
虚拟机需要触发时钟中断时,通过 ecall 指令陷入到 hvisor 中
#![allow(unused)] fn main() { ExceptionType::ECALL_VS => { trace!("ECALL_VS"); sbi_vs_handler(current_cpu); current_cpu.sepc += 4; } ... pub fn sbi_vs_handler(current_cpu: &mut ArchCpu) { let eid: usize = current_cpu.x[17]; let fid: usize = current_cpu.x[16]; let sbi_ret; match eid { ... SBI_EID::SET_TIMER => { sbi_ret = sbi_time_handler(fid, current_cpu); } ... } } }
如果没有开启 sstc 扩展,则需要通过 SBI 调用陷入到机器模式,设置 mtimecmp 寄存器,清零虚拟机的时钟中断挂起位,打开 hvisor 的时钟中断使能位;如果开启了 sstc 扩展,则可以直接设置 stimecmp 。
pub fn sbi_time_handler(fid: usize, current_cpu: &mut ArchCpu) -> SbiRet {
...
if current_cpu.sstc {
write_csr!(CSR_VSTIMECMP, stime);
} else {
set_timer(stime);
unsafe {
// clear guest timer interrupt pending
hvip::clear_vstip();
// enable timer interrupt
sie::set_stimer();
}
}
return sbi_ret;
}
当 time 寄存器变得大于 timecmp 寄存器时,产生一个时钟中断
中断触发后,保存陷入上下文,并分发到相对应的处理函数中
InterruptType::STI => {
unsafe {
hvip::set_vstip();
sie::clear_stimer();
}
}
将虚拟机的时钟中断挂起位置为1,即向虚拟机注入时钟中断,将hvisor的时钟中断使能位清零,完成中断处理
软件中断
虚拟机需要发送 IPI 时,通过 ecall 指令陷入到 hvisor 中
SBI_EID::SEND_IPI => {
...
sbi_ret = sbi_call_5(
eid,
fid,
current_cpu.x[10],
current_cpu.x[11],
current_cpu.x[12],
current_cpu.x[13],
current_cpu.x[14],
);
}
再通过 SBI 调用陷入到机器模式中向指定的 hart 发送 IPI ,设置 mip 寄存器的 SSIP 为1即可向hvisor注入核间中断
中断触发后,保存陷入上下文,并分发到相对应的处理函数中
pub fn handle_ssi(current_cpu: &mut ArchCpu) {
...
clear_csr!(CSR_SIP, 1 << 1);
set_csr!(CSR_HVIP, 1 << 2);
check_events();
}
将虚拟机的软件中断挂起位置为1,向虚拟机中注入软件中断。之后判断核间中断的类型,唤醒或阻塞cpu,或是处理 VIRTIO 的相关的中断请求
外部中断
PLIC
RISC-V 通过 PLIC 实现对外部中断处理,PLIC 不支持虚拟化,不支持 MSI
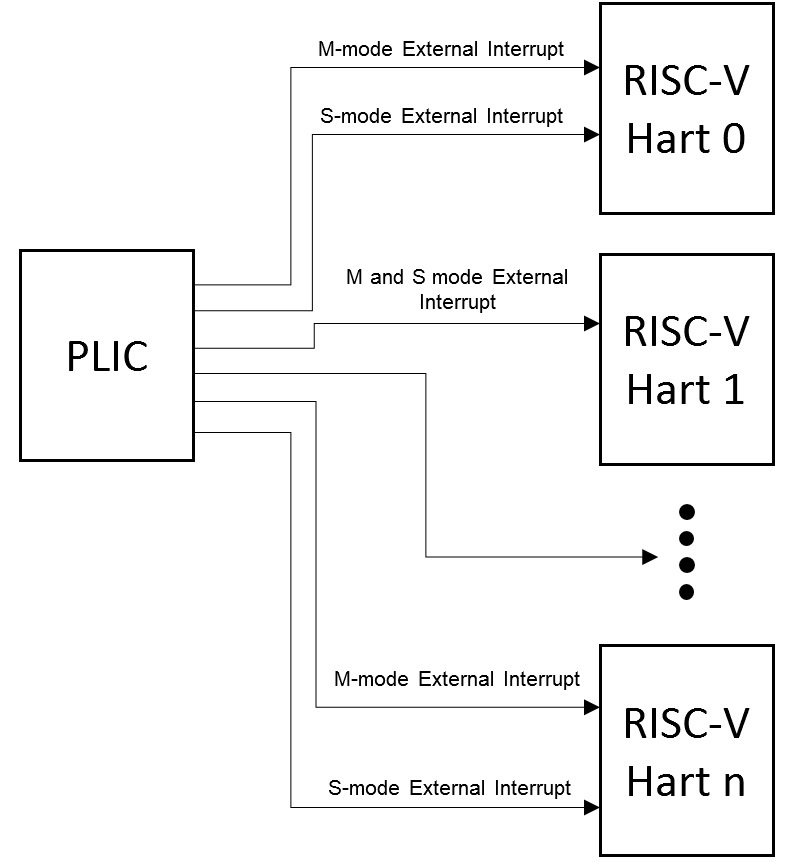
PLIC 架构框图
PLIC的中断流程示意图如下
中断源通过中断线向 PLIC 发送一个中断信号,只有当中断的优先级大于阈值的时候,才可以通过阈值寄存器的筛选。
之后读取 claim 寄存器得到 pending 的优先级最高的中断,之后清除对应的 pending 位。传给目标hart进行中断处理
处理完成后向 complete 寄存器写入中断号,可以接收下一个中断请求
初始化
初始化的过程与AIA类似
处理过程
虚拟机中的外部中断触发时,将访问 vPLIC 的地址空间,然而 PLIC 并不支持虚拟化,这个地址空间是未被映射的。因此会触发缺页异常,陷入到 hvisor 中来处理
异常触发后,保存陷入上下文,进入到缺页异常处理函数中
pub fn guest_page_fault_handler(current_cpu: &mut ArchCpu) {
...
if addr >= host_plic_base && addr < host_plic_base + PLIC_TOTAL_SIZE {
let mut inst: u32 = read_csr!(CSR_HTINST) as u32;
...
if let Some(inst) = inst {
if addr >= host_plic_base + PLIC_GLOBAL_SIZE {
vplic_hart_emul_handler(current_cpu, addr, inst);
} else {
vplic_global_emul_handler(current_cpu, addr, inst);
}
current_cpu.sepc += ins_size;
}
...
}
}
判断发生缺页异常的地址是否在 PLIC 的地址空间内,之后解析发生异常的指令,根据访问地址和访问指令,修改 PLIC 的地址空间来实现对于 vPLIC 的模拟配置
pub fn vplic_hart_emul_handler(current_cpu: &mut ArchCpu, addr: GuestPhysAddr, inst: Instruction) {
...
if offset >= PLIC_GLOBAL_SIZE && offset < PLIC_TOTAL_SIZE {
...
if index == 0 {
// threshold
match inst {
Instruction::Sw(i) => {
// guest write threshold register to plic core
let value = current_cpu.x[i.rs2() as usize] as u32;
host_plic.write().set_threshold(context, value);
}
_ => panic!("Unexpected instruction threshold {:?}", inst),
}
...
}
}
}
总体结构
AIA主要包括两个部分,消息中断控制器 IMSIC 和高级平台级中断控制器 APLIC ,总体结构如图所示
外设既可以选择发送消息中断,也可以选择通过线连接的方式发送有线中断。
如果外设 A 支持MSI,那么只需要向指定 hart 的中断文件写入指定的数据,之后 IMSIC 就会向目标处理器投送一个中断。
对于所有设备,都可以通过中断线与 APLIC 连接, APLIC 将会根据配置,选择中断投送模式为:
- 有线中断
- MSI
在hvisor中,中断的投送模式为 MSI
在hvisor中使用 IRQ=aia开启 AIA 规范后,时钟中断的处理仍然一致,软件中断和外部中断的处理有些变化
外部中断
IMSIC
hvisor中一个物理 CPU 对应一个虚拟 CPU ,它们都拥有自己的中断文件

向某个中断文件写入,即可触发指定 hart 指定特权级别的外部中断
为 IMSIC 提供二阶段地址映射表
let paddr = 0x2800_0000 as HostPhysAddr;
let size = PAGE_SIZE;
self.gpm.insert(MemoryRegion::new_with_offset_mapper(
paddr as GuestPhysAddr,
paddr + PAGE_SIZE * 1,
size,
MemFlags::READ | MemFlags::WRITE,
))?;
...
APLIC
结构
全局只有一个 APLIC
有线中断到来时,首先到达位于机器模式的根中断域(OpenSBI),之后中断路由到子中断域(hvisor),hvisor将中断信号按照 APLIC 配置好的 target 的寄存器,以 MSI 的方式发送给虚拟机对应的 CPU。
在 AIA 规范手册中指定了 APLIC 各个字段的字节偏移。定义 APLIC 结构体如下,通过以下方法实现对 APLIC 字段的读写
#[repr(C)]
pub struct Aplic {
pub base: usize,
pub size: usize,
}
impl Aplic {
pub fn new(base: usize, size: usize) -> Self {
Self {
base,
size,
}
}
pub fn read_domaincfg(&self) -> u32{
let addr = self.base + APLIC_DOMAINCFG_BASE;
unsafe { core::ptr::read_volatile(addr as *const u32) }
}
pub fn set_domaincfg(&self, bigendian: bool, msimode: bool, enabled: bool){
...
let addr = self.base + APLIC_DOMAINCFG_BASE;
let src = (enabled << 8) | (msimode << 2) | bigendian;
unsafe {
core::ptr::write_volatile(addr as *mut u32, src);
}
}
...
}
初始化
根据设备树中的基地址和大小初始化 APLIC
pub fn primary_init_early(host_fdt: &Fdt) {
let aplic_info = host_fdt.find_node("/soc/aplic").unwrap();
init_aplic(
aplic_info.reg().unwrap().next().unwrap().starting_address as usize,
aplic_info.reg().unwrap().next().unwrap().size.unwrap(),
);
}
pub fn init_aplic(aplic_base: usize, aplic_size: usize) {
let aplic = Aplic::new(aplic_base, aplic_size);
APLIC.call_once(|| RwLock::new(aplic));
}
pub static APLIC: Once<RwLock<Aplic>> = Once::new();
pub fn host_aplic<'a>() -> &'a RwLock<Aplic> {
APLIC.get().expect("Uninitialized hypervisor aplic!")
}
APLIC全局只有一个,因此加锁避免读写冲突,使用 host_aplic() 方法进行访问
虚拟机启动时,将访问 APLIC 的地址空间进行初始化配置,这个地址空间是未被映射的。因此会触发缺页异常,陷入到 hvisor 中来处理
pub fn guest_page_fault_handler(current_cpu: &mut ArchCpu) {
...
if addr >= host_aplic_base && addr < host_aplic_base + host_aplic_size {
let mut inst: u32 = read_csr!(CSR_HTINST) as u32;
...
if let Some(inst) = inst {
vaplic_emul_handler(current_cpu, addr, inst);
current_cpu.sepc += ins_size;
}
...
}
}
判断访问的地址空间属于 APLIC 的范围,解析访问指令,进入 vaplic_emul_handler 实现对虚拟机中 APLIC 的模拟
pub fn vaplic_emul_handler(
current_cpu: &mut ArchCpu,
addr: GuestPhysAddr,
inst: Instruction,
) {
let host_aplic = host_aplic();
let offset = addr.wrapping_sub(host_aplic.read().base);
if offset >= APLIC_DOMAINCFG_BASE && offset < APLIC_SOURCECFG_BASE {
match inst {
Instruction::Sw(i) => {
...
host_aplic.write().set_domaincfg(bigendian, msimode, enabled);
}
Instruction::Lw(i) => {
let value = host_aplic.read().read_domaincfg();
current_cpu.x[i.rd() as usize] = value as usize;
}
_ => panic!("Unexpected instruction {:?}", inst),
}
}
...
}
中断过程
hvisor 通过缺页异常的方式完成对虚拟机模拟 APLIC 初始化后,进入到虚拟机中,以键盘按下产生的中断为例:中断信号首先来到 OpenSBI ,之后中断路由至 hvisor ,根据target寄存器的配置,向虚拟中断文件写入触发虚拟机的外部中断。
软件中断
开启 AIA 规范后,虚拟机的 linux 内核会通过 msi 的方式来发送 IPI,不需要再使用 ecall 指令陷入到 hvisor 中
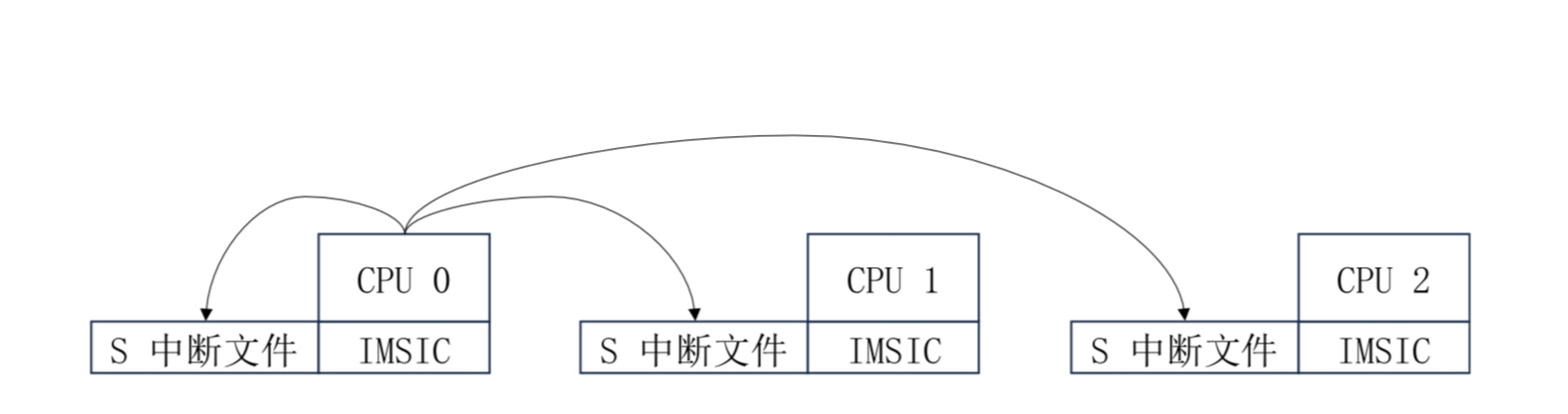
如图所示,在hvisor中,向指定hart的中断文件写入,即可触发 IPI。
在虚拟机中,只需要向指定的虚拟中断文件写入,即可实现虚拟机中的 IPI,无需hvisor的模拟支持。
LoongArch 中断控制
由于龙芯不同处理器/开发板的中断控制器各自设计不同(嵌入式处理器如2K1000有自己的中断控制器设计,3系处理器则有7A1000和7A2000桥片负责外部中断控制),本文IO中断部分主要对最新的龙芯7A2000桥片内的中断控制器进行介绍[1]。
CPU中断
LoongArch的中断配置由CSR.ECFG控制,龙芯架构下的中断采用线中断的形式,每个处理器核内部可以记录 13 个线中断。这些中断包括:1 个核间中断(IPI),1 个定时器中断(TI),1 个性能监测计数溢出中断(PMI),8 个硬中断(HWI0~HWI7),以及 2 个软中断(SWI0~SWI1)。所有线中断均为电平中断,并且都是高电平有效[3]。
- 核间中断:来自核外的中断控制器,被记录在
CSR.ESTAT.IS[12]位。 - 定时器中断:源自核内的恒定频率定时器,当计时至全 0 值时触发,并被记录在
CSR.ESTAT.IS[11]位。清除方法是通过软件向CSR.TICLR寄存器的TI位写 1。 - 性能计数器溢出中断:源自核内的性能计数器,当任一开启中断使能的性能计数器的第 63 位为 1 时触发,并记录在
CSR.ESTAT.IS[10]位。清除方法是将引起中断的性能计数器的第 63 位清 0 或关闭该性能计数器的中断使能。 - 硬中断:来自处理器核外部的中断控制器,8 个硬中断
HWI[7:0]被记录在CSR.ESTAT.IS[9:2]位。 - 软中断:来自处理器核内部,通过软件指令对
CSR.ESTAT.IS[1:0]写 1 置起,写 0 清除。
中断在 CSR.ESTAT.IS 域中记录的位置的索引值也被称为中断号(Int Number)。例如,SWI0 的中断号为 0,SWI1 的中断号为 1,依此类推,IPI 的中断号为 12。
传统IO中断
上图是3A系列处理器+7A系列桥片的中断系统示意图。图中表示了两种中断方式的过程,上部表示的是通过中断线INTn0来中断,下部表示的是通过HT消息包来中断。
设备(除了工作在MSI模式的PCIe设备)发出的中断intX送给7A内部中断控制器,经过中断路由后送到桥片引脚或者转换成HT消息包发给3A的HT控制器,3A的中断控制器通过外部中断引脚或者HT控制器中断接收到该中断,并经过中断路由中断某个处理器核[1]。
龙芯3A5000芯片的传统 IO 中断支持32个中断源,以统一方式进行管理,如下图所示。 任意一个IO中断源可以被配置为是否使能、触发的方式、以及被路由的目标处理器核中断脚。传统中断不支持中断的跨片分发,只能中断同一个处理器片内的处理器核[2]。
拓展IO中断
除了兼容原有的传统 IO 中断方式,3A5000 开始支持扩展 I/O 中断,用于将 HT 总线上的 256 位中断直接分发给各个处理器核,而不再通过 HT 的中断线进行转发,提升 IO 中断使用的灵活性[2]。
参考资料
[1] 龙芯中科技术股份有限公司.龙芯7A2000桥片用户手册.V1.0.第5章.
[2] 龙芯中科技术股份有限公司.龙芯3A5000/3B5000处理器寄存器使用手册-多核处理器架构、寄存器描述与系统软件编程指南.V1.3.第11章.
[3] 龙芯中科技术股份有限公司.龙芯架构参考手册.卷一:基础架构.
X86_64 架构下的中断虚拟化
X86_64 中断处理
中断(interrupt)是硬件或软件向 CPU 发出的一种异步信号。CPU 在收到中断后,会暂停当前运行的程序,保存上下文,转而执行中断处理程序。执行完毕后,继续运行原先的程序。中断分为硬件中断与软件中断,硬件中断由外部设备产生,软件中断则来自软件程序中的特定的指令。
x86 架构使用中断描述符表(interrupt descriptor table,IDT)记录所有中断处理程序的位置。每个中断处理程序在 IDT 中具有唯一索引,被称为向量号(vector)。IDT 支持的 vector 范围为 0-255,其中 0-31 号由架构预留,用于架构定义的异常和中断;32-255 号由用户自行使用,它们通常被分配给外部设备。
在中断机制发展的早期,外部设备需要与 CPU 的 INTR 引脚连通才能发送中断请求(interrupt request,IRQ)。然而 INTR 引脚在数量上受到限制,无法直接与大量设备相连。此时就需要中断控制器(interrupt controller)作为代理,在设备与 CPU 之间进行中断的传递。设备所使用的 IRQ 号与中断处理程序所使用的 vector 并不等价,因此中断控制器的作用之一就是将中断信号从 IRQ 号翻译为 vector。
x86 最早的中断控制器名为可编程中断控制器(programmable interrupt controller,PIC),单个 PIC 可支持 8 个 IRQ,通过级联的方式能扩展 IRQ 的数量。然而,PIC 只能往一个 CPU 发送中断,不能满足如今多核系统的需求。后来,高级可编程中断控制器(advanced programmable interrupt controller,APIC)出现并逐渐取代 PIC。APIC 由 Local APIC(LAPIC)和 I/O APIC 两部分组成。每个 CPU 有属于自己的 LAPIC,可以通过 APIC ID 对其进行区分。LAPIC 彼此之间通过 APIC 总线相连,可以互相发送核间中断(inter-process interrupt,IPI)。I/O APIC 负责接收设备的 IRQ,使用可配置的中断重定向表(redirection table)将 IRQ 翻译成 vector 后,沿 APIC 总线向 LAPIC 发送中断信号,最后再由 LAPIC 转发给 CPU。典型的 I/O APIC 支持 23 个 IRQ:IRQ 0-15 用于兼容 PIC 时代的 ISA 设备,IRQ 16-23 由 PCI 设备使用中断路由表进行共享。
PCIe 总线的出现引入了一种全新的中断传递机制:消息信号中断(message signaled interrupts,MSI)及其扩展版本 MSI-X。与传统中断方式不同,MSI/MSI-X 通过向 LAPIC 的 MMIO 区域指定位置写入特定数据即可触发中断,无需额外的中断引脚 INTR。这种机制允许通过 PCI 配置空间设置中断对应的 vector 和目标 LAPIC 的 APIC ID,实现更灵活的中断管理。在 Linux 的默认配置中,系统优先采用 MSI 或 MSI-X;对于不支持该机制的旧设备,则仍然依赖 I/O APIC 进行中断传递。
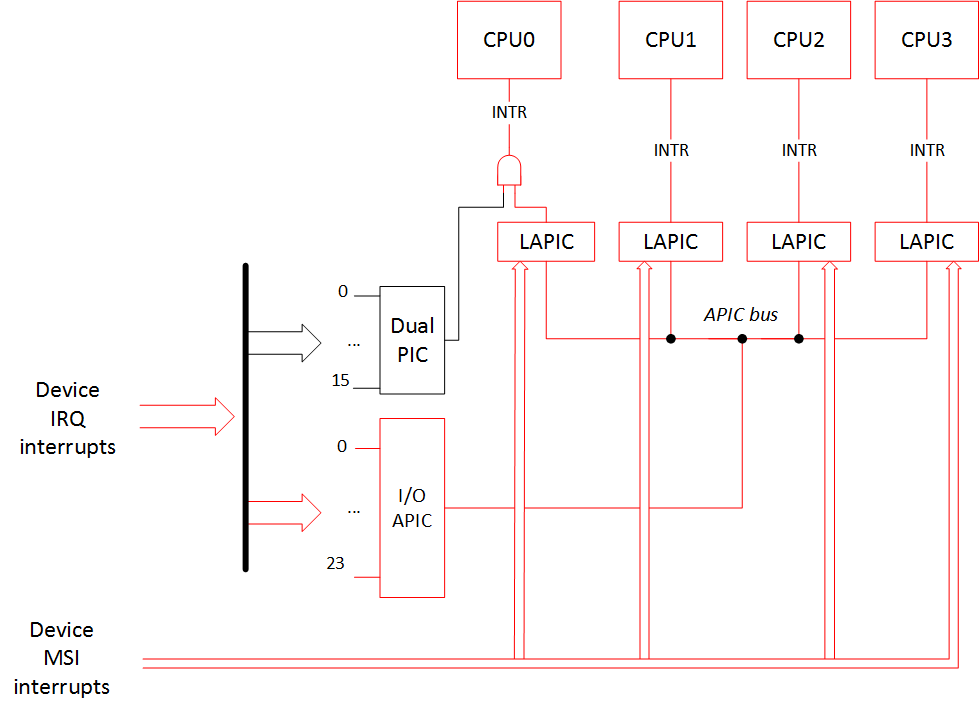
中断虚拟化
中断是一种由外部设备发起,用于异步通知 CPU 的事件机制。在非虚拟化环境中,当设备触发中断,CPU 会捕获该中断,并直接跳转至操作系统内核中预设的中断处理程序。而在虚拟化环境下,中断被划分为两种类型:一类是由物理设备产生的物理中断(pIRQ),另一类是 hypervisor 转发给 guest OS 的虚拟中断(vIRQ)。为了避免 guest OS 与 hypervisor 在 vector 使用上的冲突,pIRQ 通常由 hypervisor 统一接收和管理,而不会直接传递给 guest OS。hypervisor 在接收到 pIRQ 后,会利用硬件提供的中断虚拟化机制,将其转换为相应的 vIRQ 并传递至 guest OS。
Intel VT-x 提供了两种向 guest OS 传递中断的方法。第一种方法基于中断注入(interrupt injection)机制,虽然实现较为简单,但每次 pIRQ 到达时都需要触发一次 VM exit,由 hypervisor 负责将 pIRQ 转换为 vIRQ 并完成注入,因此在性能上存在一定开销;第二种方法则依赖包括 vAPIC page、VT-d 中断重映射、posted interrupt 在内的多种硬件机制协同配合,通过对硬件进行相应配置,实现 pIRQ 到 vIRQ 的自动转换与注入,几乎无需 hypervisor 干预,因而拥有更高的运行效率。然而,该方法要求宿主机的 CPU 支持相关扩展功能,且实现复杂度较高。
Hvisor 的中断虚拟化实现
在 Hvisor 中,对于中断虚拟化的支持由硬件机制与软件实现协同配合、共同完成。其中硬件机制包括 VT-x 提供的中断注入机制,而软件层面的实现包括虚拟 LAPIC 以及虚拟 I/O APIC 等。
中断注入
Intel VT-x 提供了对注入虚拟中断的支持。为了使用该功能,Hvisor 在配置 VMCS 时需要设置 VM-execution control fields 中 pin-based VM-execution controls 字段的 external-interrupt exiting 位。当物理中断到达 pCPU 时,就会触发名为 external interrupt 的 VM exit。此外,还需在 VM-exit control fields 中设置 VM-exit controls 字段的 acknowledge interrupt on exit 位。使得每次物理中断触发 VM exit 时,相关中断信息会被保存到 VM-exit information fields 的 VM-exit interruption information 字段中。这些信息包括该中断的向量号(vector)、中断类型、错误码等,Hvisor 据此判断应将中断注入至哪个 zone,并将 vector 压入当前 vCPU 的 pending_vectors 队列中。
在每次即将 VM entry 前,Hvisor 都会调用 check_pending_vectors() 对 pending_vectors 队列进行检查。首先判断是否存在待注入的 vector。如果有,检查当前 vCPU 是否处于允许中断注入的状态。具体而言,需要 VMCS guest RFLAGS 字段的中断标志位 IF 为 1,且 interruptibility state 字段为 0,表明 vCPU 已开启中断且并未被其他中断阻塞。如果这些条件满足,就可以将 pending_vectors 队首的 vector 弹出,并写入 VM-entry control fields 的 VM-entry interruption-information field 字段,完成中断注入;反之,若当前无法注入中断,Hvisor 会利用 Intel VT-x 提供的中断窗口退出机制,即对 VMCS primary controls 字段中的 interrupt-window exiting 位进行设置。当 vCPU 返回非根模式后,只要一打开中断,就会立即触发名为 interrupt window 的 VM exit,Hvisor 便能在此时完成中断注入。这一机制能够确保中断在 vCPU 恢复响应能力时能够被及时注入。
虚拟 LAPIC
虽然 Hvisor 采用了 pCPU 与 vCPU 一一对应的设计,理论上可以让 zone 直通使用 LAPIC,但是这种做法在某些情况下会出问题,仍需对 LAPIC 的一部分寄存器进行拦截处理。
Hvisor 和 zone 目前藉由 x2APIC 模式访问 LAPIC 的寄存器,即以读写 MSR 寄存器的方式。而拦截特定 MSR 寄存器访问操作需通过 MSR bitmap 实现。MSR bitmap 占据 4KB 的内存,每一位代表一个 MSR 寄存器。在配置 VMCS 的 VM-execution control fields 时,设置 primary controls 的 use MSR bitmaps 位,然后将 MSR-bitmap address 字段设置为 MSR bitmap 的 hPA 即可。以下是主要的需要拦截的 LAPIC 寄存器:
End-of-Interrupt register:当 zone 执行完一个中断的处理程序后,会往该寄存器中写一个0,以此告知 LAPIC 中断已经处理完成。往真实的 LAPIC 中写EOI寄存器的任务已经由 Hvisor 负责,如果 zone 也往其中写就会产生重复,可能会带来副作用,因此需要拦截。Interrupt Command register:zone 通过该寄存器向其他 vCPU 发送 IPI。在大多数情况下,直接用真实的ICR发送 IPI 并不会产生问题。但在 zone 的多核启动流程中,作为 BSP 的 vCPU(以下简称 vBSP)会向同一 zone 的其余 vCPU 发送INIT和Start-up类型的 IPI,而这两类信号只对 pCPU 的启动有效。若要实现 vCPU 的启动,还需 Hvisor 在软件层面的介入:Hvisor 首先对 vBSP 发送启动信号的操作进行拦截,随后向目标 vCPU 发送 IPI 中断,目标 vCPU 收到中断后进入对应的 IPI 处理程序,并最终进入 zone 中。
虚拟 I/O APIC
在 Hvisor 的实现中,zone0 需要通过 I/O APIC 接收来自 UART 串口设备的中断。而对于 zoneU 而言,由于 Hvisor 所使用的 virtio-mmio 并非 PCI 设备,无法直接向 LAPIC 发送 MSI 中断,同样也依赖 I/O APIC 进行中断传递。因此,Hvisor 需为每个 zone 分别实现独立的虚拟 I/O APIC,以支持各自的中断管理需求。
实现虚拟 I/O APIC 的主要环节在于为每个 zone 维护独立的重定向表 rt,记录 IRQ 到 vector 的映射关系。zoneU 的 I/O APIC 仅用于记录 virtio 设备所使用的 vector,以便 Hvisor 进行中断注入。只有 zone0 的 I/O APIC 与真实外部设备相连,因此可以直接将 zone0 所使用的 rt 作为物理 I/O APIC 的中断重定向表。
ARM-SMMU技术文档
摘要:介绍ARM-SMMU的开发过程。
背景知识
简单介绍SMMMU的原理与作用。
DMA是什么?为什么需要IOMMU?
运行在hvisor之上的虚拟机,需要和设备进行交互,但如果每次都等待CPU来主持这类工作,会使处理效率降低,那么就出现了DMA机制。DMA 是一种允许设备直接与内存交换数据而不需要 CPU 参与的机制。
那么我们可以大致得出虚拟机通过DMA和设备交互的过程,首先虚拟机发出DMA请求,告诉目标设备把数据写到哪个地方,然后设备根据地址写入内存。
但上述过程需要考虑一些问题:
- hvisor对每个虚拟机都做了内存虚拟化,所以虚拟机发出的DMA请求的目标内存地址是GPA,在这里也叫IOVA,需要将这个地址转为真正的PA,才能写入到物理内存的正确位置。
- 再者,如果不对IOVA的范围加以限制,那么代表着可以通过DMA机制访问任何一个内存地址,从而造成无法预见的严重后果。
所以我们需要一个既能帮我们做地址转换,又能保证操作地址的合法性的机构,就像MMU内存管理单元一样,这个机构就叫IOMMU,在Arm架构中它有另一个名字叫SMMU(后续都称SMMU)。
现在你知道了,SMMU可以将虚拟地址转为物理地址,从而保证设备直接访问内存的合法性。
SMMU具体要做的工作
上面说到SMMU的功能类似MMU,MMU的作用对象是虚拟机或者应用程序,而SMMU的作用对象是每个设备,每个设备以sid作为标识,对应的表叫做stream table。该表以设备的sid作为索引,PCI设备的sid可以从BDF号获取:sid = (B << 5) | (D << 3) | F。
开发工作
目前我们在Qemu中实现了对SMMUv3的stage-2地址转换支持,创建简单的线性表,并且使用PCI设备进行了简单的验证。
IOMMU的工作还未并入主线,可以切换到IOMMU分支查看。
整体思路
我们将PCI HOST直通给zone0,即在提供给zone0的设备树中加上PCI节点,将对应的内存地址在zone0的第二阶段页表中做好映射,并确保中断注入正常。那么zone0就会自己去探测PCI设备并进行配置,而我们在hvisor中只需要做好SMMU的配置工作就好。
Qemu参数
在 machine 中添加 iommu=smmuv3 以开启SMMUv3支持,并在 global 中添加 arm-smmuv3.stage=2 开启第二阶段地址翻译。
注意在Qemu中尚不支持嵌套翻译,如果不指出 stage=2 ,则默认只支持第一阶段地址翻译,请使用Qemu-8.1以上版本,低版本中不支持开启第二阶段地址翻译。
添加PCI设备时请注意开启 iommu_platform=on 。
addr可以指定该设备的bdf号。
在Qemu模拟的PCI总线中,除了PCI HOST,还有一个默认的网卡设备,所以其余添加的设备的addr参数必须从2.0开始。
// scripts/qemu-aarch64.mk
QEMU_ARGS := -machine virt,secure=on,gic-version=3,virtualization=on,iommu=smmuv3
QEMU_ARGS += -global arm-smmuv3.stage=2
QEMU_ARGS += -device virtio-blk-pci,drive=Xa003e000,disable-legacy=on,disable-modern=off,iommu_platform=on,addr=2.0
在hvisor的页表中映射SMMU相关的内存
查阅Qemu的源码可知VIRT_SMMU对应的内存区域起始地址为0x09050000,大小为0x20000,我们需要访问这个区域,所以在hvisor的页表中必须进行映射。
#![allow(unused)] fn main() { // src/arch/aarch64/mm.rs pub fn init_hv_page_table(fdt: &fdt::Fdt) -> HvResult { hv_pt.insert(MemoryRegion::new_with_offset_mapper( smmuv3_base(), smmuv3_base(), smmuv3_size(), MemFlags::READ | MemFlags::WRITE, ))?; } }
SMMUv3数据结构
该结构包含了将会访问的SMMUv3的内存区域的引用,是否支持二级表,sid的最大位数,以及stream table的基地址和分配的页帧。
其中的rp是所定义的 RegisterPage 的引用,RegisterPage 根据SMMUv3手册中第六章的偏移量进行设置,读者可自行查阅。
#![allow(unused)] fn main() { // src/arch/aarch64/iommu.rs pub struct Smmuv3{ rp:&'static RegisterPage, strtab_2lvl:bool, sid_max_bits:usize, frames:Vec<Frame>, // strtab strtab_base:usize, // about queues... } }
new()
在完成映射工作后,我们便可以引用对应的这段寄存器区域。
#![allow(unused)] fn main() { impl Smmuv3{ fn new() -> Self{ let rp = unsafe { &*(SMMU_BASE_ADDR as *const RegisterPage) }; let mut r = Self{ ... }; r.check_env(); r.init_structures(); r.device_reset(); r } } }
check_env()
检查当前环境支持哪个阶段的地址转换、支持什么类型的流表、支持多少位的sid等信息。
以其中检查环境支持哪种表格式为例,支持的表的类型在 IDR0 寄存器中,通过 self.rp.IDR0.get() as usize 获取 IDR0 的数值,通过 extract_bit 进行截取,获取 ST_LEVEL 字段的值,根据手册可知,0b00代表支持线性表,0b01代表支持线性表和二级表,0b1x为保留位,我们可以根据该信息选择创建什么类型的流表。
#![allow(unused)] fn main() { impl Smmuv3{ fn check_env(&mut self){ let idr0 = self.rp.IDR0.get() as usize; info!("Smmuv3 IDR0:{:b}",idr0); // supported types of stream tables. let stb_support = extract_bits(idr0, IDR0_ST_LEVEL_OFF, IDR0_ST_LEVEL_LEN); match stb_support{ 0 => info!("Smmuv3 Linear Stream Table Supported."), 1 => {info!("Smmuv3 2-level Stream Table Supoorted."); self.strtab_2lvl = true; } _ => info!("Smmuv3 don't support any stream table."), } ... } } }
init_linear_strtab()
我们需要支持第二阶段地址转换,且系统中的设备并不多,所以我们选择用线性表。
在申请线性表需要的空间时,我们应该根据当前的sid的最多位数得到表项的个数,乘上每个表项需要的空间 STRTAB_STE_SIZE ,进而知道需要申请多少个页帧。但SMMUv3对stream table的起始地址有着严格的要求,起始地址的低 (5+sid_max_bits) 位必须为0。
由于当前的hvisor中暂不支持这样申请空间,我们在确保安全的情况下,申请一段空间,并在这段空间里面选定一个符合条件的地址作为表基址,虽然这样会造成一些空间的浪费。
申请了空间后,我们可以将这个表的基地址填入 STRTAB_BASE 这个寄存器:
#![allow(unused)] fn main() { let mut base = extract_bits(self.strtab_base, STRTAB_BASE_OFF, STRTAB_BASE_LEN); base = base << STRTAB_BASE_OFF; base |= STRTAB_BASE_RA; self.rp.STRTAB_BASE.set(base as _); }
接着我们还要设置 STRTAB_BASE_CFG 寄存器,来表明我们使用的表的格式是线性表或者二级表,以及表项的个数(使用以LOG2的形式表示,即SID的最大位数):
#![allow(unused)] fn main() { // format : linear table cfg |= STRTAB_BASE_CFG_FMT_LINEAR << STRTAB_BASE_CFG_FMT_OFF; // table size : log2(entries) // entry_num = 2^(sid_bits) // log2(size) = sid_bits cfg |= self.sid_max_bits << STRTAB_BASE_CFG_LOG2SIZE_OFF; // linear table -> ignore SPLIT field self.rp.STRTAB_BASE_CFG.set(cfg as _); }
init_bypass_ste(sid:usize)
当前我们还未配置任何相关信息,需要先将所有表项置为默认状态。
对于每个sid,根据表基址找到表项的地址,即合法位为0,地址翻译设置为 BYPASS。
#![allow(unused)] fn main() { let base = self.strtab_base + sid * STRTAB_STE_SIZE; let tab = unsafe{&mut *(base as *mut [u64;STRTAB_STE_DWORDS])}; let mut val:usize = 0; val |= STRTAB_STE_0_V; val |= STRTAB_STE_0_CFG_BYPASS << STRTAB_STE_0_CFG_OFF; }
device_reset()
上面我们做了一些准备工作,但还需要一些额外的配置,比如使能SMMU,否则会导致SMMU处于disabled状态。
#![allow(unused)] fn main() { let cr0 = CR0_SMMUEN; self.rp.CR0.set(cr0 as _); }
write_ste(sid:usize,vmid:usize,root_pt:usize)
该方法用于配置具体设备的信息。
首先我们同样要根据sid找到对应的表项地址。
#![allow(unused)] fn main() { let base = self.strtab_base + sid * STRTAB_STE_SIZE; let tab = unsafe{&mut *(base as *mut [u64;STRTAB_STE_DWORDS])}; }
第二步我们要指明,这个设备的相关信息,我们是要用来进行第二阶段地址翻译的,且这个表项是合法的了。
#![allow(unused)] fn main() { let mut val0:usize = 0; val0 |= STRTAB_STE_0_V; val0 |= STRTAB_STE_0_CFG_S2_TRANS << STRTAB_STE_0_CFG_OFF; }
第三步我们要说明当前这个设备分配给哪个虚拟机来用,并且开启第二阶段页表遍历,S2AA64 代表第二阶段翻译表是基于aarch64的,S2R 代表启用错误记录。
#![allow(unused)] fn main() { let mut val2:usize = 0; val2 |= vmid << STRTAB_STE_2_S2VMID_OFF; val2 |= STRTAB_STE_2_S2PTW; val2 |= STRTAB_STE_2_S2AA64; val2 |= STRTAB_STE_2_S2R; }
最后一步就是要指出第二阶段翻译的依据,就是在hvisor中的对应虚拟机的页表,只需要将页表基地址填入对应位置即可,即 S2TTB 这个字段。
这里我们也需要说明这个页表的配置信息,这样SMMU才知道这个页表的格式等信息,才能使用这个页表,即 VTCR 这个字段。
#![allow(unused)] fn main() { let vtcr = 20 + (2<<6) + (1<<8) + (1<<10) + (3<<12) + (0<<14) + (4<<16); let v = extract_bits(vtcr as _, 0, STRTAB_STE_2_VTCR_LEN); val2 |= v << STRTAB_STE_2_VTCR_OFF; let vttbr = extract_bits(root_pt, STRTAB_STE_3_S2TTB_OFF, STRTAB_STE_3_S2TTB_LEN); }
初始化以及设备分配
在 src/main.rs 中,进行了hvisor的页表初始化以后(映射了SMMU相关区域),可以进行SMMU的初始化。
#![allow(unused)] fn main() { fn primary_init_early(dtb: usize) { ... crate::arch::mm::init_hv_page_table(&host_fdt).unwrap(); info!("Primary CPU init hv page table OK."); iommu_init(); zone_create(0,ROOT_ENTRY,ROOT_ZONE_DTB_ADDR as _, DTB_IPA).unwrap(); INIT_EARLY_OK.store(1, Ordering::Release); } }
接着需要分配设备,这一步我们在创建虚拟机的时候同步完成,目前我们只将设备分配给zone0使用。
#![allow(unused)] fn main() { // src/zone.rs pub fn zone_create( zone_id: usize, guest_entry: usize, dtb_ptr: *const u8, dtb_ipa: usize, ) -> HvResult<Arc<RwLock<Zone>>> { ... if zone_id==0{ // add_device(0, 0x8, zone.gpm.root_paddr()); iommu_add_device(zone_id, BLK_PCI_ID, zone.gpm.root_paddr()); } ... } }
简单验证
在qemu启动参数中开启 -trace smmuv3_* ,即可看到相关输出:
smmuv3_config_cache_hit Config cache HIT for sid=0x10 (hits=1469, misses=1, hit rate=99)
smmuv3_translate_success smmuv3-iommu-memory-region-16-2 sid=0x10 iova=0x8e043242 translated=0x8e043242 perm=0x3
注意事项
在QEMU模拟的aarch64机器中,默认存在 virtio-net-pci 设备,但你必须手动添加参数,使其经过IOMMU,就像下面这样:
QEMU_ARGS += -netdev type=user,id=net1
QEMU_ARGS += -device virtio-net-pci,netdev=net1,disable-legacy=on,disable-modern=off,iommu_platform=on
当然你也可以在GPA和HPA非恒等映射的情况下,测试IOMMU是否能够正常工作。但你需要把root根文件系统挂载的 virtio-blk-device 换为 virtio-blk-pci,因为普通的MMIO设备在QEMU中不经过IOMMU,这会导致DMA失败,进而导致root虚拟机无法启动。
一个参考的设置方式如下:
QEMU_ARGS += -drive if=none,file=$(FSIMG1),id=Xa003e000,format=raw
# QEMU_ARGS += -device virtio-blk-device,drive=Xa003e000,bus=virtio-mmio-bus.31
QEMU_ARGS +=-device virtio-blk-pci,drive=Xa003e000,disable-legacy=on,disable-modern=off,iommu_platform=on
RISC-V IOMMU 标准的实现
RISC-V IOMMU 工作流程
对于具有 DMA 设备的虚拟化系统来说,该系统有可能因为虚拟机配置 DMA 设备进行恶意的 DMA 从而破坏整个系统的稳定性,而 IOMMU 的引入可以进一步提高 Zone 间的隔离性,以保证系统的安全性。
IOMMU 支持两阶段地址翻译,提供了 DMA 重映射的功能,一方面可以对 DMA 操作进行内存保护,限制设备能够访问的物理内存区域,使得 DMA 操作更加安全,另一方面,设备的 DMA 操作只需要连续的 IOVA 即可,而无需连续的 PA,这样可以充分利用物理内存中分散的页。
为了执行地址转换和内存保护,RISC-V IOMMU 在第一阶段和第二阶段使用与 CPU 的 MMU 相同的页表格式。使用与 CPU MMU 相同的页表格式,可以消除 DMA 在内存管理方面的一些复杂性,并且使用相同的格式还允许 CPU MMU 和 IOMMU 使用相同的页表。
在 hvisor 中支持了 IOMMU 的第二阶段地址翻译过程,即设备端 IOVA(GPA)到 HPA 的翻译,并且在 CPU MMU 和 IOMMU 之间共享了第二阶段页表,功能示意如下所示:
IOMMU 在翻译前需要先根据设备标识符(device_id)在设备目录表中找到设备上下文(DC)。每个设备有唯一的 device_id,对于平台设备,device_id 在硬件实现时指定,对于 PCI/PCIe 设备,则将 PCI/PCIe 设备的 BDF 编号作为 device_id。DC 中包含了两阶段地址翻译的页表基地址等信息,以及一些翻译的控制信息。以两阶段地址翻译为例,I/O 设备的 IOVA 首先在 fsc 字段指向的 Stage-1 页表中翻译成 GPA,然后再在 iohgatp 字段指向的Stage-2 页表中翻译成 HPA,并以此访问内存。在 hvisor 中支持第二阶段翻译,即仅使用 iohgatp 字段进行地址翻译,如下图所示:
RISC-V IOMMU 作为一个物理硬件,可以使用 MMIO 方式进行访问,并且在 IOMMU 规范手册中指定了其各个字段的字节偏移,实现时需要能够按照规范指定的偏移和大小进行访问,才能正确获取各个字段的值。定义 IommuHw 结构体,其和物理 RISC-V IOMMU 对应,用以简化访问物理 IOMMU,定义如下:
#![allow(unused)] fn main() { #[repr(C)] #[repr(align(0x1000))] pub struct IommuHw { caps: u64, fctl: u32, __custom1: [u8; 4], ddtp: u64, cqb: u64, cqh: u32, cqt: u32, fqb: u64, fqh: u32, fqt: u32, pqb: u64, pqh: u32, pqt: u32, cqcsr: u32, fqcsr: u32, pqcsr: u32, ipsr: u32, iocntovf: u32, iocntinh: u32, iohpmcycles: u64, iohpmctr: [u64; 31], iohpmevt: [u64; 31], tr_req_iova: u64, tr_req_ctl: u64, tr_response: u64, __rsv1: [u8; 64], __custom2: [u8; 72], icvec: u64, msi_cfg_tbl: [MsiCfgTbl; 16], __rsv2: [u8;3072], } }
IOMMU 的 Capabilities 是一个只读寄存器,其报告了 IOMMU 支持的功能,在初始化 IOMMU 时,需要首先查看该寄存器,以确定硬件能够支持 IOMMU 功能。
IOMMU 在初始化时要先检查当前 IOMMU 是否和驱动匹配,实现时定义了 rv_iommu_check_features,检查对 Sv39x4、WSI 等的硬件支持情况,实现如下:
#![allow(unused)] fn main() { impl IommuHw { pub fn rv_iommu_check_features(&self){ let caps = self.caps as usize; let version = caps & RV_IOMMU_CAPS_VERSION_MASK; // get version, version 1.0 -> 0x10 if version != RV_IOMMU_SUPPORTED_VERSION{ error!("RISC-V IOMMU unsupported version: {}", version); } // support SV39x4 if caps & RV_IOMMU_CAPS_SV39X4_BIT == 0 { error!("RISC-V IOMMU HW does not support Sv39x4"); } if caps & RV_IOMMU_CAPS_MSI_FLAT_BIT == 0 { error!("RISC-V IOMMU HW does not support MSI Address Translation (basic-translate mode)"); } if caps & RV_IOMMU_CAPS_IGS_MASK == 0 { error!("RISC-V IOMMU HW does not support WSI generation"); } if caps & RV_IOMMU_CAPS_AMO_HWAD_BIT == 0 { error!("RISC-V IOMMU HW AMO HWAD unsupport"); } } } }
IOMMU 的 fctl 为功能控制寄存器,它提供了 IOMMU 的一些功能控制,包括 IOMMU 对内存数据访问是大端还是小端,IOMMU 产生的中断为 WSI 中断还是 MSI 中断以及对 Guest 地址转换方案的控制。
IOMMU 的 ddtp 为设备目录表指针寄存器,该寄存器包含了设备目录表的根页面的 PPN,以及 IOMMU Mode,其可以配置为 Off、Bare、1LVL、2LVL 或 3LVL,其中 Off 表示 IOMMU 不允许设备访问内存,Bare 表示 IOMMU 允许设备所有的内存访问,不进行翻译与保护,1LVL、2LVL、3LVL 表示了 IOMMU 采用的设备目录表的级数。
实现时定义了 rv_iommu_init 函数,用于对物理 IOMMU 的功能检查和控制,例如配置中断为 WSI、配置设备目录表等,具体实现如下:
#![allow(unused)] fn main() { impl IommuHw { pub fn rv_iommu_init(&mut self, ddt_addr: usize){ // Read and check caps self.rv_iommu_check_features(); // Set fctl.WSI We will be first using WSI as IOMMU interrupt mechanism self.fctl = RV_IOMMU_FCTL_DEFAULT; // Clear all IP flags (ipsr) self.ipsr = RV_IOMMU_IPSR_CLEAR; // Configure ddtp with DDT base address and IOMMU mode self.ddtp = IOMMU_MODE as u64 | ((ddt_addr >> 2) & RV_IOMMU_DDTP_PPN_MASK) as u64; } } }
设备目录表中的表项格式在规范手册中给出,为了能够让硬件工作,需要结合规范进行实现,在实现时定义了 DdtEntry 结构体,表示设备目录表中的一个表项,代表一个DMA设备。其中 iohgatp 保存了第二阶段页表的 PPN、Guest 软件上下文 ID(GSCID)以及用于选择第二阶段地址转换方案的 Mode 字段,tc 包含了很多转换控制相关的位,其中大部分控制在 hvisor 中未使用到,其中有效位需要设置为 1,以便后续进行更高级的功能扩展。设备目录表项结构如下:
#![allow(unused)] fn main() { #[repr(C)] struct DdtEntry{ tc: u64, iohgatp: u64, ta: u64, fsc: u64, msiptp: u64, msi_addr_mask: u64, msi_addr_pattern: u64, __rsv: u64, } }
当前 hvisor 仅支持单级设备目录表,实现时定义了 Lvl1DdtHw 结构体,以方便访问设备目录表表项,单级设备目录表可以支持 64 个 DMA 设备,占据一个物理页,结构如下:
#![allow(unused)] fn main() { pub struct Lvl1DdtHw{ dc: [DdtEntry; 64], } }
实现时定义了 Iommu 结构体,作为 IOMMU 更高级的抽象,其中 base 为 IommuHw 的基地址,即 IOMMU 的物理地址,可以借助其访问物理 IOMMU,ddt 为设备目录表,需要在 IOMMU 初始化时分配物理页,实现为支持单级设备目录表,故仅需一个物理页即可,定义如下:
#![allow(unused)] fn main() { pub struct Iommu{ pub base: usize, pub ddt: Frame, // Lvl1 DDT -> 1 phys page } }
IOMMU 的设备目录表和翻译的页表是存储在内存中的,需要根据实际所需进行分配,即要在 new 时分配设备目录表的内存。除此之外,在设备目录表中添加设备表项是一项非常重要的内容,因为 DMA 设备进行 DMA 操作,第一步即是从设备目录表中查找翻译需要的页表等信息,然后 IOMMU 根据页表相关的信息进行翻译,需要填充 tc、iohgatp 等内容,实现如下:
#![allow(unused)] fn main() { impl Iommu { pub fn new(base: usize) -> Self{ Self { base: base, ddt: Frame::new_zero().unwrap(), } } pub fn iommu(&self) -> &mut IommuHw{ unsafe { &mut *(self.base as *mut _) } } pub fn dc(&self) -> &mut Lvl1DdtHw{ unsafe { &mut *(self.ddt.start_paddr() as *mut _)} } pub fn rv_iommu_init(&mut self){ self.iommu().rv_iommu_init(self.ddt.start_paddr()); } pub fn rv_iommu_add_device(&self, device_id: usize, vm_id: usize, root_pt: usize){ // only support 64 devices if device_id > 0 && device_id < 64{ // configure DC let tc: u64 = 0 | RV_IOMMU_DC_VALID_BIT as u64 | 1 << 4; self.dc().dc[device_id].tc = tc; let mut iohgatp: u64 = 0; iohgatp |= (root_pt as u64 >> 12) & RV_IOMMU_DC_IOHGATP_PPN_MASK as u64; iohgatp |= (vm_id as u64) & RV_IOMMU_DC_IOHGATP_GSCID_MASK as u64; iohgatp |= RV_IOMMU_IOHGATP_SV39X4 as u64; self.dc().dc[device_id].iohgatp = iohgatp; self.dc().dc[device_id].fsc = 0; info!("{:#x}", &mut self.dc().dc[device_id] as *mut _ as usize); info!("RV IOMMU: Write DDT, add decive context, iohgatp {:#x}", iohgatp); } else{ info!("RV IOMMU: Invalid device ID: {}", device_id); } } } }
由于 hvisor 支持 RISC-V 的 IOMMU 与 Arm 的 SMMUv3,实现时封装了两个供外部调用的接口,分别为 iommu_init 与 iommu_add_device,这两个函数与 Arm 架构下的公共调用接口的函数名与参数均一致,实现如下:
#![allow(unused)] fn main() { // alloc the Fram for DDT & Init pub fn iommu_init() { let iommu = Iommu::new(0x10010000); IOMMU.call_once(|| RwLock::new(iommu)); rv_iommu_init(); } // every DMA device do! pub fn iommu_add_device(vm_id: usize, device_id: usize, root_pt: usize){ info!("RV_IOMMU_ADD_DEVICE: root_pt {:#x}, vm_id {}", root_pt, vm_id); let iommu = iommu(); iommu.write().rv_iommu_add_device(device_id, vm_id, root_pt); } }
X86_64 架构下的 IOMMU
DMA
DMA 是一种允许设备绕过 CPU 直接与内存交换数据的技术。在传统的数据传输方案中,设备需要通过中断请求 CPU 介入,从而完成数据的搬运。这种方式在处理大规模数据时会持续占用 CPU 资源,使得系统整体效率比较低下。DMA 技术通过引入专用的 DMA 控制器,使设备可以直接访问物理内存,从而显著提升传输效率。DMA 虚拟化通常用于设备直通的情形。当一个支持 DMA 的物理设备被分配给 guest OS 时,guest OS 提供给设备的内存地址均为 gPA。只有将 gPA 转化为 hPA 后,设备才能进行正确的 DMA 访问。负责进行 gPA 到 hPA 地址转换的硬件被称为输入输出内存管理单元(input–output memory management unit,IOMMU)。在启用 IOMMU 后,guest OS 可以继续使用 gPA 向设备传递地址信息,而 IOMMU 会在设备发起 DMA 操作时自动完成地址转换,确保 DMA 访问的正确性。在 Intel x86 架构中,IOMMU 的功能由 VT-d(Virtualization Technology for Direct I/O)硬件单元提供支持。
Hvisor 的 IOMMU 实现
Hvisor 使用 VT-d 实现了基于硬件的 DMA 虚拟化,从而支持 PCI 设备的直接内存访问。当宿主机启动时,BIOS 会检测 VT-d 硬件单元的存在并为其分配对应的地址空间,同时在 ACPI 表的 DMAR 子表(DMA remapping reporting table)中提供 VT-d 的硬件信息,例如寄存器基地址以及 VT-d 支持设备的 BDF 号。
DMA 虚拟化的核心在于将设备用于访存的 gPA 转换为 hPA。这一过程使用的页表结构与 EPT 完全一致,因此可以直接复用。然而,设备所属的 zone 不同,使用的 EPT 也不同,需要另一个类似页表的结构,将设备的 BDF 号映射到对应 EPT 的 hPA。VT-d 从硬件层面提供了对于此结构的支持:Hvisor 需要预先构建一个 4KB 大小的根表(root table),其中包含 256 个表项。每个表项对应一个 bus 号,并记录了该 bus 所对应的 4KB 上下文表(context table)的 hPA。而每个上下文表同样包含 256 个表项,每个表项对应一个 BDF 号,表项内记录了该 BDF 号对应 PCI 设备所使用 EPT 的 hPA。PCI 设备发起的 DMA 请求会包含 BDF 号作为索引,VT-d 使用根表和上下文表找到对应的 EPT 后,自动完成 gPA 到 hPA 的转换。
在 QEMU 中启用 VT-d 可以参见:QEMU Features/VT-d
Virtio
注意,本文档主要介绍Virtio如何在hvisor中实现,详细使用教程请参见hvisor-tool-README
Virtio简介
Virtio由Rusty Russell于2008年提出,是一个旨在提高设备性能, 统一各种半虚拟设备方案的设备虚拟化标准。目前,Virtio已囊括了十几种外设如磁盘、网卡、控制台、GPU等,同时许多操作系统包括Linux均已实现多种Virtio设备的前端驱动程序。因此虚拟机监控器只需实现Virtio后端设备,便可直接允许Linux等已实现Virtio驱动的虚拟机使用Virtio设备。
Virtio协议定义了一组半虚拟IO设备的驱动接口,规定虚拟机的操作系统需要实现前端驱动,Hypervisor需要实现后端设备,虚拟机和Hypervisor之间通过数据面接口、控制面接口进行通信和交互。

数据面接口
数据面接口(Data plane)是指驱动和设备之间进行IO数据传输的方式。对于Virtio,数据面接口是指驱动和设备之间的一片共享内存Virtqueue。Virtqueue是Virtio协议中一个重要的数据结构,是Virtio设备进行批量数据传输的机制和抽象表示,用于驱动和设备之间执行各种数据传输操作。Virtqueue包含三大组成部分:描述符表、可用环和已用环,其作用分别是:
-
描述符表(Descriptor Table):是以描述符为元素的数组。每个描述符包含4个字段:addr、len、flag、next。描述符可以用来表示一段内存缓冲区的地址(addr)、大小(len)和属性(flag),内存缓冲区中可以包含IO请求的命令或数据(由Virtio驱动填写),也可以包含IO请求完成后的返回结果(由Virtio设备填写)。描述符可以根据需要由next字段链接成一个描述符链,一个描述符链表示一个完整的IO请求或结果。
-
可用环(Available Ring):是一个环形队列,队列中的每个元素表示Virtio驱动发出的IO请求在描述符表中的索引,即每个元素指向一条描述符链的起始描述符。
-
已用环(Used Ring):是一个环形队列,队列中的每个元素表示Virtio设备完成IO请求后,写入的IO结果在描述符表中的索引。

因此利用这三个数据结构就可以完整地描述驱动和设备之间进行IO数据传输请求的命令、数据和结果。Virtio驱动程序负责分配Virtqueue所在的内存区域,并将其地址分别写入对应的MMIO控制寄存器中告知Virtio设备,这样设备获取到三者的内存地址后,便可与驱动通过Virtqueue进行IO传输。
控制面接口
控制面接口(Control Plane)是指驱动发现、配置和管理设备的方式,在hvisor中,Virtio的控制面接口主要是指基于内存映射的MMIO寄存器。操作系统首先通过设备树探测基于MMIO的Virtio设备,并通过读写这些内存映射的控制寄存器,便可以与设备进行协商、配置和通知。其中较为重要的几个寄存器为:
-
QueueSel:用于选择当前操作的Virtqueue。一个设备可能包含多个Virtqueue,驱动通过写该寄存器指示它在操作哪个队列。
-
QueueDescLow、QueueDescHigh:用于指示描述符表的中间物理地址IPA。驱动写这两个32位寄存器告知设备描述符表的64位物理地址,用于建立共享内存。
-
QueueDriverLow、QueueDriverHigh:用于指示可用环的中间物理地址IPA。
-
QueueDeviceLow、QueueDeviceHigh:用于指示已用环的中间物理地址IPA。
-
QueueNotify:驱动写该寄存器时,表示Virtqueue中有新的IO请求需要处理。
除了控制寄存器外,每个设备所在的MMIO内存区域还包含一个设备配置空间。对于磁盘设备,配置空间会指示磁盘的容量和块大小;对于网络设备,配置空间会指示设备的MAC地址和连接状态。对于控制台设备,配置空间提供控制台大小信息。
对于Virtio设备所在的MMIO内存区域,Hypervisor不会为虚拟机进行第二阶段地址翻译的映射。当驱动读写这片区域时,会因缺页异常发生VM Exit,陷入Hypervisor,Hypervisor根据导致缺页异常的访问地址即可确定驱动访问的寄存器,并做出相应处理,例如通知设备进行IO操作。处理完成后,Hypervisor通过VM Entry返回虚拟机。
Virtio设备的IO流程
一个运行在虚拟机上的用户进程,从发出IO操作,到获得IO结果,大致可以分为以下4步:
- 用户进程发起IO操作,操作系统内核中的Virtio驱动程序收到IO操作命令后,将其写入Virtqueue,并写QueueNotify寄存器通知Virtio设备。
- 设备收到通知后,通过解析可用环和描述符表,得到具体的IO请求及缓冲区地址,并进行真实的IO操作。
- 设备完成IO操作后,将结果写入已用环。如果驱动程序采用轮询已用环的方式等待IO结果,那么驱动可以立即收到结果信息;否则,则需要通过中断通知驱动程序。
- 驱动程序从已用环中得到IO结果,并返回到用户进程。
Virtio后端机制的设计与实现
hvisor中的Virtio设备遵循Virtio v1.2协议进行设计和实现。为了在保证hvisor轻量的情况下维持设备较好的性能,Virtio后端的两个设计要点为:
-
采用微内核的设计思想,将Virtio设备的实现从Hypervisor层移到管理虚拟机用户态。管理虚拟机运行Linux操作系统,称为Root Linux。物理磁盘和网卡等设备会直通给Root Linux,而Virtio设备会作为Root Linux上的守护进程,为其他虚拟机(Non Root Linux)提供设备模拟。这样可以保证Hypervisor层的轻量性,便于形式化验证。
-
位于其他虚拟机上的Virtio驱动程序和位于Root Linux上的Virtio设备之间,直接通过共享内存进行交互,共享内存区域存放交互信息,称为通信跳板,并采用生产者消费者模式,由Virtio设备后端和Hypervisor进行共享。这样可以减小驱动和设备之间交互的开销,提升设备的性能。
根据以上两个设计要点,Virtio后端设备的实现将分为通信跳板、Virtio守护进程、内核服务模块三个部分:

通信跳板
为了实现分布在不同虚拟机上的驱动和设备之间的高效交互,本文设计了一个通信跳板作为驱动和设备传递控制面交互信息的桥梁,它本质上是一片共享内存区域,包含2个环形队列:请求提交队列和请求结果队列, 分别存放由驱动发出的交互请求和设备返回的结果。两个队列位于Hypervisor与Virtio守护进程共享的内存区域中,并采用生产者消费者模型,Hypervisor作为请求提交队列的生产者和请求结果队列的消费者, Virtio守护进程作为请求提交队列的消费者和请求结果队列的生产者。这样就便于Root Linux和其他虚拟机之间传递Virtio控制面交互的信息。需要注意的是,请求提交队列和请求结果队列与Virtqueue并不相同。Virtqueue是驱动和设备之间的数据面接口,用于数据传输,本质上包含了数据缓冲区的地址、结构等信息。而通信跳板则是用于驱动和设备之间的控制面进行交互和通信。

- 通信跳板结构体
通信跳板由结构体virtio_bridge表示,其中req_list为请求提交队列,res_list和cfg_values共同组成请求结果队列。device_req结构体表示驱动发往设备的交互请求,device_res结构体表示设备要注入的中断信息,用于通知虚拟机驱动程序IO操作已完成。
// 通信跳板结构体:
struct virtio_bridge {
__u32 req_front;
__u32 req_rear;
__u32 res_front;
__u32 res_rear;
// 请求提交队列
struct device_req req_list[MAX_REQ];
// res_list、cfg_flags、cfg_values共同组成请求结果队列
struct device_res res_list[MAX_REQ];
__u64 cfg_flags[MAX_CPUS];
__u64 cfg_values[MAX_CPUS];
__u64 mmio_addrs[MAX_DEVS];
__u8 mmio_avail;
__u8 need_wakeup;
};
// 驱动发往设备的交互请求
struct device_req {
__u64 src_cpu;
__u64 address; // zone's ipa
__u64 size;
__u64 value;
__u32 src_zone;
__u8 is_write;
__u8 need_interrupt;
__u16 padding;
};
// 设备要注入的中断信息
struct device_res {
__u32 target_zone;
__u32 irq_id;
};
- 实现约束
当前实现中,通信跳板的环形队列长度 MAX_REQ 为 32, 并且要求 MAX_REQ 为 2 的幂,以便通过位运算完成取模和回绕。每个 Non Root 虚拟机最多支持 MAX_DEVS 为 8 个 Virtio MMIO 设备(例如 net/console/blk/gpu 的组合,按配置创建)。
在请求语义上,写 QueueNotify 寄存器属于数据面通知请求(need_interrupt 为 1),Hypervisor 不会阻塞等待返回值,而是立即返回虚拟机,由后端设备在完成数据处理后通过中断通知前端驱动;除 QueueNotify 之外的寄存器读写属于控制面请求(need_interrupt 为 0),陷入 Hypervisor 的 CPU 会阻塞等待后端写回 cfg_values/cfg_flags 后再返回虚拟机。
请求提交队列
请求提交队列,用于驱动向设备传递控制面的交互请求。当驱动读写Virtio设备的MMIO内存区域时,由于预先Hypervisor不为这段内存区域进行第二阶段地址映射,因此执行驱动程序的CPU会收到缺页异常,陷入Hypervisor。Hypervisor会将当前CPU编号、缺页异常的地址、地址宽度、要写入的值(如果是读则忽略)、虚拟机ID、是否为写操作等信息组合成名为device_req的结构体,并将其加入到请求提交队列req_list,这时监视请求提交队列的Virtio守护进程就会取出该请求进行处理。
为了方便Virtio守护进程和Hypervisor之间基于共享内存的通信,请求提交队列req_list采用环形队列的方式实现,队头索引req_front仅由Virtio进程取出请求后更新,队尾索引req_rear仅由Hypervisor放入请求后更新。如果队头和队尾索引相等,则表示队列为空;如果队尾索引加1并取模后与队头索引相等,则表示队列已满,再加入请求时驱动需要原地阻塞,等待队列可用。为了保证Hypervisor和Virtio进程对共享内存的实时观察以及互斥访问,Hypervisor每次向队列增加请求后,需要执行写内存屏障,再更新队尾索引,保证Virtio进程观察到队尾索引更新时,可以正确获取队列中的请求;Virtio守护进程从队列中取出请求后,需要执行写内存屏障,保证Hypervisor可立刻观察到队头索引的更新。通过这种生产者消费者模型及环形队列的方式,加上必要的内存屏障,就解决了在不同特权级下共享内存的互斥问题。由于多虚拟机情况下可能有多个CPU同时向请求提交队列加入请求,因此CPU需要首先获取互斥锁,才能操作请求提交队列;而Virtio守护进程只有主线程操作请求提交队列,因此无需加锁。这样就解决了同一特权级下共享内存的互斥问题。
请求结果队列
当Virtio守护进程完成请求的处理后,会将与结果相关的信息放入请求结果队列,并通知驱动程序。为了提升通信效率,根据Virtio交互信息的分类,请求结果队列分为了两个子队列:
- 数据面结果子队列
数据面结果队列,由res_list结构体表示,用于存放注入中断的信息。当驱动程序写设备内存区域的Queue Notify寄存器时,表示可用环有新的数据,需要设备进行IO操作。由于IO操作耗时过长,Linux为了避免不必要的阻塞,提高CPU利用率,要求Hypervisor将IO请求提交给设备后,CPU需要立刻从Hypervisor返回到虚拟机,执行其他任务。这要求设备在完成IO操作后通过中断通知虚拟机。因此Virtio进程完成IO操作并更新已用环后,会将设备的中断号irq_id和设备所属的虚拟机ID组合成device_res结构体,加入到数据面结果子队列res_list中,并通过ioctl和hvc陷入到Hypervisor。数据面结果队列res_list类似于请求提交队列,是一个环形队列,通过队头索引res_front和队尾索引res_rear可确定队列长度。Hypervisor会从res_list中取出所有元素,并将其加入到中断注入表VIRTIO_IRQS。中断注入表是一个基于B树的键值对集合,键为CPU编号,值为一个数组,数组的第0个元素表示该数组的有效长度,后续的各个元素表示要注入到本CPU的中断。为了防止多个CPU同时操作中断注入表,CPU需要首先获取全局互斥锁才能访问中断注入表。通过中断注入表,CPU可以根据自身CPU编号得知需要为自己注入哪些中断。之后Hypervisor会向这些需要注入中断的CPU发送IPI核间中断,收到核间中断的CPU就会遍历中断注入表,向自身注入中断。下图描述了整个过程,图中黑色实心三角箭头表示运行其他虚拟机CPU执行的操作,黑色普通箭头表示运行Root Linux的CPU执行的操作。

- 控制面结果子队列
控制面结果队列,由cfg_values和cfg_flags两个数组共同表示,数组索引为CPU编号,即每个CPU都唯一对应两个数组的同一个位置。cfg_values用于存放控制面接口交互的结果,cfg_flags用于指示设备是否完成控制面交互请求。当驱动程序读写设备内存区域的寄存器时(除Queue Notify寄存器),发出配置和协商相关的控制面交互请求,当该交互请求加入到请求提交队列后,由驱动陷入到Hypervisor的CPU需要等待结果返回后才能回到虚拟机。由于Virtio守护进程无需对这种请求进行IO操作,只需查询相关信息,因此可以迅速完成请求的处理,且无需更新已用环。完成请求后,守护进程会根据驱动的CPU编号id将结果值写入cfg_values[id](对于读请求),并执行写内存屏障,随后递增cfg_flags[id],再执行第二次写内存屏障,保证驱动侧CPU观察到cfg_flags[id]变化时,cfg_values[id]已保存正确的结果值。驱动侧的CPU观察到cfg_flags[id]改变时,便可确定设备已返回结果,直接从cfg_values[id]取出值并返回到虚拟机即可。这样Virtio设备就可以避免执行ioctl和hvc,造成不必要的CPU上下文切换,从而提升设备的性能。下图描述了整个过程,图中黑色实心三角箭头表示运行其他虚拟机的CPU执行的操作,黑色普通箭头表示运行Root Linux的CPU执行的操作。

内核服务模块
由于位于Root Linux用户态的Virtio守护进程需要与hvisor进行通信,因此本文将Root Linux中的内核模块hvisor.ko作为通信的桥梁。该模块除了被命令行工具使用外,还承担了如下工作:
- 在Virtio设备初始化时,为Virtio守护进程和Hypervisor之间建立通信跳板所在的共享内存区域。
在Virtio守护进程初始化时,会通过ioctl请求内核模块分配通信跳板所在的共享内存,此时内核模块会通过内存分配函数__get_free_pages分配一页连续的物理内存作为共享内存,并通过SetPageReserved函数设置页面属性为保留状态,避免因Linux的页面回收机制导致该页面被交换到磁盘。之后,内核模块需要让Virtio守护进程和Hypervisor均能获取到这片内存。对于Hypervisor,内核模块会执行hvc通知Hypervisor,并将共享内存的物理地址作为参数传递。对于Virtio守护进程,进程会对/dev/hvisor调用mmap,内核模块会在hvisor_map函数中将共享内存映射到Virtio进程的一片空闲的虚拟内存区域,该区域的起始地址会作为mmap的返回值返回。
-
当Virtio后端设备需要为其他虚拟机注入设备中断时,会通过ioctl通知内核模块,内核模块会通过hvc命令向下调用Hypervisor提供的系统接口,通知Hypervisor进行相应的操作。
-
唤醒Virtio守护进程。
当驱动访问设备的 MMIO 区域时,会陷入 EL2,进入 mmio_virtio_handler 函数。该函数会根据通信跳板中的 need_wakeup 标志位判断是否需要唤醒 Virtio 守护进程。如果标志位为 1, 则向 Root Linux 的第 0 号 CPU 发送 event id 为 IPI_EVENT_WAKEUP_VIRTIO_DEVICE 的 SGI 中断,0 号 CPU 收到 SGI 中断后,会陷入 EL2,并向自身注入 Root Linux 设备树中 hvisor_virtio_device 节点的中断号。
当 0 号 CPU 返回虚拟机后,会收到注入到自身的中断并进入内核服务模块提前注册的中断处理函数。当前实现中,内核服务模块通过 eventfd 唤醒用户态 Virtio 守护进程:守护进程在初始化阶段将一个 eventfd 通过 ioctl 注册到内核模块中,随后在主循环里使用 epoll_wait 阻塞等待该 eventfd 的可读事件;当内核模块收到唤醒中断后,会对该 eventfd 进行信号通知,使守护进程从 epoll_wait 中被唤醒并开始轮询请求提交队列。守护进程在进入轮询/消费请求前会将 need_wakeup 置为 0, 避免后续重复唤醒。
Virtio守护进程
为了保证Hypervisor的轻量,本文没有采用传统的Virtio设备实现方式,将其实现在Hypervisor层,而是将其移动到了Root Linux的用户态,作为守护进程提供设备模拟服务。守护进程包含两个部分,分发器和各种Virtio设备。其中分发器负责轮询请求提交队列,当队列不为空时取出交互请求并根据类型分发给对应的后端设备进行处理。Virtio设备的实现均遵循Virtio规范,控制面采用MMIO方式呈现, 数据面通过VirtQueue与其他客户机驱动进行数据传输。当守护进程完成一个交互请求的处理后,会将结果信息加入请求结果队列,并通过ioctl通知内核服务模块。

hvisor在启动后,会将物理设备如磁盘、网卡、串口以直通的形式提供给Root Linux。Virtio守护进程最终会操作这些真实设备进行IO操作。具体而言,守护进程中的每个Virtio磁盘设备会绑定一个物理磁盘上的磁盘镜像文件,该镜像作为Virtio磁盘的存储介质,所有对Virtio磁盘的IO操作最终都会对应到这个磁盘镜像。每个Virtio网络设备都会绑定一个Tap设备,由网桥设备连接所有Tap设备与真实网卡,从而与外网进行通信。每个Virtio控制台设备则会绑定一个伪终端,由Root Linux的控制台与用户交互。
- 休眠与唤醒机制
为了避免分发器持续轮询造成的 CPU 占用率过高的问题,本文还对守护进程实现了休眠机制。当分发器轮询请求提交队列时,发现队列一段时间内一直为空,表明后续可能很长一段时间都没有新的请求了,此时进入休眠模式,阻塞在 epoll_wait 上等待内核模块通过 eventfd 发起唤醒通知。当 Virtio 驱动向请求提交队列提交新的请求时,如果发现分发器处于休眠状态,则通过中断链路触发内核模块对 eventfd 进行通知,唤醒分发器线程,使其进入轮询状态。
- event monitor线程
为了便于实现Virtio net和console设备,需要一个独立的线程监视tap设备和PTY slave设备的可读事件,因此Virtio守护进程启动时,会启动一个名为event monitor的线程,通过epoll监控这些设备,当发现设备可读时,会调用提前注册的处理函数,进行处理。
Virtio Block
Virtio磁盘设备的实现遵循Virtio规范约定,采用MMIO的设备访问方式供其他虚拟机发现和使用。目前支持VIRTIO_BLK_F_SEG_MAX、VIRTIO_BLK_F_SIZE_MAX、VIRTIO_F_VERSION_1、VIRTIO_RING_F_INDIRECT_DESC和VIRTIO_RING_F_EVENT_IDX五种特性。
Virtio设备的顶层描述——VirtIODevice
一个Virtio设备由VirtIODevice结构体表示,该结构体包含 Virtqueue 的个数 vqs_len、所属的虚拟机 ID、设备中断号 irq_id、MMIO 区域的起始地址 base_addr、MMIO 区域长度 len、设备类型 type、部分由设备保存的 MMIO 寄存器 regs、Virtqueue 数组 vqs、指向描述特定设备信息的指针 dev 等信息。通过这些信息,可以完整描述一个Virtio设备。
// The highest abstract representations of virtio device
struct VirtIODevice {
uint32_t vqs_len; // Number of virtqueues
uint32_t zone_id; // ID of the zone to which it belongs
uint32_t irq_id; // Device interrupt ID
uint64_t base_addr; // The virtio device's base address in non-root zone
uint64_t len; // Length of the MMIO region
VirtioDeviceType type;
VirtMmioRegs regs; // MMIO registers of the device
VirtQueue *vqs; // Array of virtqueues of the device
void *dev; // Device-specific state (blk/net/console/gpu)
void (*virtio_close)(struct VirtIODevice *vdev);
bool activated;
};
typedef struct VirtMmioRegs {
uint32_t device_id;
uint32_t dev_feature_sel;
uint32_t drv_feature_sel;
uint32_t queue_sel;
uint32_t interrupt_status;
// interrupt_count doesn't exist in virtio specification,
// only used for ensuring the correctness of interrupt_status.
uint32_t interrupt_count;
uint32_t status;
uint32_t generation;
uint64_t dev_feature;
uint64_t drv_feature;
} VirtMmioRegs;
Virtio Block设备的描述信息
对于Virtio磁盘设备,VirtIODevice中type字段为VirtioTBlock,vqs_len为1,表示只有一个Virtqueue,dev指针指向描述磁盘设备具体信息的virtio_blk_dev结构体。virtio_blk_dev中config用来表示设备的数据容量和一次数据传输中最大的数据量,img_fd为该设备打开的磁盘镜像的文件描述符,tid、mtx、cond用于工作线程,procq为工作队列,closing用来指示工作线程何时关闭。virtio_blk_dev和blkp_req结构体的定义见图4.6。
typedef struct virtio_blk_dev {
BlkConfig config;
int img_fd;
// describe the worker thread that executes read, write and ioctl.
pthread_t tid;
pthread_mutex_t mtx;
pthread_cond_t cond;
TAILQ_HEAD(, blkp_req) procq;
int close;
} BlkDev;
// A request needed to process by blk thread.
struct blkp_req {
TAILQ_ENTRY(blkp_req) link;
struct iovec *iov;
int iovcnt;
uint64_t offset;
uint32_t type;
uint16_t idx;
};
Virtio Block设备工作线程
每个Virtio磁盘设备,都拥有一个工作线程和工作队列。工作线程的线程ID保存在virtio_blk_dev中的tid字段,工作队列则是procq。工作线程负责进行数据IO操作及调用中断注入系统接口。它在Virtio磁盘设备启动后被创建,并不断查询工作队列中是否有新的任务,如果队列为空则等待条件变量cond,否则处理任务。
当驱动写磁盘设备MMIO区域的QueueNotify寄存器时,表示可用环中有新的IO请求。Virtio磁盘设备(位于主线程的执行流)收到该请求后,首先会读取可用环得到描述符链的第一个描述符,第一个描述符指向的内存缓冲区包含了IO请求的类型(读/写)、要读写的扇区编号,之后的描述符指向的内存缓冲区均为数据缓冲区,对于读操作会将读到的数据存入这些数据缓冲区,对于写操作则会从数据缓冲区获取要写入的数据,最后一个描述符对应的内存缓冲区(结果缓冲区)用于设备描述IO请求的完成结果,可选项有成功(OK)、失败(IOERR)、不支持的操作(UNSUPP)。 据此解析整个描述符链即可获得有关该IO请求的所有信息,并将其保存在blkp_req结构体中,该结构体中的字段iov表示所有数据缓冲区,offset表示IO操作的数据偏移量,type表示IO操作的类型(读/写),idx为描述符链的首描述符索引,用于更新已用环。随后设备会将blkp_req加入到工作队列procq中,并通过signal函数唤醒阻塞在条件变量cond上的工作线程。工作线程即可对任务进行处理。
工作线程获取到任务后,会根据blkp_req指示的IO操作信息通过preadv和pwritev函数读写img_fd所对应的磁盘镜像。完成读写操作后,会首先更新描述符链的最后一个描述符,该描述符用于描述IO请求的完成结果,例如成功、失败、不支持该操作等。然后更新已用环,将该描述符链的首描述符写到新的表项中。随后进行中断注入,通知其他虚拟机。
工作线程的设立,可以有效地将耗时操作分散到其他CPU核上,提高主线程分发请求的效率和吞吐量,提升设备性能。
Virtio Network设备
Virtio网络设备,本质上是一块虚拟网卡。目前支持的特性包括VIRTIO_NET_F_MAC、VIRTIO_NET_F_STATUS、VIRTIO_F_VERSION_1、VIRTIO-RING_F_INDIRECT_DESC、VIRTIO_RING_F_EVENT_IDX。
Virtio Network设备的描述信息
对于Virtio网络设备,VirtIODevice中type字段为VirtioTNet,vqs_len为2,表示有2个Virtqueue,分别是Receive Queue接收队列和Transmit Queue发送队列,dev指针指向描述网络设备具体信息的virtio_net_dev结构体。Virtio_net_dev中config用来表示该网卡的MAC地址和连接状态,tapfd为该设备对应的Tap设备的文件描述符,rx_ready表示接收队列是否可用,event则用于接收报文线程通过epoll监视Tap设备的可读事件。
typedef struct virtio_net_dev {
NetConfig config;
int tapfd;
int rx_ready;
struct hvisor_event *event;
} NetDev;
struct hvisor_event {
void (*handler)(int, int, void *);
void *param;
int fd;
int epoll_type;
};
Tap设备和网桥设备
Virtio网络设备的实现基于两种Linux内核提供的虚拟设备:Tap设备和网桥设备。
Tap设备是一个由Linux内核用软件实现的以太网设备,通过在用户态读写Tap设备就可以模拟以太网帧的接收和发送。具体而言,当进程或内核执行一次对Tap设备的写操作时,就相当于将一个报文发送给Tap设备。对Tap设备执行一次读操作时,就相当于从Tap设备接收一个报文。这样,分别对Tap设备进行读和写操作,即可实现内核与进程之间报文的传递。
创建tap设备的命令为:ip tuntap add dev tap0 mode tap。该命令会创建一个名为tap0的tap设备。如果一个进程要使用该设备,需要首先打开/dev/net/tun设备,获得一个文件描述符tun_fd,并对其调用ioctl(TUNSETIFF),将进程链接到tap0设备上。之后tun_fd实际上就成为了tap0设备的文件描述符,对其进行读写和epoll即可。
网桥设备是一个Linux内核提供的功能类似于交换机的虚拟设备。当其他网络设备连接到网桥设备时,其他设备会退化成网桥设备的端口,由网桥设备接管所有设备的收发包过程。当其他设备收到报文时,会直接发向网桥设备,由网桥设备根据MAC地址转发到其他端口。因此,连接在网桥上的所有设备可以互通报文。
创建网桥设备的命令为:brctl addbr br0。将物理网卡eth0连接到br0上的命令为:brctl addif br0 eth0。将tap0设备连接到br0上的命令为:brctl addif br0 tap0。
在Virtio网络设备启动前,Root Linux需要提前在命令行中创建和启动tap设备和网桥设备,并将tap设备和Root Linux上的物理网卡分别与网桥设备进行连接。每个Virtio网络设备都需要连接一个tap设备,最终形成一张如下图的网络拓扑图。这样,Virtio网络设备通过读写tap设备,就可以与外网进行报文的传输了。

发送报文
Virtio网络设备的Transmit Virtqueue用于存放发送缓冲区。当设备收到驱动写QueueNotify寄存器的请求时,如果此时QueueSel寄存器指向Transmit Queue,表示驱动告知设备有新的报文要发送。Virtio-net设备会从可用环中取出描述符链,一个描述符链对应一个报文,其指向的内存缓冲区均为要发送的报文数据。报文数据包含2部分,第一部分为Virtio协议规定的报文头virtio_net_hdr_v1结构体,该结构体包含该报文的一些描述信息,第二部分为以太网帧。发送报文时只需将以太网帧的部分通过writev函数写入Tap设备,Tap设备收到该帧后会转发给网桥设备,网桥设备根据MAC地址会通过物理网卡转发到外网。
接收报文
Virtio网络设备在初始化时,会将Tap设备的文件描述符加到event monitor线程epoll实例的interest list中。event monito线程会循环调用epoll_wait函数,监视tap设备的可读事件,一旦发生可读事件,说明tap设备收到了内核发来的报文,epoll_wait函数返回,执行接收报文处理函数。处理函数会从Receive Virtqueue的可用环中取出一个描述符链,并读取tap设备,将数据写入描述符链指向的内存缓冲区中,并更新已用环。处理函数将重复该步骤,直到读取tap设备返回值为负并且errno为EWOULDBLOCK,表明tap设备已经没有新的报文,之后中断通知其他虚拟机收报文。
配置环境
磁盘镜像的要求
root Linux的磁盘镜像至少需要安装以下几个包:
apt-get install git sudo vim bash-completion \
kmod net-tools iputils-ping resolvconf ntpdate
linux Image的要求
在编译root linux的镜像前, 在.config文件中把CONFIG_IPV6和CONFIG_BRIDGE的config都改成y, 以支持在root linux中创建网桥和tap设备。例如:
cd linux
# 在.config中增加一行
CONFIG_BLK_DEV_RAM=y
# 修改.config的两个CONFIG参数
CONFIG_IPV6=y
CONFIG_BRIDGE=y
# 之后编译Linux即可
创建网络拓扑
使用Virtio net设备前,需要在root Linux中创建一个网络拓扑图,以便Virtio net设备通过Tap设备和网桥设备连通真实网卡。在root Linux中执行以下指令:
mount -t proc proc /proc
mount -t sysfs sysfs /sys
ip link set eth0 up
dhclient eth0
brctl addbr br0
brctl addif br0 eth0
ifconfig eth0 0
dhclient br0
ip tuntap add dev tap0 mode tap
brctl addif br0 tap0
ip link set dev tap0 up
便可创建tap0设备<-->网桥设备<-->真实网卡的网络拓扑。
测试Non root linux网络连通性
在non root linux的命令行执行,以启动网卡:
mount -t proc proc /proc
mount -t sysfs sysfs /sys
ip link set eth0 up
dhclient eth0
可以通过以下指令测试网络的连通:
curl www.baidu.com
ping www.baidu.com
Virtio Console
Virtio Console设备,本质上是一个虚拟控制台设备,用于数据的输入和输出,可作为虚拟终端供其他虚拟机使用。目前hvisor支持VIRTIO_CONSOLE_F_SIZE和VIRTIO_F_VERSION_1特性。
Virtio Console设备的描述信息
对于Virtio控制台设备,VirtIODevice结构体中type字段为VirtioTConsole,vqs_len为2,表示共有两个Virtqueue,分别是receive virtqueue接收队列和transmit virtqueue发送队列,用于端口0的接收数据和发送数据。dev指针指向描述控制台设备具体信息的virtio_console_dev结构体,该结构体中config用来表示该控制台的行数和列数,master_fd为该设备连接的伪终端主设备的文件描述符,rx_ready表示接收队列是否可用,event则用于event monitor线程通过epoll监视伪终端主设备的可读事件。
typedef struct virtio_console_dev {
ConsoleConfig config;
int master_fd;
int rx_ready;
struct hvisor_event *event;
} ConsoleDev;
伪终端
终端,本质上是一个输入输出设备。终端在计算机刚刚发展时,名叫电传打印机Teleprinter(TTY)。现在终端在计算机上成为了一种虚拟设备,由终端模拟程序连接显卡驱动和键盘驱动,实现数据的输入和输出。终端模拟程序有两种不同的实现形式,第一种是作为Linux的内核模块,并以/dev/tty[n]设备暴露给用户程序;第二种是作为一个应用程序,运行在Linux用户态,被称为伪终端(pseudo terminal, PTY)。
伪终端本身不是本文的重点,但伪终端使用的两种可互相传递数据设备——伪终端主设备PTY master和从设备PTY slave,被本文用来实现Virtio Console设备。
应用程序通过执行posix_openpt,可获取一个可用的PTY master,通过ptsname函数,可获取该PTY master对应的PTY slave。一个TTY驱动程序连接PTY master 和 PTY slave,会在 master 和 slave 之间复制数据。这样当程序向master(或slave)写入数据时,程序从slave(或master)可读到同样的数据。
Virtio Console总体设计
Virtio Console设备作为Root Linux上的一个守护进程,会在设备初始化过程中打开一个PTY master,并向日志文件中输出master对应的PTY slave的路径/dev/pts/x,供screen会话连接。同时Virtio守护进程中的event monitor线程会监视PTY slave的可读事件,以便PTY master及时获取到用户的输入数据。
当用户在Root Linux上执行screen /dev/pts/x时,会在当前终端上创建一个screen会话,该会话会连接PTY slave对应的设备 /dev/pts/x,并接管当前终端的输入和输出。Virtio Console设备的实现结构图如下图所示。

输入命令
当用户在键盘上输入命令时,输入的字符会通过终端设备传递给Screen会话,Screen会话会将字符写入PTY slave。event monitor线程通过epoll发现PTY slave可读时,会调用virtio_console_event_handler函数。该函数会读取PTY slave,并将数据写入Virtio Console设备的Receive Virtqueue中,并向对应的虚拟机发送中断。
对应的虚拟机收到中断后,会将收到的字符数据通过TTY子系统传递给Shell,交由Shell解释执行。
显示信息
当使用Virtio Console驱动的虚拟机要通过Virtio Console设备输出信息时,Virtio Console驱动会将要输出的数据写入Transmit Virtqueue中,并写MMIO区域的QueueNotify寄存器通知Virtio Console设备处理IO操作。
Virtio Console设备会读取Transmit Virtqueue,获取要输出的数据,并写入PTY master。Screen会话就会从PTY slave获取要输出的数据,并通过终端设备在显示器上显示输出信息。
由于
PTY master和PTY slave之间由TTY driver相连接,TTY driver包含一个line discipline,用于将PTY master写给PTY slave的数据回传给PTY master。由于我们不需要该功能,因此需通过函数cfmakeraw将line discipline功能关闭。
Virtio GPU
要使用hvisor-tool中的Virtio GPU设备,需要首先在host上安装libdrm,并进行一些相关的配置。
前置条件
- 安装libdrm
我们需要安装libdrm来编译Virtio-gpu,假设目标平台为arm64。
wget https://dri.freedesktop.org/libdrm/libdrm-2.4.100.tar.gz
tar -xzvf libdrm-2.4.100.tar.gz
cd libdrm-2.4.100
tips: 2.4.100以上的libdrm需要使用meson等进行编译,较为麻烦,https://dri.freedesktop.org/libdrm有更多版本。
# 安装到你的aarch64-linux-gnu编译器
./configure --host=aarch64-linux-gnu --prefix=/usr/aarch64-linux-gnu && make && make install
对于 loongarch64 需要使用:
./configure --host=loongarch64-unknown-linux-gnu --disable-nouveau --disable-intel --prefix=/opt/libdrm-install && make && sudo make install
- 配置Linux内核
Linux内核需要支持virtio-gpu和drm相关的驱动,具体来说需要在编译内核时启动以下选项
CONFIG_DRM=y
CONFIG_DRM_VIRTIO_GPU=y
有可能有其他GPU相关的驱动没有被编译到内核,这里需要根据具体设备编译,可以在编译时使用menuconfig来进行配置,具体在Device Drivers->Graphics support-> Direct Rendering Infrastructure(DRM),Graphics support条目下也有支持virtio-gpu相关的驱动,如果需要使用可以开启相关字段的编译,如Virtio GPU driver和DRM Support for bochs dispi vga interface
Graphics support条目的底部还有Bootup logo,启用该选项可以在启动时在显示屏幕上看到CPU核数个数的Linux logo
- 为Root Linux探测物理GPU设备
要在Root Linux中探测物理GPU设备,你需要编辑hvisor/src/platform目录下的文件,以便在PCI总线上探测GPU设备。需要将Virtio-gpu设备的中断号添加到ROOT_ZONE_IRQS中。例如:
pub const ROOT_PCI_DEVS: [u64; 3] = [0, 1 << 3, 6 << 3];
启动Root Linux后,你可以通过运行dmesg | grep drm或lspci来检查你的 GPU 设备是否正常工作。若/dev/dri下出现card0和renderD128等文件,说明成功识别到图形设备,并且该设备可以使用drm操控
- 查看真实GPU设备是否受支持
如果要移植Virtio-GPU到其他平台,需要确保该平台上的物理GPU设备受drm框架支持。要查看 libdrm 支持的设备,可以安装libdrm-tests包,使用命令apt install libdrm-tests,然后运行modetest
- qemu启动参数
如果hvisor运行在qemu aarch64环境下,则需要qemu向root linux提供GPU设备。在qemu启动参数中加入:
QEMU_ARGS += -device virtio-gpu,addr=06,iommu_platform=on
QEMU_ARGS += -display sdl
同时确保启动参数中包含smmu的配置:
-machine virt,secure=on,gic-version=3,virtualization=on,iommu=smmuv3
-global arm-smmuv3.stage=2
PCIE Virtualization
Hvisor支持的pcie架构
ecam:qemu/x86往往采用该架构,pcie域地址直接映射到cpu域地址上;
dwc:部分arm64/riscv板卡采用designware core的ip核以实现pcie功能,pcie域地址通过atu映射到cpu域的特定地址上;
loongarch64:龙芯的pcie实现方式,部分设备和地址有特殊的处理方式;
概述
Hvisor pcie虚拟化支持将pcie总线的上的设备以设备粒度在各个zone间分配。其核心逻辑是将pcie系统中难以控制的在运行时确定的bdf,mem等信息在el2进行固化,在各个zone的内核访问pcie配置空间时用hvisor的模拟进行代替,并借助二阶段地址映射将大部分固定的资源直通给zone以保证pcie虚拟化的性能。对于部分复杂的pcie系统,pcie虚拟化支持direct模式,即让root linux对系统资源进行初始化,以减轻板卡适配的负担。
Hvisor pcie虚拟化也支持创建虚拟pcie设备以实现自定义的功能。
pcie的具体实现
┌─────────────────────────────────────────────────────────┐
│ hvisor PCIe 虚拟化 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ ECAM │ │ DWC PCIe │ │ LoongArch64 │ │
│ │ Accessor │ │ Accessor │ │ Accessor │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │ │ │ │
│ └──────────────────┴──────────────────┘ │
│ │ │
│ ┌───────────▼───────────┐ │
│ │ PciConfigAccessor │ │
│ │ (Trait) │ │
│ └───────────┬───────────┘ │
│ │ │
│ ┌──────────────────────┼──────────────────────┐ │
│ │ │ │ │
│ ┌────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Enumerate │ │ ConfigSpace │ │ MMIO Handler │ │
│ └────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────┐│
│ │ GLOBAL_PCIE_LIST (global dev list) ││
│ │ BTreeMap<Bdf, ArcRwLockVirtualPciConfigSpace> ││
│ └─────────────────────────────────────────────────────┘│
│ │
│ ┌─────────────────────────────────────────────────────┐│
│ │ Zone.vpci_bus (Zone virt bus) ││
│ │ BTreeMap<Bdf, VirtualPciConfigSpace> ││
│ └─────────────────────────────────────────────────────┘│
└─────────────────────────────────────────────────────────┘
hvisor的pcie系统通过PciConfigAccessor为媒介实现3种不同访问方式的兼容,这里以ecam为例介绍通用的实现。
bdf重映射
因为linux访问pcie总线是按顺序访问的,如果分配的多个设备之间产生空隙,那么linux有时会认为该位置后没有已经没有其他设备不再继续访问,所以hvisor需要对分给同一zone的设备bdf进行重整。 重整规则如下: 1.如果设备的bus号增加,则vbus号自增1; 2.如果设备的function号不为0且function/vfunction为0的设备不属于zone,则vfunction为0;
设备枚举
在hvisor初始化时,会对pcie总线进行遍历,采用和linux类似的方式,确认总线上的设备类型及需要使用的mem资源(主要是bar),在完成设备资源的分配后,hvisor会将该设备添加到全局设备列表中供各个zone使用
设备分配
在设备分配之前,hvisor已经将所有的设备信息存储在全局的设备列表中。为了能够正常的让所有zone都能够访问所有可能的设备,hvisor不会将bridge类型的设备从全局设备列表中移除,以便其他zone建立pcie拓扑结构;对于其他类型的设备,当设备被分配给一个zone时,设备会从全局设备列表移除以保证设备功能的正常。
zone如何访问设备(mmio handler)
当zone访问pcie总线时,对于ecam来说,因为pcie总线的地址直接在cpu域展开,hvisor可以直接通过地址确认zone需要访问的设备bdf以确认设备的唯一身份,以此访问对应设备的配置空间。对于direct模式的pcie虚拟化来说,为了让root分配资源但不驱动设备,对于非root的设备,hvisor替换配置空间中的id和class等字段,让zone无法识别设备类型,使zone无法找到正确的设备驱动,但是设备的其他资源均能够正常访问,以此完成设备资源的分配。
BAR空间的管理
为了能够尽可能的进行设备直通,提高设备运行效率,hvisor采用二阶段地址映射的方式将bar等资源直通给zone。hvisor会在设备遍历阶段完成对资源的分配,写入设备的物理寄存器,当zone访问bar等资源时,不再修改物理寄存器,而是修改对应zone的页表,将地址映射到正确的资源位置。
Designware Core PCIE
本节描述了hvisor对于dwc pcie的适配
atu基础
对于dwc来说,cpu域与pcie域不直接映射,而是通过atu这一硬件进行访问转换。 单个atu的长度为0x200,其中0-0x100为outbound,0x100-0x200为inbound,分别代表了cpu域到pci域的访问与pci域到cpu域的访问。hvisor只管理outbound访问(从cpu侧访问)。 除了atu0会被复用以外,其他atu都是固定不变的,只在初始化时配置一次。atu0会被cfg0和cfg1复用,如果atu数量不足(在linux中表现为io_shared设置为1,则atu0还会被io类型的mem访问复用)。
atu的虚拟化实现
hvisor实际只对atu0进行较为复杂的管理,其他atu基本只会进行一次配置(禁止其他zone的重复配置并在软件查询atu数量时做出响应即可)。 hvisor在创建虚拟总线时为每条总线创建了虚拟atu0,zone对与atu0的访问会被hvisor截取,只有当hvisor发现对对应地址的访问即将进行时,atu0才会被真正写入。 为了避免多个zone交叉访问atu0产生异常,hvisor设置了一个自旋锁以保证访问顺序。
配置空间的访问
因为dwc从cpu侧观察,当产生mmio访问配置空间时,不管访问的是哪个设备,设备地址总是一致的,该地址实际由atu0的pci_addr决定映射到哪一设备。在每次zone访问对应的pci配置空间时,总是会先设置atu0再进行访问,所以hvisor会采用上一次写入atu0的pci_addr来作为需要访问的设备的唯一地址(实际上该地址和bdf可以直接相互转化),并在mmio访问时才真实写入atu0。
pcie其他空间的管理
dwc方式访问pcie时,每个bridge会从设备树允许的空间中申请自身及其下设备可以使用的bar空间,并记录为bar6-bar9。hvisor借助root linux对这些空间进行配置以简化自身的逻辑。当root linux配置相关bar寄存器时,hvisor会允许其修改对应的物理寄存器,同时将所有的bar空间写入root linux的页表中;non-root zone对这些空间的访问机制同ecam pcie,通过二阶段地址翻译进行。
Loongarch64 PCIE
本节描述了hvisor对于loongarch64 pcie的适配
地址访问
loongarch64 pcie与ecam pcie的主要不同在于,loongarch64采用了窗⼝映射的方式,mmio handler的地址必须加上⼀个前缀。hvisor使用HV_ADDR_PREFIX和LOONG_HT_PREFIX描述该地址前缀。
因为loongarch64部分驱动采用了写死的方式分配资源,所以hvisor使用dircet模式以支持相关资源的正确分配
配置空间地址组成
当hvisor解析zone传入的mmio handler地址时,loongarch64的pcie地址有自己独特的规则,规则如下
Type 0 format (Root Bus):
Bits 31-28: Offset[11:8]
Bits 27-16: Reserved (0)
Bits 15-11: Device Number
Bits 10-8: Function Number
Bits 7-0: Offset[7:0]
Type 1 format (Other Bus):
Bits 31-28: Offset[11:8]
Bits 27-16: Bus Number
Bits 15-11: Device Number
Bits 10-8: Function Number
Bits 7-0: Offset[7:0]
pcie配置
总线配置
不论是哪种访问pcie的方式,都需要配置ROOT_PCI_CONFIG 对于arm64/loongarch64/riscv来说,其值可以从设备树中直接获取 对于x86来说,通常从acpi mcfg表中获取信息 这里以从dts中获取信息为例
pub const ROOT_PCI_CONFIG: &[HvPciConfig] = &[
HvPciConfig {
ecam_base: 0x4010000000,
ecam_size: 0x10000000,
io_base: 0x3eff0000,
io_size: 0x10000,
pci_io_base: 0x0,
mem32_base: 0x10000000,
mem32_size: 0x2eff0000,
pci_mem32_base: 0x10000000,
mem64_base: 0x8000000000,
mem64_size: 0x8000000000,
pci_mem64_base: 0x8000000000,
bus_range_begin: 0,
bus_range_end: 0xff,
domain: 0x0,
}
];
// 这里只截取了dts中相关的配置
pcie@10000000 {
ranges = <0x1000000 0x00 0x00 0x00 0x3eff0000 0x00 0x10000
0x2000000 0x00 0x10000000 0x00 0x10000000 0x00 0x2eff0000
0x3000000 0x80 0x00 0x80 0x00 0x80 0x00>;
reg = <0x40 0x10000000 0x00 0x10000000>;
bus-range = <0x00 0xff>;
linux,pci-domain = <0x00>;
};
HvPciConfig 中的各个字段值通过解析设备树节点 pcie@10000000 中的属性来填写,对应关系如下:
ecam_base: 0x4010000000<=reg = <0x40 0x10000000 ...>ecam_size: 0x10000000<=reg中的size0x10000000io_base: 0x3eff0000<=ranges的io部分的cpu域的地址0x00 0x3eff0000io_size: 0x10000<=ranges的io部分的cpu域的size0x00 0x10000pci_io_base: 0x0<=ranges的io部分的pci域的地址0x00 0x00 0x00mem32与mem64实际与io相同,对于判断range中的字段类型可以参考相关解释bus_range_begin: 0<=bus-range = <0x00 0xff>的起始值bus_range_end: 0xff<=bus-range = <0x00 0xff>的结束值domain: 0x0<=linux,pci-domain = <0x00>,如果没有该字段可以启动系统后查看,如果只有一个pcie节点则domain一般为0
特别的
- 对于direct模式的pcie系统来说
mem32、mem64和io没有实际意义,可填0 - 对于loongarch64来说,不区分mem32和mem64,但是因为是direct模式,所以可不填
设备配置
ROOT_PCI_DEVS 定义了需要由 hvisor 进行虚拟化管理的 PCI 设备列表。
每个设备通过 pci_dev! 宏配置,包含以下字段:
domain: PCI 域号,与ROOT_PCI_CONFIG中的domain字段对应bus: PCI 总线号device: PCI 设备号function: PCI 功能号dev_type: 设备类型,VpciDevType::Physical表示物理直通设备,其他类型定义参考VpciDevType
对于 x86 ,需要配置 ROOT_PCI_MAX_BUS 来指定最大总线号。
dwc的特殊配置
对于使用 DWC PCIe 控制器的平台,除了需要配置 ROOT_PCI_CONFIG 外,还需要额外配置 ROOT_DWC_ATU_CONFIG 来指定 ATU 相关的参数。
HvDwcAtuConfig 中的各个字段值也通过解析设备树节点中的属性来填写,这里以 rk3568 为例,对应关系如下:
pub const ROOT_DWC_ATU_CONFIG: &[HvDwcAtuConfig] = &[
HvDwcAtuConfig {
ecam_base: 0x3c0400000,
dbi_base: 0x3c0400000,
dbi_size: 0x10000,
apb_base: 0xfe270000,
apb_size: 0x10000,
cfg_base: 0xf2000000,
cfg_size: 0x80000*2,
io_cfg_atu_shared: 0,
},
];
pcie@fe270000 {
reg = <0x03 0xc0400000 0x00 0x400000 0x00 0xfe270000 0x00 0x10000>;
reg-names = "pcie-dbi", "pcie-apb";
ranges = <0x800 0x00 0xf2000000 0x00 0xf2000000 0x00 0x100000 ...>;
num-viewport = <0x08>;
...
};
ecam_base: 0x3c0400000<=reg = <0x03 0xc0400000 ...>用于指示和 ROOT_PCI_CONFIG 中对应总线的联系,需要与其一一对应dbi_base: 0x3c0400000<= 从reg-names中发现该板卡的dbi为reg中的第一部分,所以从对应的区域获取地址,dbi一般用于root bus的访问dbi_size: 0x10000<= DBI 寄存器sizeapb_base: 0xfe270000<= 从reg-names中发现该板卡存在apb,所以根据对应信息填写,部分板卡该位置填充的值为cfg,需要注意甄别apb_size: 0x10000<= APB 寄存器sizecfg_base: 0xf2000000<= 在该板卡中,cfg为ranges中0x800类型的地址;部分板卡中cfg地址也是存储在reg中,用reg-names标识,需要注意甄别cfg_size: 0x80000*2<= cfg sizeio_cfg_atu_shared: 0<= 该值用于标识atu0是否被io访问共享,一般来说num-viewport >= 4时为 0,应与linux中的同名变量保持一致
虚拟pcie设备
hvisor支持的虚拟设备列表
添加新的设备
hvisor通过 VpciDeviceHandler 以支持自定义的虚拟pcie设备,目前已测试在ecam pcie系统中添加虚拟设备
pub trait VpciDeviceHandler: Sync + Send {
fn read_cfg(
&self,
dev: ArcRwLockVirtualPciConfigSpace,
offset: PciConfigAddress,
size: usize,
) -> HvResult<PciConfigAccessStatus>;
fn write_cfg(
&self,
dev: ArcRwLockVirtualPciConfigSpace,
offset: PciConfigAddress,
size: usize,
value: usize,
) -> HvResult<PciConfigAccessStatus>;
fn vdev_init(&self, dev: VirtualPciConfigSpace) -> VirtualPciConfigSpace;
}
添加新设备需要
- 在
VpciDevType中注册新的设备类型 - 为该设备类型实现
VpciDeviceHandler
hvisor实现了一个标准的设备StandardVdev供参考
hvisor管理工具
hvisor通过一个管理虚拟机Root Linux来管理整个系统。Root Linux通过一套管理工具为用户提供启动和关闭虚拟机、启动和关闭Virtio守护进程的服务。管理工具中,包含一个命令行工具和内核模块。其中命令行工具用于解析并执行用户输入的命令,内核模块用于命令行工具、Virtio守护进程与Hypervisor之间的通信。管理工具的仓库地址为:hvisor-tool。
启动虚拟机
用户输入以下命令,可以在Root Linux上为hvisor创建一个新的虚拟机。
./hvisor zone start [vm_name].json
命令行工具首先会解析[vm_name].json文件内容,将虚拟机配置写入zone_config结构体。并根据文件中指定的镜像和dtb文件,将其内容通过read函数读入临时内存。为了将镜像和dtb文件加载到指定的物理内存地址,hvisor.ko内核模块提供hvisor_map函数,可以将一片物理内存区域映射到用户态虚拟地址空间。
当命令行工具对/dev/hvisor执行mmap函数时,内核会调用hvisor_map函数,以实现用户虚拟内存到指定物理内存的映射。之后通过内存拷贝函数,即可将镜像和dtb文件的内容从临时内存移动到用户指定的物理内存区域。
加载好镜像后,命令行工具对/dev/hvisor调用ioctl,指定操作码为HVISOR_ZONE_START,之后内核模块会通过Hypercall通知Hypervisor,并传入zone_config结构体对象的地址,通知Hypervisor启动虚拟机。
关闭虚拟机
用户输入命令:
./hvisor shutdown -id [vm_id]
即可关闭ID为vm_id的虚拟机。该命令会对/dev/hvisor调用ioctl,指定操作码为HVISOR_ZONE_SHUTDOWN,之后内核模块会通过Hypercall通知Hypervisor,传入vm_id,通知Hypervisor关闭虚拟机。
启动Virtio守护进程
用户输入命令:
nohup ./hvisor virtio start [virtio_cfg.json] &
即可根据virtio_cfg.json中规定的Virtio设备信息,创建Virtio设备,并初始化相关的数据结构。目前支持三种Virtio设备的创建,包括Virtio-net、Virtio-block、Virtio-console设备。
由于命令行参数中包含nohup和&,该命令会以守护进程的形式存在,守护进程的所有输出被重定向到nohup.out。守护进程的输出包含六个等级,从低到高分别是LOG_TRACE, LOG_DEBUG, LOG_INFO,LOG_WARN,LOG_ERROR,LOG_FATAL。编译命令行工具时可指定LOG级别,例如LOG为LOG_INFO时,等于或高于LOG_INFO的输出将被记录到日志文件,而log_trace和log_debug将不会输出。
Virtio设备创建后,Virtio守护进程会轮询请求提交队列,获取其他虚拟机的Virtio请求。长时间没有请求时,会自动进入休眠状态。
关闭Virtio守护进程
用户输入命令:
pkill hvisor
即可关闭Virtio守护进程。Virtio守护进程在启动时,会注册SIGTERM信号的信号处理函数virtio_close。当执行pkill hvisor时,会向名为hvisor的进程发送信号SIGTERM,此时守护进程会执行virtio_close,回收资源,关闭各个子线程,最后推出
Hypercall说明
hvisor作为Hypervisor,向上层虚拟机提供hypercall处理机制。
虚拟机如何执行Hypercall
虚拟机通过执行指定的汇编指令,在Arm64为hvc,在riscv64为ecall。执行汇编指令时,传入的参数分别为:
- code:hypercall id,其范围和含义详见hvisor对hypercall的处理
- arg0:虚拟机要传递的第一个参数,类型为u64
- arg1:虚拟机要传递的第二个参数,类型为u64
例如,对于riscv linux:
#ifdef RISCV64
// according to the riscv sbi spec
// SBI return has the following format:
// struct sbiret
// {
// long error;
// long value;
// };
// a0: error, a1: value
static inline __u64 hvisor_call(__u64 code,__u64 arg0, __u64 arg1) {
register __u64 a0 asm("a0") = code;
register __u64 a1 asm("a1") = arg0;
register __u64 a2 asm("a2") = arg1;
register __u64 a7 asm("a7") = 0x114514;
asm volatile ("ecall"
: "+r" (a0), "+r" (a1)
: "r" (a2), "r" (a7)
: "memory");
return a1;
}
#endif
对于arm64 linux:
#ifdef ARM64
static inline __u64 hvisor_call(__u64 code, __u64 arg0, __u64 arg1) {
register __u64 x0 asm("x0") = code;
register __u64 x1 asm("x1") = arg0;
register __u64 x2 asm("x2") = arg1;
asm volatile ("hvc #0x4856"
: "+r" (x0)
: "r" (x1), "r" (x2)
: "memory");
return x0;
}
#endif /* ARM64 */
hvisor对hypercall的处理
当虚拟机执行hypercall后,CPU会进入hvisor指定的异常处理函数:hypercall。之后hvisor根据hypercall传入的参数code、arg0、arg1,继续调用不同的处理函数,分别为:
| code | 调用函数 | 参数说明 | 函数简介 |
|---|---|---|---|
| 0 | hv_virtio_init | arg0:共享内存起始地址 | 用于root zone初始化virtio跳板机制 |
| 1 | hv_virtio_inject_irq | 无 | 用于root zone将virtio设备中断发送给其他虚拟机 |
| 2 | hv_zone_start | arg0:虚拟机配置文件地址;arg1:配置文件大小 | 用于root zone启动一个虚拟机 |
| 3 | hv_zone_shutdown | arg0:要关闭的虚拟机id | 用于root zone关闭一个虚拟机 |
| 4 | hv_zone_list | arg0:表示虚拟机信息的数据结构地址;arg1:虚拟机信息的数量 | 用于root zone查看整个系统所有虚拟机信息 |
| 5 | hv_ivc_info | arg0:ivc信息的起始地址 | 用于一个zone查看自己所在的通信域信息 |
| 6 | hv_zone_config_check | arg0:magic_version,hvisor-tool的版本号所在地址(虚拟机物理地址) | 用于检查hvisor-tool和hvisor是否兼容,通过两者的版本号确定 |
| 20 | send_event | 无 | 向所有nonroot zone发送“清除中断注入位”IPI事件,停止对应CPU上的中断注入 |
| 86 | hv_virtio_get_irq | arg0:需要写入IRQ号的地址 | 用于root zone获取hvisor tool可用的IRQ号(仅x86_64使用) |
未来计划
- Support for Android
- Support for OpenHarmony
- Support for ARMv9
- Support for GICv4
- Support for Cache Coloring
- Support for SR-IOV
- Support for USB / NPU zoneU passthrough
- Support for Nvidia GPU zoneU passthrough
- Web Management tool
- Device Tree configuration tool
- Support for Nvidia Orin
- Support for Nvidia Thor
- Support for Raspberry Pi 5
- Support for IOMMU virtualization
- Support for PCIe bus virtualization
- Support for Clock Controller virtualization
- Support for pinctrl virtualization
- Support for booting zoneU / zoneR without zone0
- Formal verification of key components
贡献者列表
| 姓名 | github id | 单位 |
|---|---|---|
| 李昕昊 | @li041 | 哈尔滨工业大学(本科生) |
| 卢安来 | @agicy | 北京邮电大学(本科生) |
| 蔡蕾 | @162210107 | 南京航空航天大学(本科生) |
| 陈震雄 | @Crzax | 武汉大学(本科生) |
| 刘竞暄 | @PKTH-Jx | 清华大学(本科生), 北京大学(博士生) |
| 石全 | @Stone749990226 | 哈尔滨工业大学(深圳)(本科生), 北京大学(硕士生) |
| 刘骏 | @LiuJun5817 | 浙江大学(博士生) |
| 任航麒 | @ForeverYolo | 北京航空航天大学(本科生), 北京大学(硕士生) |
| 曾俊 | @ZZJJWarth | 华南理工大学(本科生),北京大学(硕士生) |
| 刘天弘 | @Solicey | 北京大学(本科生, 硕士生) |
| 李坤嵘 | @Misaka19986 | 电子科技大学(本科生) |
| 侯云龙 | @ohhhHwH | 北京大学(硕士生) |
| 程宏豪 | @CHonghaohao | 郑州大学(硕士生) |
| 包子旭 | @Baozixu99 | 河南理工大学(本科生), 西北工业大学(硕士生) |
| 陈林锟 | @Enquisitor-201 | 哈尔滨工业大学(深圳)(本科生), 北京大学(硕士生) |
| 陈星宇 | @dallasxy | 中科院计算所(硕士生) |
| 李国玮 | @kouweilee | 北京航空航天大学(本科生), 北京大学(硕士生) |
| 韩喻泷 | @enkerewpo | 西北工业大学(本科生), 北京大学(博士生) |
| 沈铭 | @BoneInscri | 杭州电子科技大学(本科生), 西北工业大学(硕士生) |
| 刘景宇 | @liulog | 华中科技大学(本科生), 中科院计算所(硕士生) |
| 徐仲锴 | @ZhongkaiXu | 中国矿业大学(北京)(本科生), 中科院计算所(硕士生) |
| 廖航 | @CarryLiao5959 | 北京大学(硕士生) |
| 李韶航 | @sanchezdorso | 武汉大学(本科生), 中科院计算所(硕士生) |
| 杨竣轶 | @comet959 | 中科院计算所(博士生) |
| 贾越凯 | @equation314 | 清华大学(博士生) |
| 丁韶峰 | @KarmaD7 | 清华大学(本科生) |
| 李柯越 | @likey99 | 中科院计算所(硕士生) |
| 汪文韬 | @Miaowulue | 北京大学(硕士生) |
| 龚天遥 | @FlowerBlackG | 同济大学(本科生), 上海交通大学(硕士生) |
| 封宇婷 | @MacixOwl | 西安交通大学(本科生), 上海交通大学(硕士生) |
项目相关信息
github地址: https://github.com/syswonder/hvisor
项目文档: https://hvisor.syswonder.org
邮件列表: hypervisor@syswonder.org
社区网站: https://syswonder.org
gitlink地址: https://gitlink.org.cn/syswonder/hvisor
许可证 License
hvisor 代码开源, 许可证是 木兰宽松许可证,第2版